 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating Text-to-Image Generative Bias across Indic Languages
Aug 01, 2024


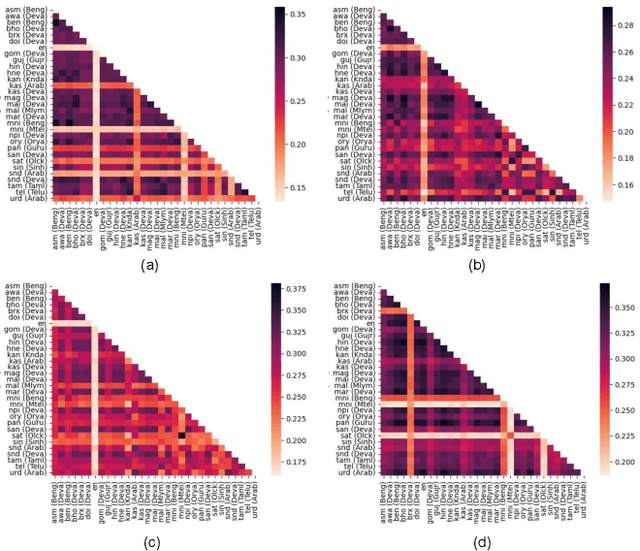
This research investigates biases in text-to-image (TTI) models for the Indic languages widely spoken across India. It evaluates and compares the generative performance and cultural relevance of leading TTI models in these languages against their performance in English. Using the proposed IndicTTI benchmark, we comprehensively assess the performance of 30 Indic languages with two open-source diffusion models and two commercial generation APIs. The primary objective of this benchmark is to evaluate the support for Indic languages in these models and identify areas needing improvement. Given the linguistic diversity of 30 languages spoken by over 1.4 billion people, this benchmark aims to provide a detailed and insightful analysis of TTI models' effectiveness within the Indic linguistic landscape. The data and code for the IndicTTI benchmark can be accessed at https://iab-rubric.org/resources/other-databases/indictti.
On Responsible Machine Learning Datasets with Fairness, Privacy, and Regulatory Norms
Oct 31, 2023
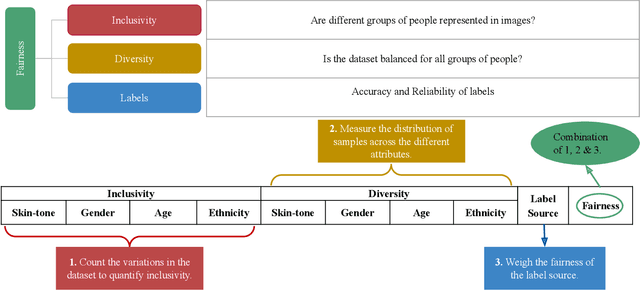


Artificial Intelligence (AI) has made its way into various scientific fields, providing astonishing improvements over existing algorithms for a wide variety of tasks. In recent years, there have been severe concerns over the trustworthiness of AI technologies. The scientific community has focused on the development of trustworthy AI algorithms. However, machine and deep learning algorithms, popular in the AI community today, depend heavily on the data used during their development. These learning algorithms identify patterns in the data, learning the behavioral objective. Any flaws in the data have the potential to translate directly into algorithms. In this study, we discuss the importance of Responsible Machine Learning Datasets and propose a framework to evaluate the datasets through a responsible rubric. While existing work focuses on the post-hoc evaluation of algorithms for their trustworthiness, we provide a framework that considers the data component separately to understand its role in the algorithm. We discuss responsible datasets through the lens of fairness, privacy, and regulatory compliance and provide recommendations for constructing future datasets. After surveying over 100 datasets, we use 60 datasets for analysis and demonstrate that none of these datasets is immune to issues of fairness, privacy preservation, and regulatory compliance. We provide modifications to the ``datasheets for datasets" with important additions for improved dataset documentation. With governments around the world regularizing data protection laws, the method for the creation of datasets in the scientific community requires revision. We believe this study is timely and relevant in today's era of AI.
Are Face Detection Models Biased?
