 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOOOL: Challenge Of Out-Of-Label A Novel Benchmark for Autonomous Driving
Dec 06, 2024As the Computer Vision community rapidly develops and advances algorithms for autonomous driving systems, the goal of safer and more efficient autonomous transportation is becoming increasingly achievable. However, it is 2024, and we still do not have fully self-driving cars. One of the remaining core challenges lies in addressing the novelty problem, where self-driving systems still struggle to handle previously unseen situations on the open road. With our Challenge of Out-Of-Label (COOOL) benchmark, we introduce a novel dataset for hazard detection, offering versatile evaluation metrics applicable across various tasks, including novelty-adjacent domains such as Anomaly Detection, Open-Set Recognition, Open Vocabulary, and Domain Adaptation. COOOL comprises over 200 collections of dashcam-oriented videos, annotated by human labelers to identify objects of interest and potential driving hazards. It includes a diverse range of hazards and nuisance objects. Due to the dataset's size and data complexity, COOOL serves exclusively as an evaluation benchmark.
Pose2Trajectory: Using Transformers on Body Pose to Predict Tennis Player's Trajectory
Nov 07, 2024Tracking the trajectory of tennis players can help camera operators in production. Predicting future movement enables cameras to automatically track and predict a player's future trajectory without human intervention. Predicting future human movement in the context of complex physical tasks is also intellectually satisfying. Swift advancements in sports analytics and the wide availability of videos for tennis have inspired us to propose a novel method called Pose2Trajectory, which predicts a tennis player's future trajectory as a sequence derived from their body joints' data and ball position. Demonstrating impressive accuracy, our approach capitalizes on body joint information to provide a comprehensive understanding of the human body's geometry and motion, thereby enhancing the prediction of the player's trajectory. We use encoder-decoder Transformer architecture trained on the joints and trajectory information of the players with ball positions. The predicted sequence can provide information to help close-up cameras to keep tracking the tennis player, following centroid coordinates. We generate a high-quality dataset from multiple videos to assist tennis player movement prediction using object detection and human pose estimation methods. It contains bounding boxes and joint information for tennis players and ball positions in singles tennis games. Our method shows promising results in predicting the tennis player's movement trajectory with different sequence prediction lengths using the joints and trajectory information with the ball position.
