 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Model Prediction Without Using Protected Attribute Information
Mar 31, 2026The problem of bias persists in the deep learning community as models continue to provide disparate performance across different demographic subgroups. Therefore, several algorithms have been proposed to improve the fairness of deep models. However, a majority of these algorithms utilize the protected attribute information for bias mitigation, which severely limits their application in real-world scenarios. To address this concern, we have proposed a novel algorithm, termed as \textbf{Non-Protected Attribute-based Debiasing (NPAD)} algorithm for bias mitigation, that does not require the protected attribute information. The proposed NPAD algorithm utilizes the auxiliary information provided by the non-protected attributes to optimize the model for bias mitigation. Further, two different loss functions, \textbf{Debiasing via Attribute Cluster Loss (DACL)} and \textbf{Filter Redundancy Loss (FRL)} have been proposed to optimize the model for fairness goals. Multiple experiments are performed on the LFWA and CelebA datasets for facial attribute prediction, and a significant reduction in bias across different gender and age subgroups is observed.
Are Face Detection Models Biased?
Nov 07, 2022



The presence of bias in deep models leads to unfair outcomes for certain demographic subgroups. Research in bias focuses primarily on facial recognition and attribute prediction with scarce emphasis on face detection. Existing studies consider face detection as binary classification into 'face' and 'non-face' classes. In this work, we investigate possible bias in the domain of face detection through facial region localization which is currently unexplored. Since facial region localization is an essential task for all face recognition pipelines, it is imperative to analyze the presence of such bias in popular deep models. Most existing face detection datasets lack suitable annotation for such analysis. Therefore, we web-curate the Fair Face Localization with Attributes (F2LA) dataset and manually annotate more than 10 attributes per face, including facial localization information. Utilizing the extensive annotations from F2LA, an experimental setup is designed to study the performance of four pre-trained face detectors. We observe (i) a high disparity in detection accuracies across gender and skin-tone, and (ii) interplay of confounding factors beyond demography. The F2LA data and associated annotations can be accessed at http://iab-rubric.org/index.php/F2LA.
Anatomizing Bias in Facial Analysis
Dec 13, 2021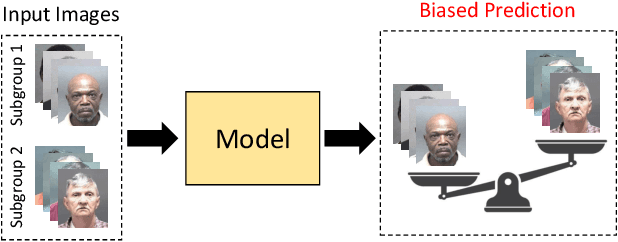
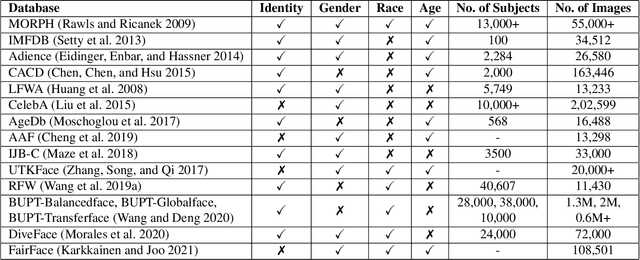
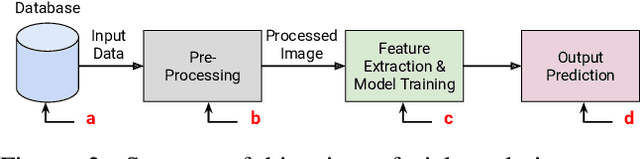
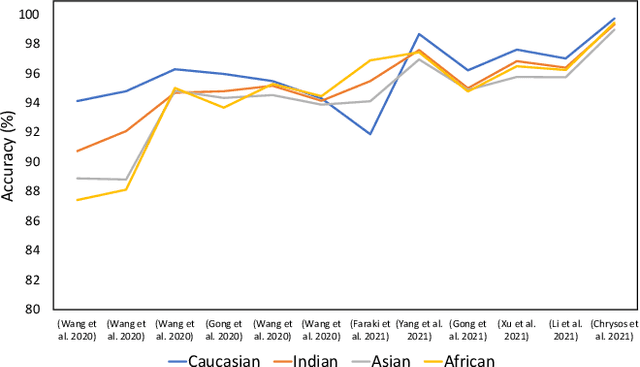
Existing facial analysis systems have been shown to yield biased results against certain demographic subgroups. Due to its impact on society, it has become imperative to ensure that these systems do not discriminate based on gender, identity, or skin tone of individuals. This has led to research in the identification and mitigation of bias in AI systems. In this paper, we encapsulate bias detection/estimation and mitigation algorithms for facial analysis. Our main contributions include a systematic review of algorithms proposed for understanding bias, along with a taxonomy and extensive overview of existing bias mitigation algorithms. We also discuss open challenges in the field of biased facial analysis.