Nov 07, 2022



The presence of bias in deep models leads to unfair outcomes for certain demographic subgroups. Research in bias focuses primarily on facial recognition and attribute prediction with scarce emphasis on face detection. Existing studies consider face detection as binary classification into 'face' and 'non-face' classes. In this work, we investigate possible bias in the domain of face detection through facial region localization which is currently unexplored. Since facial region localization is an essential task for all face recognition pipelines, it is imperative to analyze the presence of such bias in popular deep models. Most existing face detection datasets lack suitable annotation for such analysis. Therefore, we web-curate the Fair Face Localization with Attributes (F2LA) dataset and manually annotate more than 10 attributes per face, including facial localization information. Utilizing the extensive annotations from F2LA, an experimental setup is designed to study the performance of four pre-trained face detectors. We observe (i) a high disparity in detection accuracies across gender and skin-tone, and (ii) interplay of confounding factors beyond demography. The F2LA data and associated annotations can be accessed at http://iab-rubric.org/index.php/F2LA.
DeePhy: On Deepfake Phylogeny
Sep 19, 2022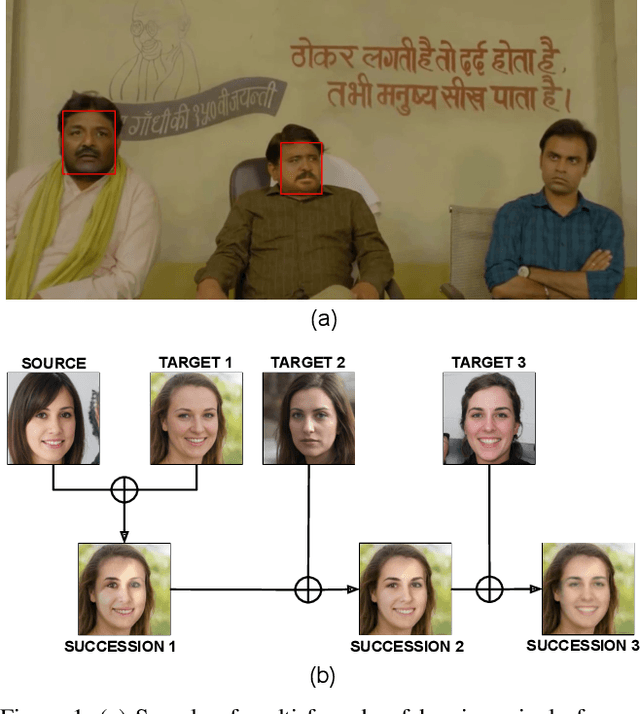
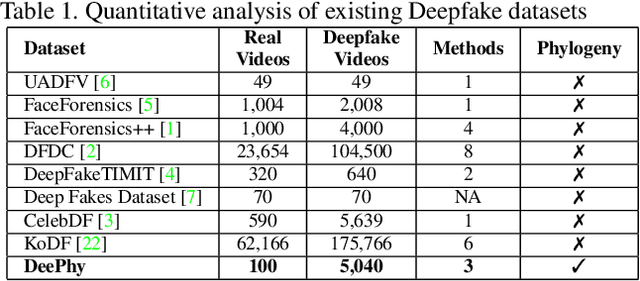

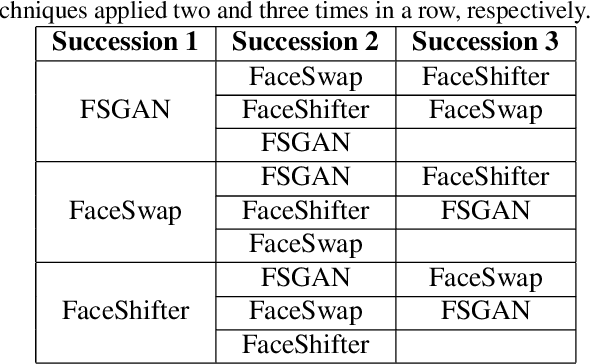
Deepfake refers to tailored and synthetically generated videos which are now prevalent and spreading on a large scale, threatening the trustworthiness of the information available online. While existing datasets contain different kinds of deepfakes which vary in their generation technique, they do not consider progression of deepfakes in a "phylogenetic" manner. It is possible that an existing deepfake face is swapped with another face. This process of face swapping can be performed multiple times and the resultant deepfake