 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVec2Face+ for Face Dataset Generation
Jul 23, 2025When synthesizing identities as face recognition training data, it is generally believed that large inter-class separability and intra-class attribute variation are essential for synthesizing a quality dataset. % This belief is generally correct, and this is what we aim for. However, when increasing intra-class variation, existing methods overlook the necessity of maintaining intra-class identity consistency. % To address this and generate high-quality face training data, we propose Vec2Face+, a generative model that creates images directly from image features and allows for continuous and easy control of face identities and attributes. Using Vec2Face+, we obtain datasets with proper inter-class separability and intra-class variation and identity consistency using three strategies: 1) we sample vectors sufficiently different from others to generate well-separated identities; 2) we propose an AttrOP algorithm for increasing general attribute variations; 3) we propose LoRA-based pose control for generating images with profile head poses, which is more efficient and identity-preserving than AttrOP. % Our system generates VFace10K, a synthetic face dataset with 10K identities, which allows an FR model to achieve state-of-the-art accuracy on seven real-world test sets. Scaling the size to 4M and 12M images, the corresponding VFace100K and VFace300K datasets yield higher accuracy than the real-world training dataset, CASIA-WebFace, on five real-world test sets. This is the first time a synthetic dataset beats the CASIA-WebFace in average accuracy. In addition, we find that only 1 out of 11 synthetic datasets outperforms random guessing (\emph{i.e., 50\%}) in twin verification and that models trained with synthetic identities are more biased than those trained with real identities. Both are important aspects for future investigation.
Impact of Sunglasses on One-to-Many Facial Identification Accuracy
Dec 07, 2024



One-to-many facial identification is documented to achieve high accuracy in the case where both the probe and the gallery are `mugshot quality' images. However, an increasing number of documented instances of wrongful arrest following one-to-many facial identification have raised questions about its accuracy. Probe images used in one-to-many facial identification are often cropped from frames of surveillance video and deviate from `mugshot quality' in various ways. This paper systematically explores how the accuracy of one-to-many facial identification is degraded by the person in the probe image choosing to wear dark sunglasses. We show that sunglasses degrade accuracy for mugshot-quality images by an amount similar to strong blur or noticeably lower resolution. Further, we demonstrate that the combination of sunglasses with blur or lower resolution results in even more pronounced loss in accuracy. These results have important implications for developing objective criteria to qualify a probe image for the level of accuracy to be expected if it used for one-to-many identification. To ameliorate the accuracy degradation caused by dark sunglasses, we show that it is possible to recover about 38% of the lost accuracy by synthetically adding sunglasses to all the gallery images, without model re-training. We also show that increasing the representation of wearing-sunglasses images in the training set can largely reduce the error rate. The image set assembled for this research will be made available to support replication and further research into this problem.
Vec2Face: Scaling Face Dataset Generation with Loosely Constrained Vectors
Sep 04, 2024This paper studies how to synthesize face images of non-existent persons, to create a dataset that allows effective training of face recognition (FR) models. Two important goals are (1) the ability to generate a large number of distinct identities (inter-class separation) with (2) a wide variation in appearance of each identity (intra-class variation). However, existing works 1) are typically limited in how many well-separated identities can be generated and 2) either neglect or use a separate editing model for attribute augmentation. We propose Vec2Face, a holistic model that uses only a sampled vector as input and can flexibly generate and control face images and their attributes. Composed of a feature masked autoencoder and a decoder, Vec2Face is supervised by face image reconstruction and can be conveniently used in inference. Using vectors with low similarity among themselves as inputs, Vec2Face generates well-separated identities. Randomly perturbing an input identity vector within a small range allows Vec2Face to generate faces of the same identity with robust variation in face attributes. It is also possible to generate images with designated attributes by adjusting vector values with a gradient descent method. Vec2Face has efficiently synthesized as many as 300K identities with 15 million total images, whereas 60K is the largest number of identities created in the previous works. FR models trained with the generated HSFace datasets, from 10k to 300k identities, achieve state-of-the-art accuracy, from 92% to 93.52%, on five real-world test sets. For the first time, our model created using a synthetic training set achieves higher accuracy than the model created using a same-scale training set of real face images (on the CALFW test set).
What is a Goldilocks Face Verification Test Set?
May 24, 2024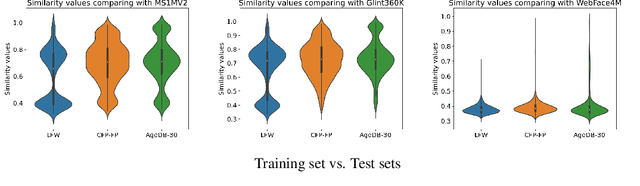


