Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Audio Strikes Back: Boosting Augmentations Towards An Efficient Audio Classification Network
Paper and Code
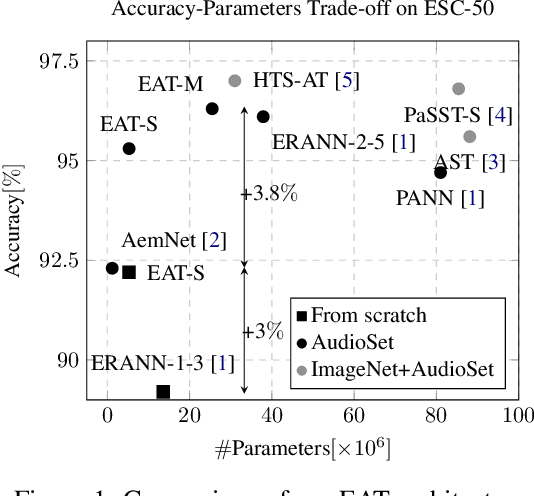

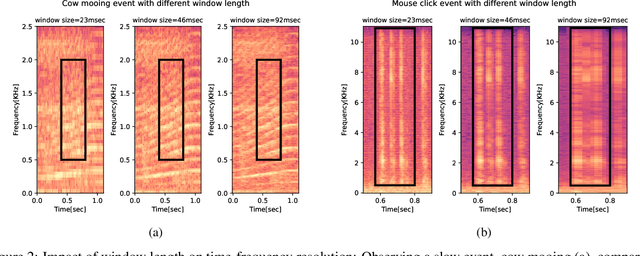
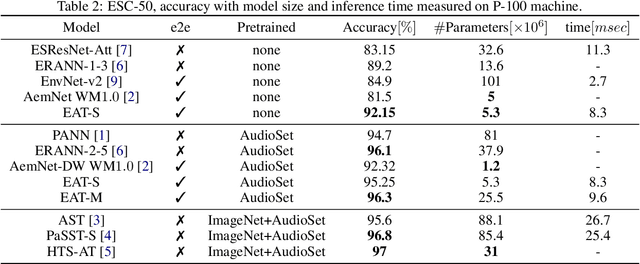
While efficient architectures and a plethora of augmentations for end-to-end image classification tasks have been suggested and heavily investigated, state-of-the-art techniques for audio classifications still rely on numerous representations of the audio signal together with large architectures, fine-tuned from large datasets. By utilizing the inherited lightweight nature of audio and novel audio augmentations, we were able to present an efficient end-to-end network with strong generalization ability. Experiments on a variety of sound classification sets demonstrate the effectiveness and robustness of our approach, by achieving state-of-the-art results in various settings. Public code will be available.
View paper on