 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Bilateral Ear Symmetry Affect Deep Ear Features?
Aug 06, 2025Ear recognition has gained attention as a reliable biometric technique due to the distinctive characteristics of human ears. With the increasing availability of large-scale datasets, convolutional neural networks (CNNs) have been widely adopted to learn features directly from raw ear images, outperforming traditional hand-crafted methods. However, the effect of bilateral ear symmetry on the features learned by CNNs has received little attention in recent studies. In this paper, we investigate how bilateral ear symmetry influences the effectiveness of CNN-based ear recognition. To this end, we first develop an ear side classifier to automatically categorize ear images as either left or right. We then explore the impact of incorporating this side information during both training and test. Cross-dataset evaluations are conducted on five datasets. Our results suggest that treating left and right ears separately during training and testing can lead to notable performance improvements. Furthermore, our ablation studies on alignment strategies, input sizes, and various hyperparameter settings provide practical insights into training CNN-based ear recognition systems on large-scale datasets to achieve higher verification rates.
A Comprehensive Evaluation Framework for the Study of the Effects of Facial Filters on Face Recognition Accuracy
Jul 23, 2025Facial filters are now commonplace for social media users around the world. Previous work has demonstrated that facial filters can negatively impact automated face recognition performance. However, these studies focus on small numbers of hand-picked filters in particular styles. In order to more effectively incorporate the wide ranges of filters present on various social media applications, we introduce a framework that allows for larger-scale study of the impact of facial filters on automated recognition. This framework includes a controlled dataset of face images, a principled filter selection process that selects a representative range of filters for experimentation, and a set of experiments to evaluate the filters' impact on recognition. We demonstrate our framework with a case study of filters from the American applications Instagram and Snapchat and the Chinese applications Meitu and Pitu to uncover cross-cultural differences. Finally, we show how the filtering effect in a face embedding space can easily be detected and restored to improve face recognition performance.
Improved Ear Verification with Vision Transformers and Overlapping Patches
Mar 30, 2025Ear recognition has emerged as a promising biometric modality due to the relative stability in appearance during adulthood. Although Vision Transformers (ViTs) have been widely used in image recognition tasks, their efficiency in ear recognition has been hampered by a lack of attention to overlapping patches, which is crucial for capturing intricate ear features. In this study, we evaluate ViT-Tiny (ViT-T), ViT-Small (ViT-S), ViT-Base (ViT-B) and ViT-Large (ViT-L) configurations on a diverse set of datasets (OPIB, AWE, WPUT, and EarVN1.0), using an overlapping patch selection strategy. Results demonstrate the critical importance of overlapping patches, yielding superior performance in 44 of 48 experiments in a structured study. Moreover, upon comparing the results of the overlapping patches with the non-overlapping configurations, the increase is significant, reaching up to 10% for the EarVN1.0 dataset. In terms of model performance, the ViT-T model consistently outperformed the ViT-S, ViT-B, and ViT-L models on the AWE, WPUT, and EarVN1.0 datasets. The highest scores were achieved in a configuration with a patch size of 28x28 and a stride of 14 pixels. This patch-stride configuration represents 25% of the normalized image area (112x112 pixels) for the patch size and 12.5% of the row or column size for the stride. This study confirms that transformer architectures with overlapping patch selection can serve as an efficient and high-performing option for ear-based biometric recognition tasks in verification scenarios.
Can the accuracy bias by facial hairstyle be reduced through balancing the training data?
May 30, 2024



Appearance of a face can be greatly altered by growing a beard and mustache. The facial hairstyles in a pair of images can cause marked changes to the impostor distribution and the genuine distribution. Also, different distributions of facial hairstyle across demographics could cause a false impression of relative accuracy across demographics. We first show that, even though larger training sets boost the recognition accuracy on all facial hairstyles, accuracy variations caused by facial hairstyles persist regardless of the size of the training set. Then, we analyze the impact of having different fractions of the training data represent facial hairstyles. We created balanced training sets using a set of identities available in Webface42M that both have clean-shaven and facial hair images. We find that, even when a face recognition model is trained with a balanced clean-shaven / facial hair training set, accuracy variation on the test data does not diminish. Next, data augmentation is employed to further investigate the effect of facial hair distribution in training data by manipulating facial hair pixels with the help of facial landmark points and a facial hair segmentation model. Our results show facial hair causes an accuracy gap between clean-shaven and facial hair images, and this impact can be significantly different between African-Americans and Caucasians.
Beard Segmentation and Recognition Bias
Aug 30, 2023
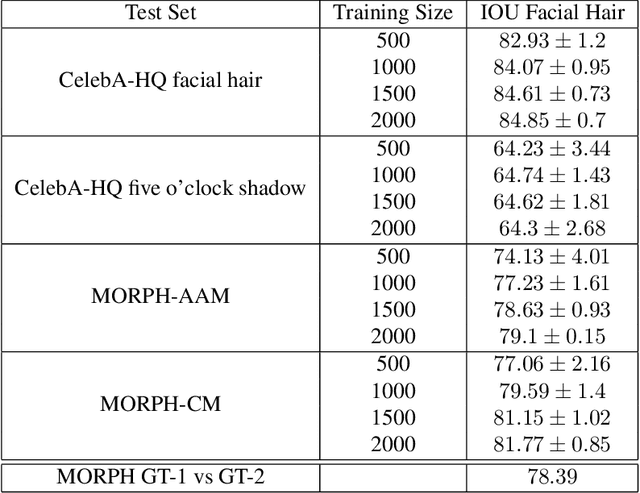

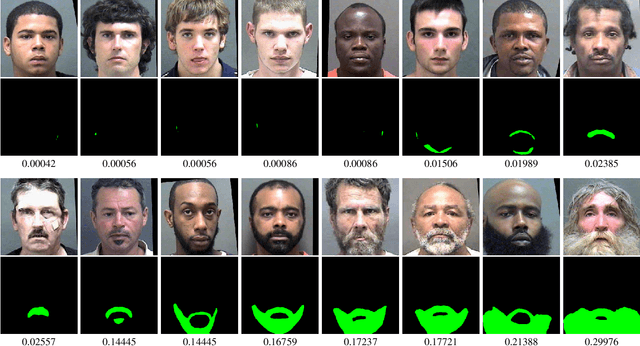
A person's facial hairstyle, such as presence and size of beard, can significantly impact face recognition accuracy. There are publicly-available deep networks that achieve reasonable accuracy at binary attribute classification, such as beard / no beard, but few if any that segment the facial hair region. To investigate the effect of facial hair in a rigorous manner, we first created a set of fine-grained facial hair annotations to train a segmentation model and evaluate its accuracy across African-American and Caucasian face images. We then use our facial hair segmentations to categorize image pairs according to the degree of difference or similarity in the facial hairstyle. We find that the False Match Rate (FMR) for image pairs with different categories of facial hairstyle varies by a factor of over 10 for African-American males and over 25 for Caucasian males. To reduce the bias across image pairs with different facial hairstyles, we propose a scheme for adaptive thresholding based on facial hairstyle similarity. Evaluation on a subject-disjoint set of images shows that adaptive similarity thresholding based on facial hairstyles of the image pair reduces the ratio between the highest and lowest FMR across facial hairstyle categories for African-American from 10.7 to 1.8 and for Caucasians from 25.9 to 1.3. Facial hair annotations and facial hair segmentation model will be publicly available.