Face Recognition models are commonly trained with web-scraped datasets containing millions of images and evaluated on test sets emphasizing pose, age and mixed attributes. With train and test sets both assembled from web-scraped images, it is critical to ensure disjoint sets of identities between train and test sets. However, existing train and test sets have not considered this. Moreover, as accuracy levels become saturated, such as LFW $>99.8\%$, more challenging test sets are needed. We show that current train and test sets are generally not identity- or even image-disjoint, and that this results in an optimistic bias in the estimated accuracy. In addition, we show that identity-disjoint folds are important in the 10-fold cross-validation estimate of test accuracy. To better support continued advances in face recognition, we introduce two "Goldilocks" test sets, Hadrian and Eclipse. The former emphasizes challenging facial hairstyles and latter emphasizes challenging over- and under-exposure conditions. Images in both datasets are from a large, controlled-acquisition (not web-scraped) dataset, so they are identity- and image-disjoint with all popular training sets. Accuracy for these new test sets generally falls below that observed on LFW, CPLFW, CALFW, CFP-FP and AgeDB-30, showing that these datasets represent important dimensions for improvement of face recognition. The datasets are available at: \url{https://github.com/HaiyuWu/SOTA-Face-Recognition-Train-and-Test}
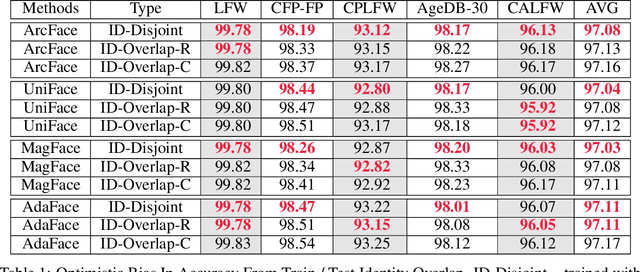
Identity Overlap Between Face Recognition Train/Test Data: Causing Optimistic Bias in Accuracy Measurement
May 15, 2024
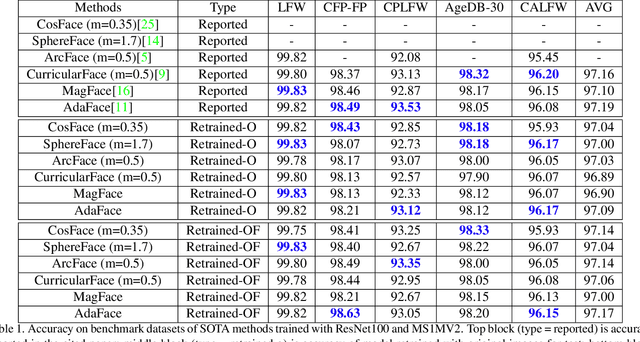

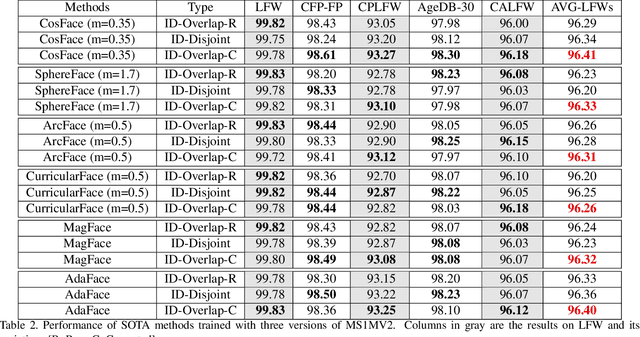
A fundamental tenet of pattern recognition is that overlap between training and testing sets causes an optimistic accuracy estimate. Deep CNNs for face recognition are trained for N-way classification of the identities in the training set. Accuracy is commonly estimated as average 10-fold classification accuracy on image pairs from test sets such as LFW, CALFW, CPLFW, CFP-FP and AgeDB-30. Because train and test sets have been independently assembled, images and identities in any given test set may also be present in any given training set. In particular, our experiments reveal a surprising degree of identity and image overlap between the LFW family of test sets and the MS1MV2 training set. Our experiments also reveal identity label noise in MS1MV2. We compare accuracy achieved with same-size MS1MV2 subsets that are identity-disjoint and not identity-disjoint with LFW, to reveal the size of the optimistic bias. Using more challenging test sets from the LFW family, we find that the size of the optimistic bias is larger for more challenging test sets. Our results highlight the lack of and the need for identity-disjoint train and test methodology in face recognition research.
LogicNet: A Logical Consistency Embedded Face Attribute Learning Network
Nov 19, 2023
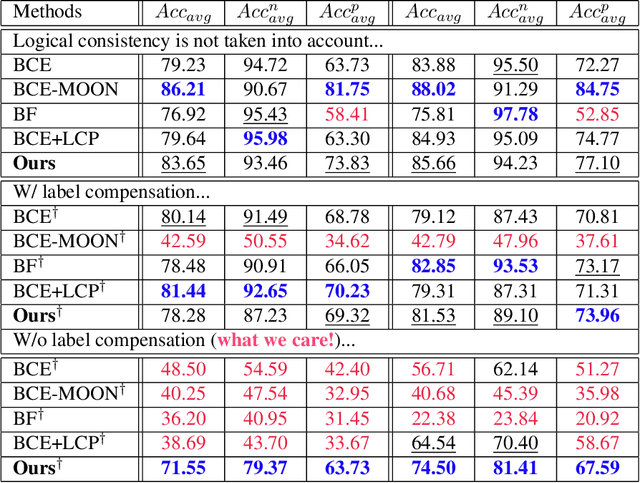
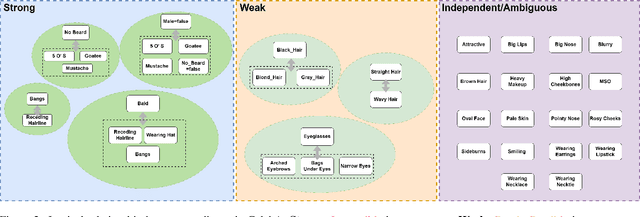

Ensuring logical consistency in predictions is a crucial yet overlooked aspect in multi-attribute classification. We explore the potential reasons for this oversight and introduce two pressing challenges to the field: 1) How can we ensure that a model, when trained with data checked for logical consistency, yields predictions that are logically consistent? 2) How can we achieve the same with data that hasn't undergone logical consistency checks? Minimizing manual effort is also essential for enhancing automation. To address these challenges, we introduce two datasets, FH41K and CelebA-logic, and propose LogicNet, an adversarial training framework that learns the logical relationships between attributes. Accuracy of LogicNet surpasses that of the next-best approach by 23.05%, 9.96%, and 1.71% on FH37K, FH41K, and CelebA-logic, respectively. In real-world case analysis, our approach can achieve a reduction of more than 50% in the average number of failed cases compared to other methods.