Consistency and Accuracy of CelebA Attribute Values
Oct 13, 2022
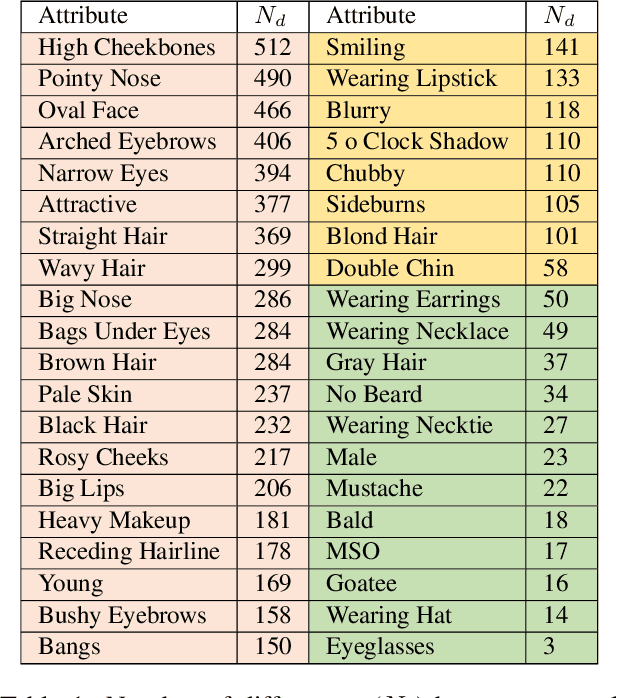

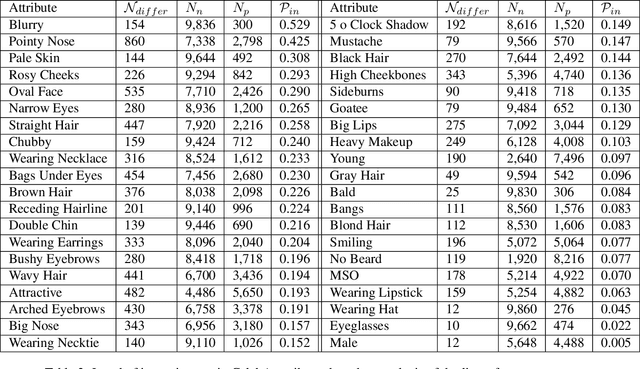
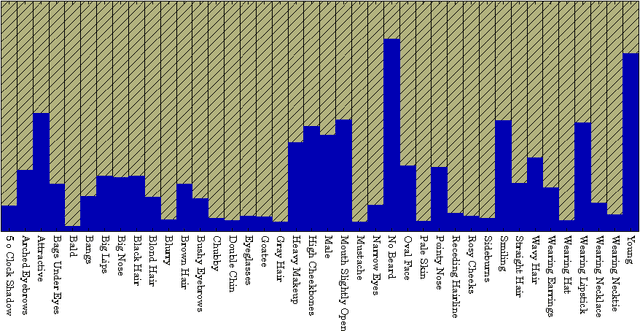
We report the first analysis of the experimental foundations of facial attribute classification. An experiment with two annotators independently assigning values shows that only 12 of 40 commonly-used attributes are assigned values with >= 95% consistency, and that three (high cheekbones, pointed nose, oval face) have random consistency (50%). These results show that the binary face attributes currently used in this research area could re-focused to be more objective. We identify 5,068 duplicate face appearances in CelebA, the most widely used dataset in this research area, and find that individual attributes have contradicting values on from 10 to 860 of 5,068 duplicates. Manual audit of a subset of CelebA estimates error rates as high as 40% for (no beard=false), even though the labeling consistency experiment indicates that no beard could be assigned with >= 95% consistency. Selecting the mouth slightly open (MSO) attribute for deeper analysis, we estimate the error rate for (MSO=true) at about 20% and for (MSO=false) at about 2%. We create a corrected version of the MSO attribute values, and compare classification models created using the original versus corrected values. The corrected values enable a model that achieves higher accuracy than has been previously reported for MSO. Also, ScoreCAM visualizations show that the model created using the corrected attribute values is in fact more focused on the mouth region of the face. These results show that the error rate in the current CelebA attribute values should be reduced in order to enable learning of better models. The corrected attribute values for CelebA's MSO and the CelebA facial hair attributes will be made available upon publication.
Neural Generative Models for 3D Faces with Application in 3D Texture Free Face Recognition
Nov 11, 2018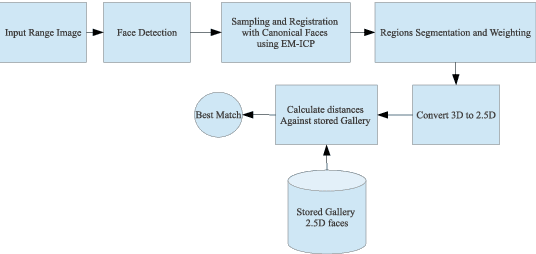
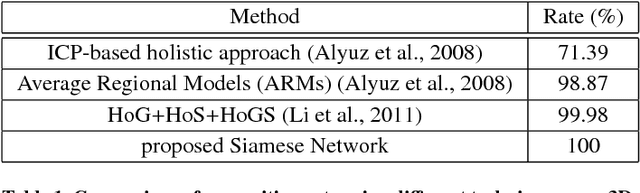
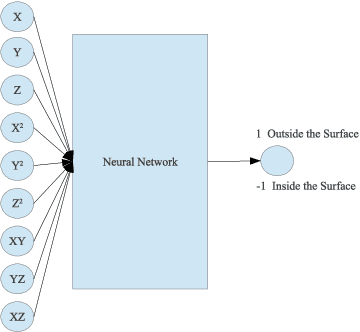
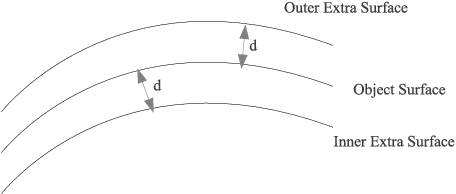
Using heterogeneous depth cameras and 3D scanners in 3D face verification causes variations in the resolution of the 3D point clouds. To solve this issue, previous studies use 3D registration techniques. Out of these proposed techniques, detecting points of correspondence is proven to be an efficient method given that the data belongs to the same individual. However, if the data belongs to different persons, the registration algorithms can convert the 3D point cloud of one person to another, destroying the distinguishing features between the