Unravelling the Effect of Image Distortions for Biased Prediction of Pre-trained Face Recognition Models
Aug 14, 2021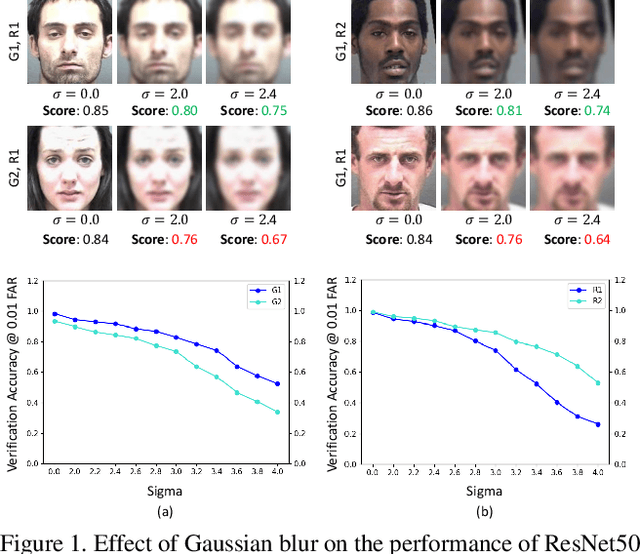

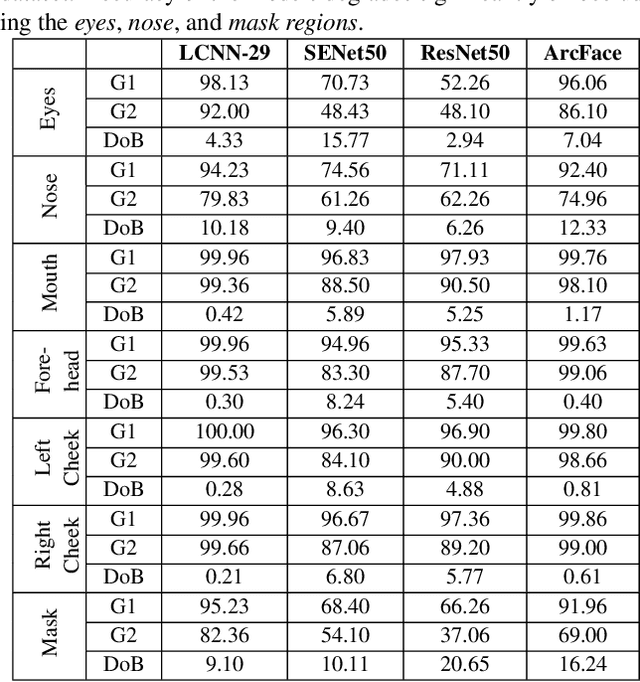

Identifying and mitigating bias in deep learning algorithms has gained significant popularity in the past few years due to its impact on the society. Researchers argue that models trained on balanced datasets with good representation provide equal and unbiased performance across subgroups. However, \textit{can seemingly unbiased pre-trained model become biased when input data undergoes certain distortions?} For the first time, we attempt to answer this question in the context of face recognition. We provide a systematic analysis to evaluate the performance of four state-of-the-art deep face recognition models in the presence of image distortions across different \textit{gender} and \textit{race} subgroups. We have observed that image distortions have a relationship with the performance gap of the model across different subgroups.