can be evolved to confuse the deepfake detection algorithms. Further, many databases do not provide the employed generative model as target labels. Model attribution helps in enhancing the explainability of the detection results by providing information on the generative model employed. In order to enable the research community to address these questions, this paper proposes DeePhy, a novel Deepfake Phylogeny dataset which consists of 5040 deepfake videos generated using three different generation techniques. There are 840 videos of one-time swapped deepfakes, 2520 videos of two-times swapped deepfakes and 1680 videos of three-times swapped deepfakes. With over 30 GBs in size, the database is prepared in over 1100 hours using 18 GPUs of 1,352 GB cumulative memory. We also present the benchmark on DeePhy dataset using six deepfake detection algorithms. The results highlight the need to evolve the research of model attribution of deepfakes and generalize the process over a variety of deepfake generation techniques. The database is available at: http://iab-rubric.org/deephy-database
Anatomizing Bias in Facial Analysis
Dec 13, 2021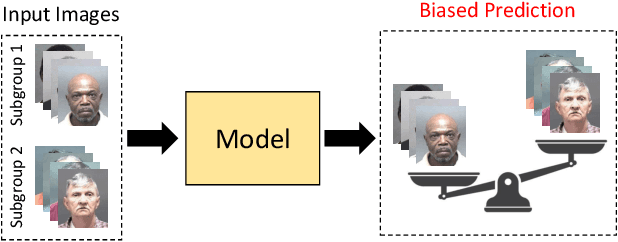
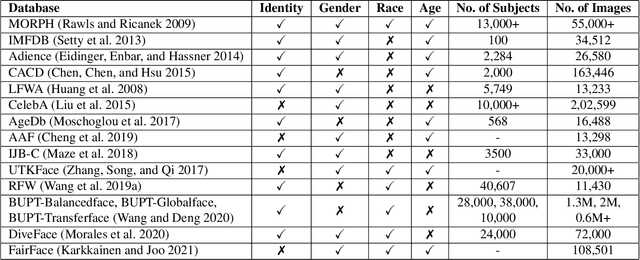
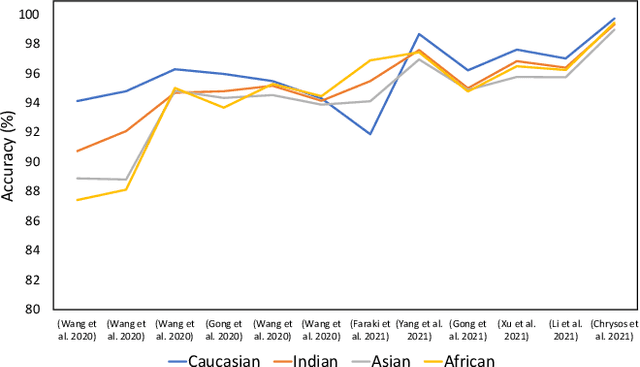
Existing facial analysis systems have been shown to yield biased results against certain demographic subgroups. Due to its impact on society, it has become imperative to ensure that these systems do not discriminate based on gender, identity, or skin tone of individuals. This has led to research in the identification and mitigation of bias in AI systems. In this paper, we encapsulate bias detection/estimation and mitigation algorithms for facial analysis. Our main contributions include a systematic review of algorithms proposed for understanding bias, along with a taxonomy and extensive overview of existing bias mitigation algorithms. We also discuss open challenges in the field of biased facial analysis.
