 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Manual and Automated Skin Tone Assignments for Face Recognition Applications
Apr 29, 2021

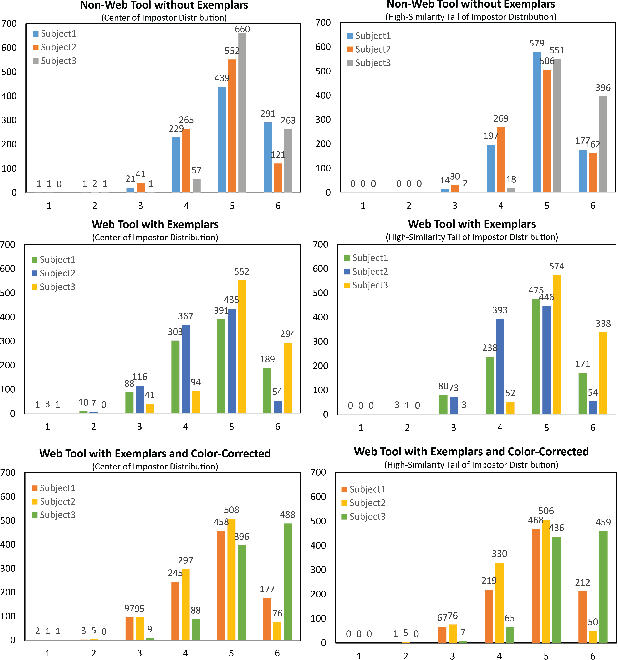
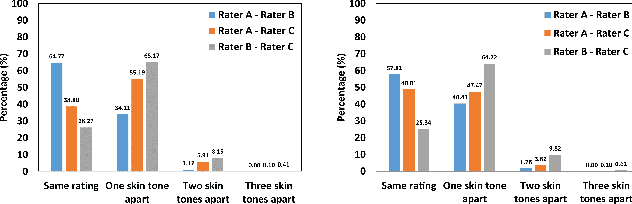
News reports have suggested that darker skin tone causes an increase in face recognition errors. The Fitzpatrick scale is widely used in dermatology to classify sensitivity to sun exposure and skin tone. In this paper, we analyze a set of manual Fitzpatrick skin type assignments and also employ the individual typology angle to automatically estimate the skin tone from face images. The set of manual skin tone rating experiments shows that there are inconsistencies between human raters that are difficult to eliminate. Efforts to automate skin tone rating suggest that it is particularly challenging on images collected without a calibration object in the scene. However, after the color-correction, the level of agreement between automated and manual approaches is found to be 96% or better for the MORPH images. To our knowledge, this is the first work to: (a) examine the consistency of manual skin tone ratings across observers, (b) document that there is substantial variation in the rating of the same image by different observers even when exemplar images are given for guidance and all images are color-corrected, and (c) compare manual versus automated skin tone ratings.
Characterizing the Variability in Face Recognition Accuracy Relative to Race
May 08, 2019
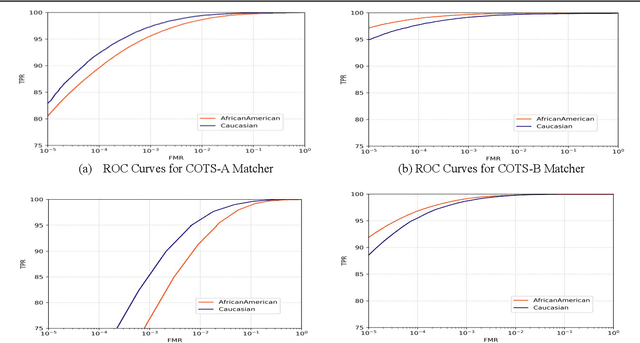
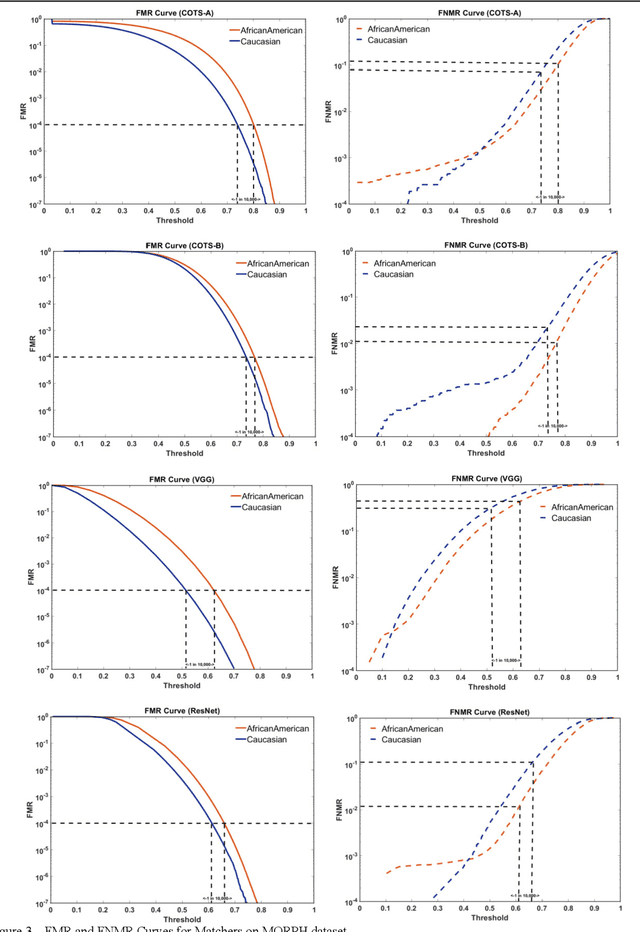
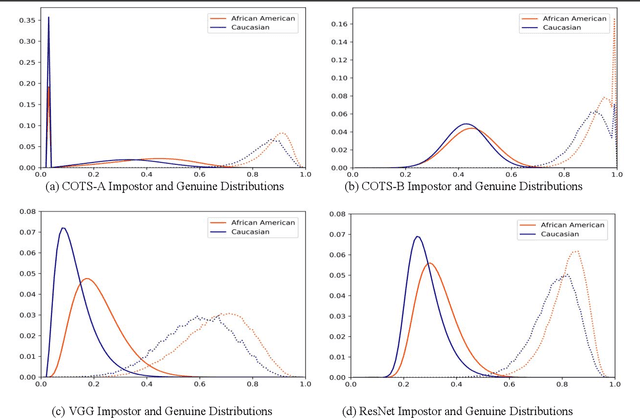
Many recent news headlines have labeled face recognition technology as biased or racist. We report on a methodical investigation into differences in face recognition accuracy between African-American and Caucasian image cohorts of the MORPH dataset. We find that, for all four matchers considered, the impostor and the genuine distributions are statistically significantly different between cohorts. For a fixed decision threshold, the African-American image cohort has a higher false match rate and a lower false non-match rate. ROC curves compare verification rates at the same false match rate, but the different cohorts achieve the same false match rate at different thresholds. This means that ROC comparisons are not relevant to operational scenarios that use a fixed decision threshold. We show that, for the ResNet matcher, the two cohorts have approximately equal separation of impostor and genuine distributions. Using ICAO compliance as a standard of image quality, we find that the initial image cohorts have unequal rates of good quality images. The ICAO-compliant subsets of the original image cohorts show improved accuracy, with the main effect being to reducing the low-similarity tail of the genuine distributions.