Indian Masked Faces in the Wild Dataset
Jun 17, 2021
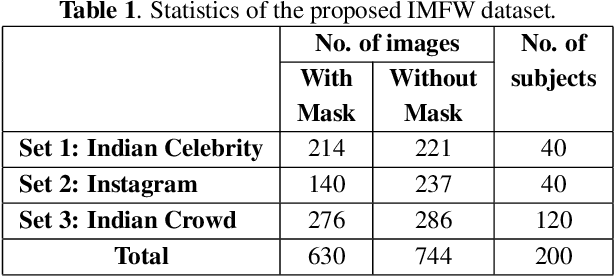
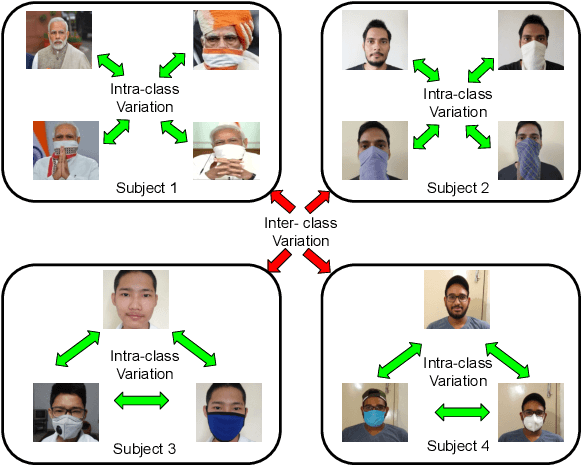
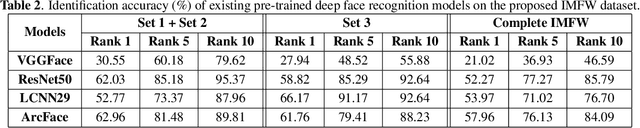
Due to the COVID-19 pandemic, wearing face masks has become a mandate in public places worldwide. Face masks occlude a significant portion of the facial region. Additionally, people wear different types of masks, from simple ones to ones with graphics and prints. These pose new challenges to face recognition algorithms. Researchers have recently proposed a few masked face datasets for designing algorithms to overcome the challenges of masked face recognition. However, existing datasets lack the cultural diversity and collection in the unrestricted settings. Country like India with attire diversity, people are not limited to wearing traditional masks but also clothing like a thin cotton printed towel (locally called as ``gamcha''), ``stoles'', and ``handkerchiefs'' to cover their faces. In this paper, we present a novel \textbf{Indian Masked Faces in the Wild (IMFW)} dataset which contains images with variations in pose, illumination, resolution, and the variety of masks worn by the subjects. We have also benchmarked the performance of existing face recognition models on the proposed IMFW dataset. Experimental results demonstrate the limitations of existing algorithms in presence of diverse conditions.
Class Equilibrium using Coulomb's Law
Apr 25, 2021
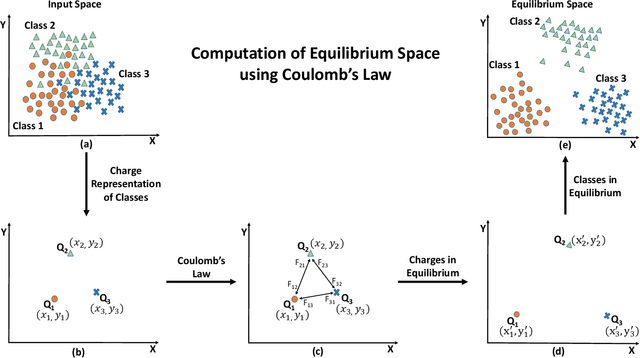

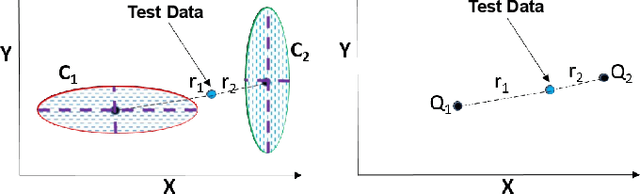
Projection algorithms learn a transformation function to project the data from input space to the feature space, with the objective of increasing the inter-class distance. However, increasing the inter-class distance can affect the intra-class distance. Maintaining an optimal inter-class separation among the classes without affecting the intra-class distance of the data distribution is a challenging task. In this paper, inspired by the Coulomb's law of Electrostatics, we propose a new algorithm to compute the equilibrium space of any data distribution where the separation among the classes is optimal. The algorithm further learns the transformation between the input space and equilibrium space to perform classification in the equilibrium space. The performance of the proposed algorithm is evaluated on four publicly available datasets at three different resolutions. It is observed that the proposed algorithm performs well for low-resolution images.