two point clouds. Another issue regarding the storage size of the point clouds. That is, if the captured depth image contains around 50 thousand points in the cloud for a single pose for one individual, then the storage size of the entire dataset will be in order of giga if not tera bytes. With these motivations, this work introduces a new technique for 3D point clouds generation using a neural modeling system to handle the differences caused by heterogeneous depth cameras, and to generate a new face canonical compact representation. The proposed system reduces the stored 3D dataset size, and if required, provides an accurate dataset regeneration. Furthermore, the system generates neural models for all gallery point clouds and stores these models to represent the faces in the recognition or verification processes. For the probe cloud to be verified, a new model is generated specifically for that particular cloud and is matched against pre-stored gallery model presentations to identify the query cloud. This work also introduces the utilization of Siamese deep neural network in 3D face verification using generated model representations as raw data for the deep network, and shows that the accuracy of the trained network is comparable all published results on Bosphorus dataset.
MOON: A Mixed Objective Optimization Network for the Recognition of Facial Attributes
Oct 21, 2016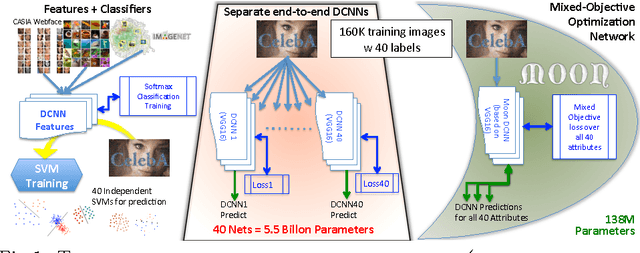
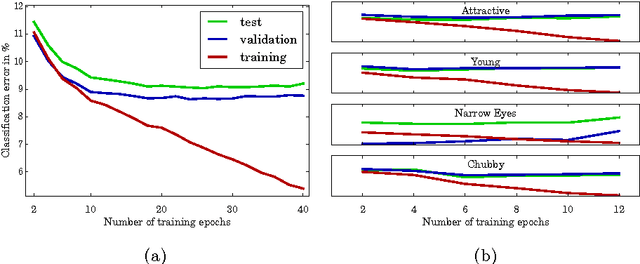
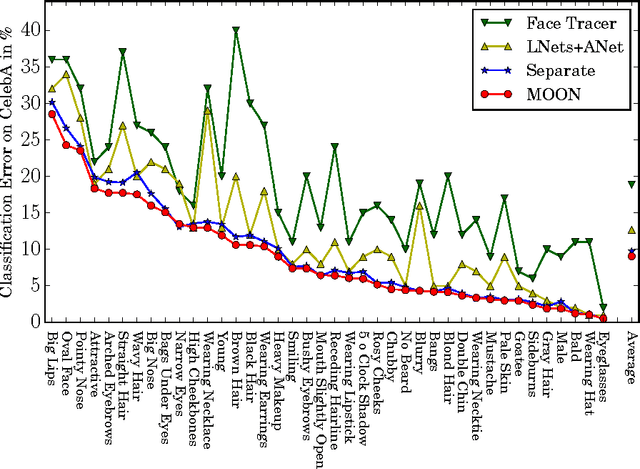
Attribute recognition, particularly facial, extracts many labels for each image. While some multi-task vision problems can be decomposed into separate tasks and stages, e.g., training independent models for each task, for a growing set of problems joint optimization across all tasks has been shown to improve performance. We show that for deep convolutional neural network (DCNN) facial attribute extraction, multi-task optimization is better. Unfortunately, it can be difficult to apply joint optimization to DCNNs when training data is imbalanced, and re-balancing multi-label data directly is structurally infeasible, since adding/removing data to balance one label will change the sampling of the other labels. This paper addresses the multi-label imbalance problem by introducing a novel mixed objective optimization network (MOON) with a loss function that mixes multiple task objectives with domain adaptive re-weighting of propagated loss. Experiments demonstrate that not only does MOON advance the state of the art in facial attribute recognition, but it also outperforms independently trained DCNNs using the same data. When using facial attributes for the LFW face recognition task, we show that our balanced (domain adapted) network outperforms the unbalanced trained network.
