 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Evaluation Framework for the Study of the Effects of Facial Filters on Face Recognition Accuracy
Jul 23, 2025Facial filters are now commonplace for social media users around the world. Previous work has demonstrated that facial filters can negatively impact automated face recognition performance. However, these studies focus on small numbers of hand-picked filters in particular styles. In order to more effectively incorporate the wide ranges of filters present on various social media applications, we introduce a framework that allows for larger-scale study of the impact of facial filters on automated recognition. This framework includes a controlled dataset of face images, a principled filter selection process that selects a representative range of filters for experimentation, and a set of experiments to evaluate the filters' impact on recognition. We demonstrate our framework with a case study of filters from the American applications Instagram and Snapchat and the Chinese applications Meitu and Pitu to uncover cross-cultural differences. Finally, we show how the filtering effect in a face embedding space can easily be detected and restored to improve face recognition performance.
What is a Goldilocks Face Verification Test Set?
May 24, 2024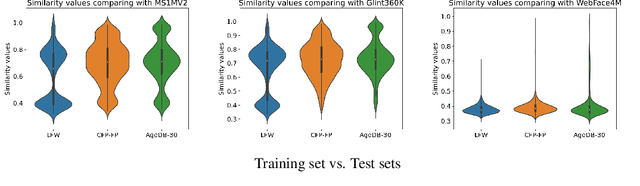


Face Recognition models are commonly trained with web-scraped datasets containing millions of images and evaluated on test sets emphasizing pose, age and mixed attributes. With train and test sets both assembled from web-scraped images, it is critical to ensure disjoint sets of identities between train and test sets. However, existing train and test sets have not considered this. Moreover, as accuracy levels become saturated, such as LFW $>99.8\%$, more challenging test sets are needed. We show that current train and test sets are generally not identity- or even image-disjoint, and that this results in an optimistic bias in the estimated accuracy. In addition, we show that identity-disjoint folds are important in the 10-fold cross-validation estimate of test accuracy. To better support continued advances in face recognition, we introduce two "Goldilocks" test sets, Hadrian and Eclipse. The former emphasizes challenging facial hairstyles and latter emphasizes challenging over- and under-exposure conditions. Images in both datasets are from a large, controlled-acquisition (not web-scraped) dataset, so they are identity- and image-disjoint with all popular training sets. Accuracy for these new test sets generally falls below that observed on LFW, CPLFW, CALFW, CFP-FP and AgeDB-30, showing that these datasets represent important dimensions for improvement of face recognition. The datasets are available at: \url{https://github.com/HaiyuWu/SOTA-Face-Recognition-Train-and-Test}
Identity Overlap Between Face Recognition Train/Test Data: Causing Optimistic Bias in Accuracy Measurement
May 15, 2024
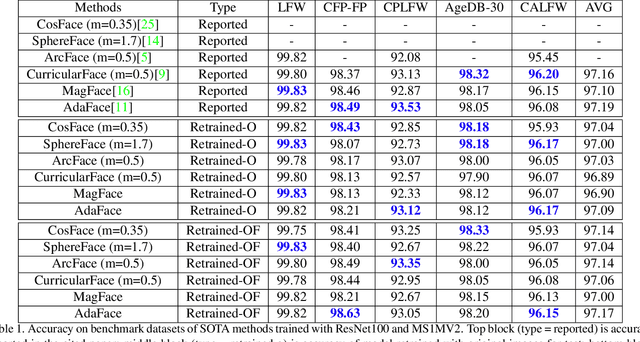

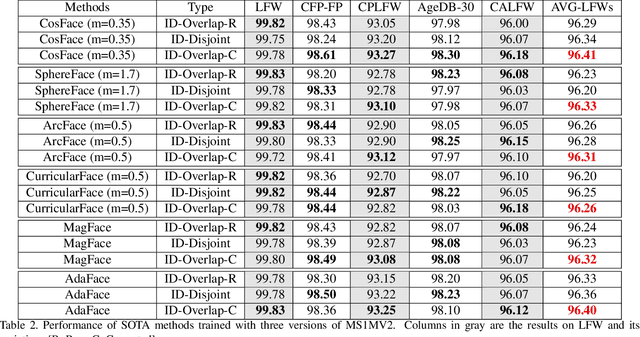
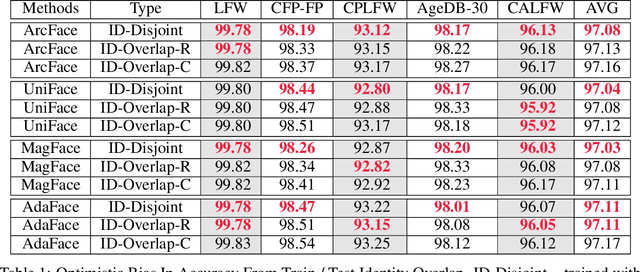
A fundamental tenet of pattern recognition is that overlap between training and testing sets causes an optimistic accuracy estimate. Deep CNNs for face recognition are trained for N-way classification of the identities in the training set. Accuracy is commonly estimated as average 10-fold classification accuracy on image pairs from test sets such as LFW, CALFW, CPLFW, CFP-FP and AgeDB-30. Because train and test sets have been independently assembled, images and identities in any given test set may also be present in any given training set. In particular, our experiments reveal a surprising degree of identity and image overlap between the LFW family of test sets and the MS1MV2 training set. Our experiments also reveal identity label noise in MS1MV2. We compare accuracy achieved with same-size MS1MV2 subsets that are identity-disjoint and not identity-disjoint with LFW, to reveal the size of the optimistic bias. Using more challenging test sets from the LFW family, we find that the size of the optimistic bias is larger for more challenging test sets. Our results highlight the lack of and the need for identity-disjoint train and test methodology in face recognition research.