Subclass Contrastive Loss for Injured Face Recognition
Aug 05, 2020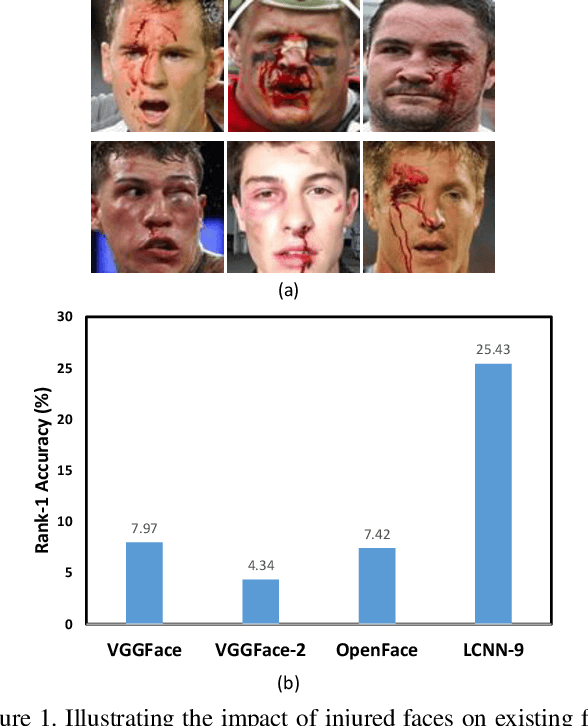
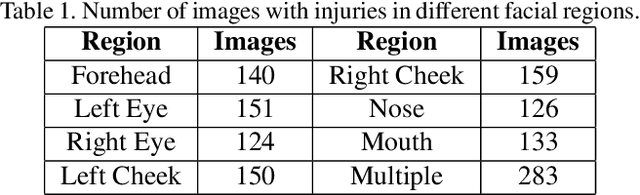
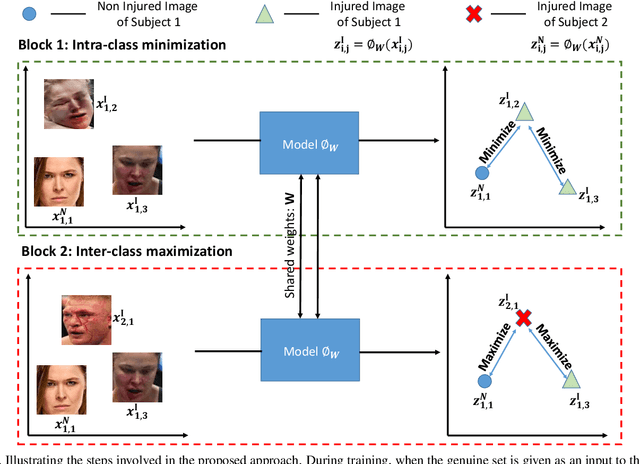
Deaths and injuries are common in road accidents, violence, and natural disaster. In such cases, one of the main tasks of responders is to retrieve the identity of the victims to reunite families and ensure proper identification of deceased/ injured individuals. Apart from this, identification of unidentified dead bodies due to violence and accidents is crucial for the police investigation. In the absence of identification cards, current practices for this task include DNA profiling and dental profiling. Face is one of the most commonly used and widely accepted biometric modalities for recognition. However, face recognition is challenging in the presence of facial injuries such as swelling, bruises, blood clots, laceration, and avulsion which affect the features used in recognition. In this paper, for the first time, we address the problem of injured face recognition and propose a novel Subclass Contrastive Loss (SCL) for this task. A novel database, termed as Injured Face (IF) database, is also created to instigate research in this direction. Experimental analysis shows that the proposed loss function surpasses existing algorithm for injured face recognition.