Towards Open Set Deep Networks
Nov 19, 2015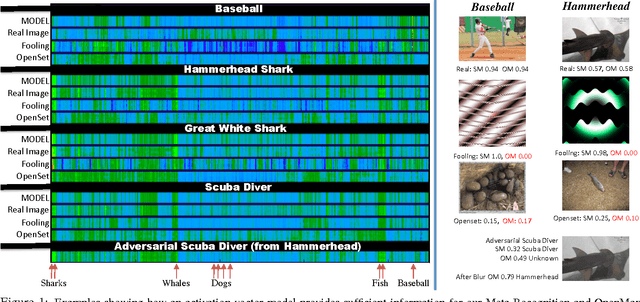
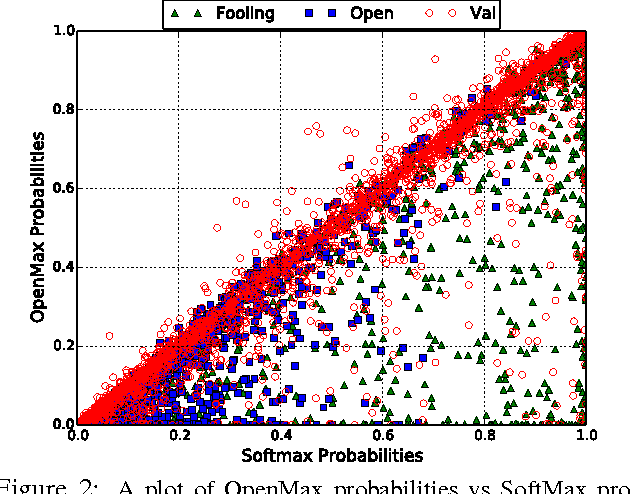
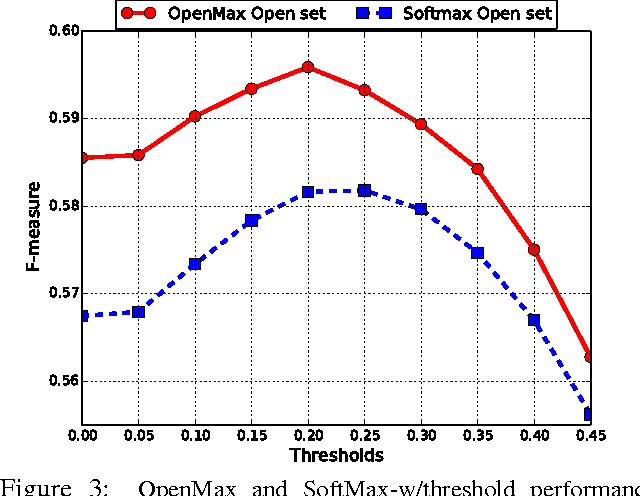
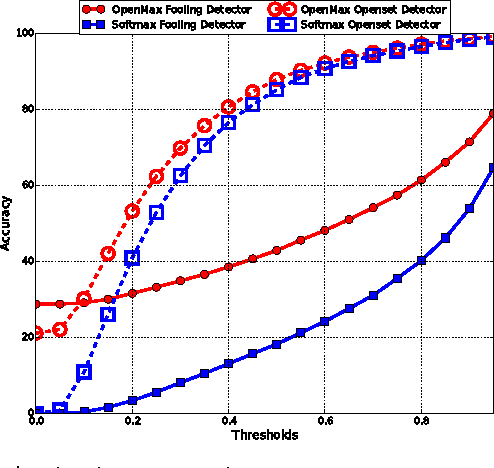
Deep networks have produced significant gains for various visual recognition problems, leading to high impact academic and commercial applications. Recent work in deep networks highlighted that it is easy to generate images that humans would never classify as a particular object class, yet networks classify such images high confidence as that given class - deep network are easily fooled with images humans do not consider meaningful. The closed set nature of deep networks forces them to choose from one of the known classes leading to such artifacts. Recognition in the real world is open set, i.e. the recognition system should reject unknown/unseen classes at test time. We present a methodology to adapt deep networks for open set recognition, by introducing a new model layer, OpenMax, which estimates the probability of an input being from an unknown class. A key element of estimating the unknown probability is adapting Meta-Recognition concepts to the activation patterns in the penultimate layer of the network. OpenMax allows rejection of "fooling" and unrelated open set images presented to the system; OpenMax greatly reduces the number of obvious errors made by a deep network. We prove that the OpenMax concept provides bounded open space risk, thereby formally providing an open set recognition solution. We evaluate the resulting open set deep networks using pre-trained networks from the Caffe Model-zoo on ImageNet 2012 validation data, and thousands of fooling and open set images. The proposed OpenMax model significantly outperforms open set recognition accuracy of basic deep networks as well as deep networks with thresholding of SoftMax probabilities.