Unravelling the Effect of Image Distortions for Biased Prediction of Pre-trained Face Recognition Models
Aug 14, 2021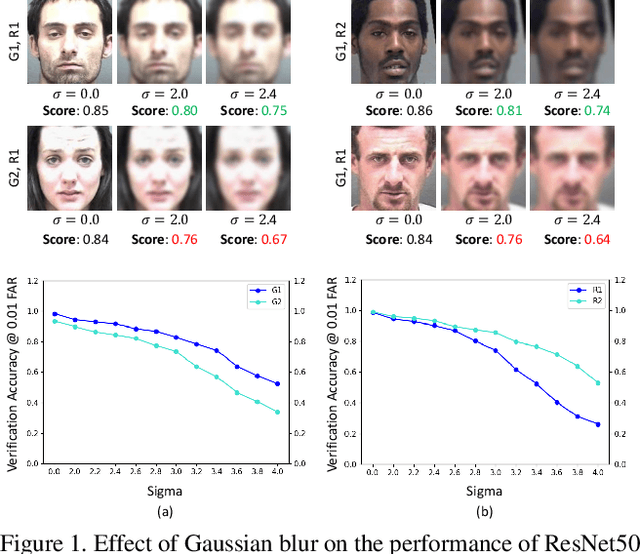

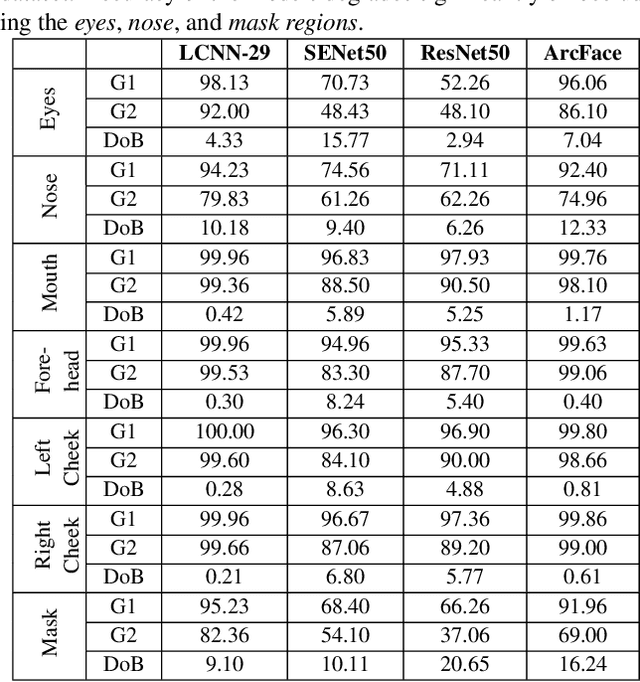

Identifying and mitigating bias in deep learning algorithms has gained significant popularity in the past few years due to its impact on the society. Researchers argue that models trained on balanced datasets with good representation provide equal and unbiased performance across subgroups. However, \textit{can seemingly unbiased pre-trained model become biased when input data undergoes certain distortions?} For the first time, we attempt to answer this question in the context of face recognition. We provide a systematic analysis to evaluate the performance of four state-of-the-art deep face recognition models in the presence of image distortions across different \textit{gender} and \textit{race} subgroups. We have observed that image distortions have a relationship with the performance gap of the model across different subgroups.
Multi-Task Driven Explainable Diagnosis of COVID-19 using Chest X-ray Images
Aug 03, 2020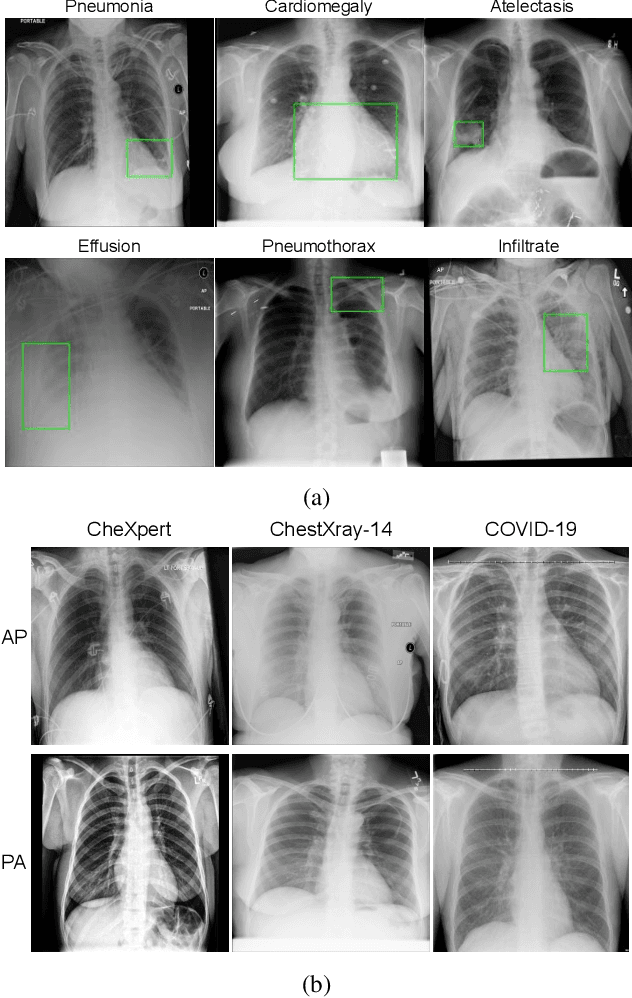
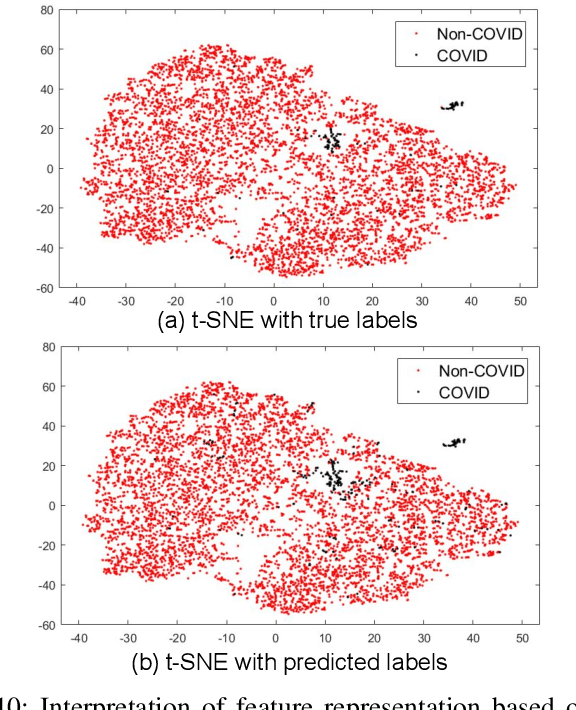
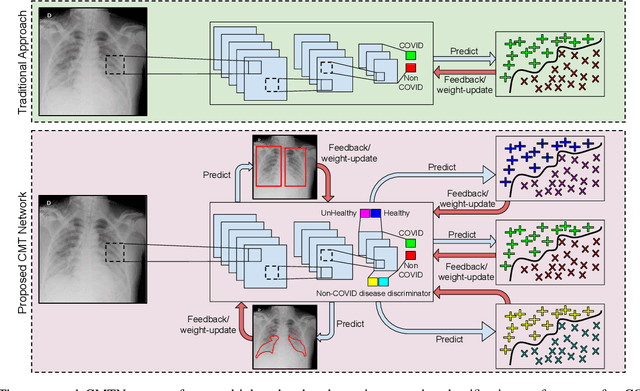