Multi-Task Driven Explainable Diagnosis of COVID-19 using Chest X-ray Images
Aug 03, 2020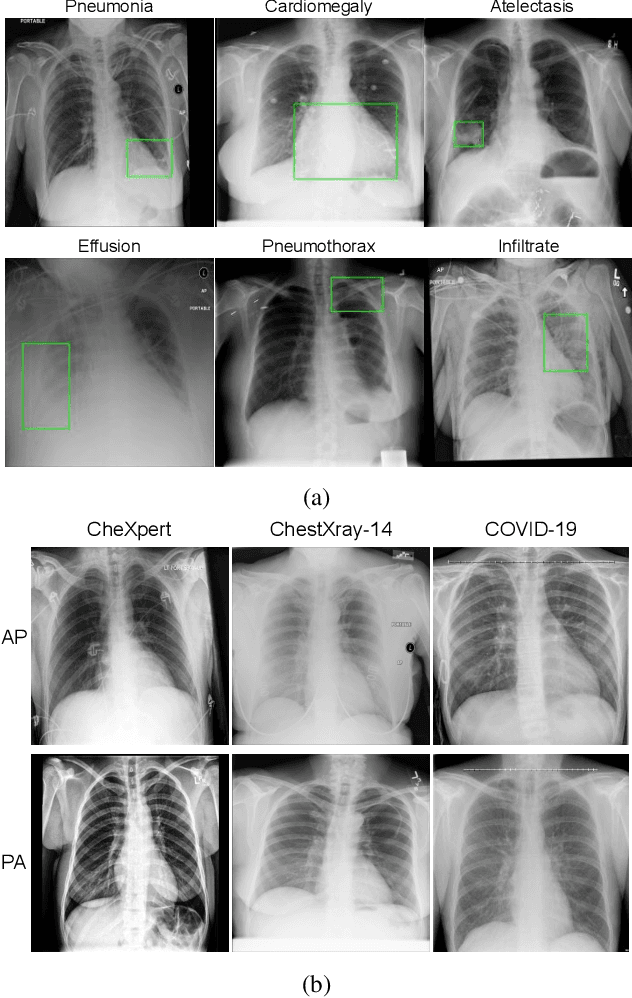
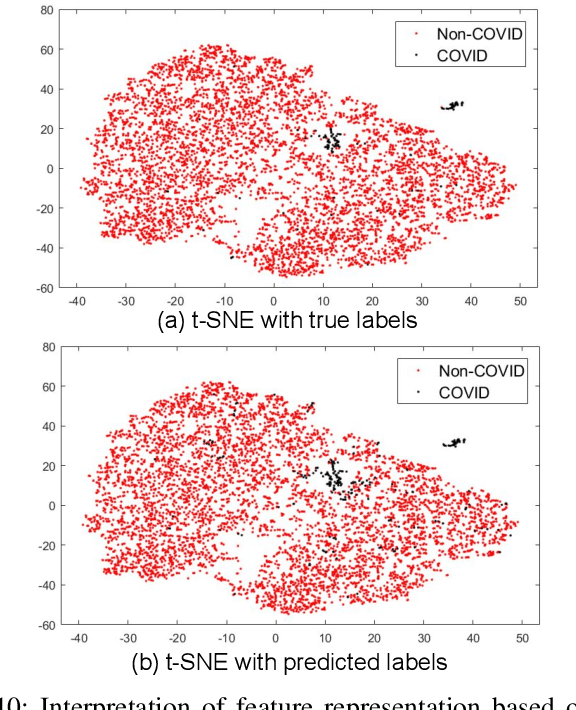
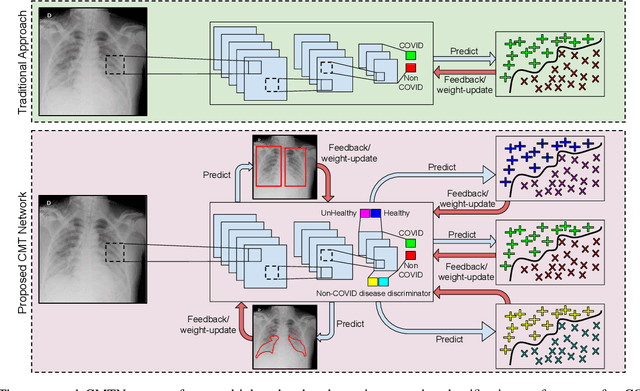
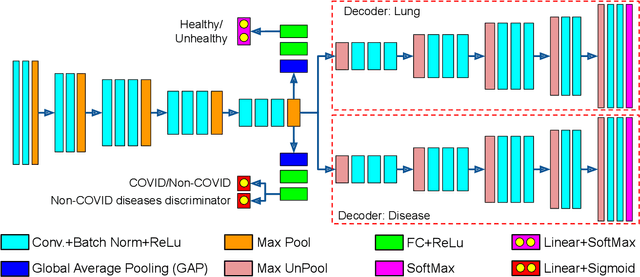
With increasing number of COVID-19 cases globally, all the countries are ramping up the testing numbers. While the RT-PCR kits are available in sufficient quantity in several countries, others are facing challenges with limited availability of testing kits and processing centers in remote areas. This has motivated researchers to find alternate methods of testing which are reliable, easily accessible and faster. Chest X-Ray is one of the modalities that is gaining acceptance as a screening modality. Towards this direction, the paper has two primary contributions. Firstly, we present the COVID-19 Multi-Task Network which is an automated end-to-end network for COVID-19 screening. The proposed network not only predicts whether the CXR has COVID-19 features present or not, it also performs semantic segmentation of the regions of interest to make the model explainable. Secondly, with the help of medical professionals, we manually annotate the lung regions of 9000 frontal chest radiographs taken from ChestXray-14, CheXpert and a consolidated COVID-19 dataset. Further, 200 chest radiographs pertaining to COVID-19 patients are also annotated for semantic segmentation. This database will be released to the research community.
Data Fine-tuning
Dec 10, 2018
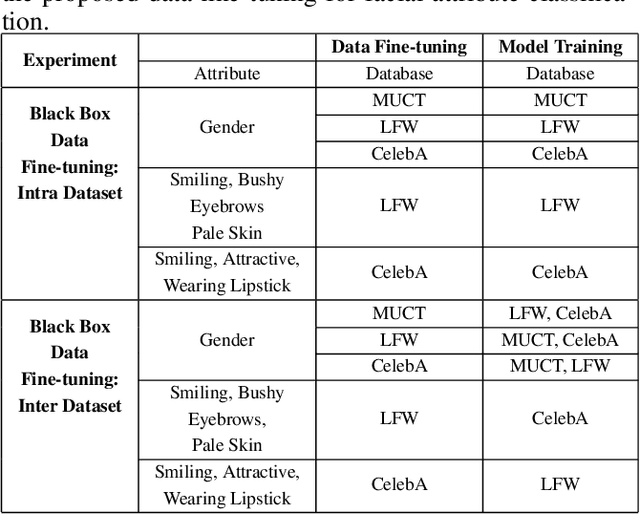
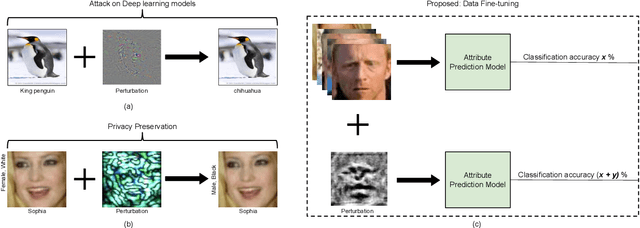

In real-world applications, commercial off-the-shelf systems are utilized for performing automated facial analysis including face recognition, emotion recognition, and attribute prediction. However, a majority of these commercial systems act as black boxes due to the inaccessibility of the model parameters which makes it challenging to fine-tune the models for specific applications. Stimulated by the advances in adversarial perturbations, this research proposes the concept of Data Fine-tuning to improve the classification accuracy of a given model without changing the parameters of the model. This is accomplished by modeling it as data (image) perturbation problem. A small amount of "noise" is added to the input with the objective of minimizing the classification loss without affecting the (visual) appearance. Experiments performed on three publicly available datasets LFW, CelebA, and MUCT, demonstrate the effectiveness of the proposed concept.