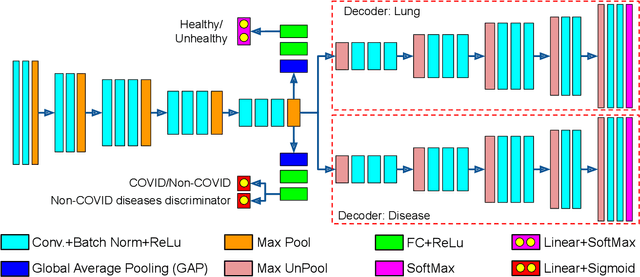
With increasing number of COVID-19 cases globally, all the countries are ramping up the testing numbers. While the RT-PCR kits are available in sufficient quantity in several countries, others are facing challenges with limited availability of testing kits and processing centers in remote areas. This has motivated researchers to find alternate methods of testing which are reliable, easily accessible and faster. Chest X-Ray is one of the modalities that is gaining acceptance as a screening modality. Towards this direction, the paper has two primary contributions. Firstly, we present the COVID-19 Multi-Task Network which is an automated end-to-end network for COVID-19 screening. The proposed network not only predicts whether the CXR has COVID-19 features present or not, it also performs semantic segmentation of the regions of interest to make the model explainable. Secondly, with the help of medical professionals, we manually annotate the lung regions of 9000 frontal chest radiographs taken from ChestXray-14, CheXpert and a consolidated COVID-19 dataset. Further, 200 chest radiographs pertaining to COVID-19 patients are also annotated for semantic segmentation. This database will be released to the research community.