Towards Open World Recognition
Dec 18, 2014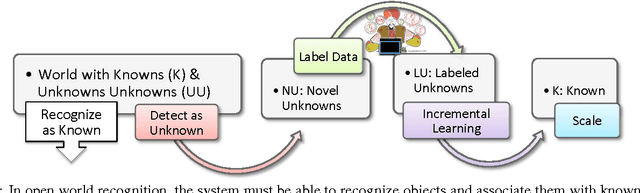
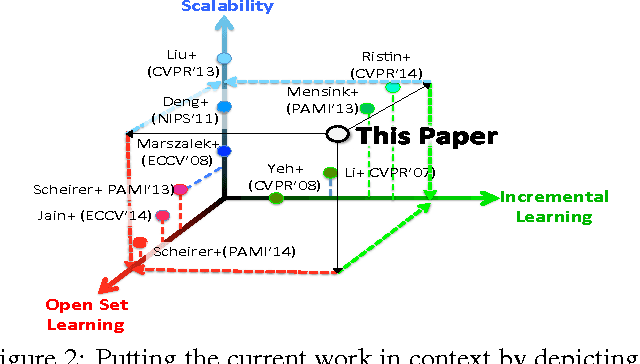
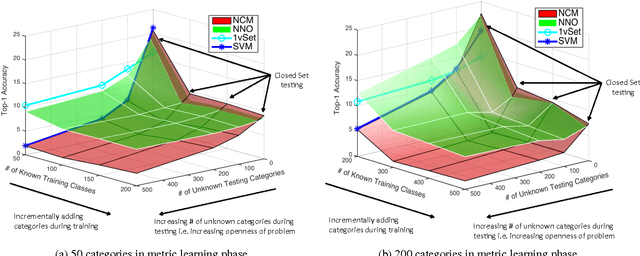
With the of advent rich classification models and high computational power visual recognition systems have found many operational applications. Recognition in the real world poses multiple challenges that are not apparent in controlled lab environments. The datasets are dynamic and novel categories must be continuously detected and then added. At prediction time, a trained system has to deal with myriad unseen categories. Operational systems require minimum down time, even to learn. To handle these operational issues, we present the problem of Open World recognition and formally define it. We prove that thresholding sums of monotonically decreasing functions of distances in linearly transformed feature space can balance "open space risk" and empirical risk. Our theory extends existing algorithms for open world recognition. We present a protocol for evaluation of open world recognition systems. We present the Nearest Non-Outlier (NNO) algorithm which evolves model efficiently, adding object categories incrementally while detecting outliers and managing open space risk. We perform experiments on the ImageNet dataset with 1.2M+ images to validate the effectiveness of our method on large scale visual recognition tasks. NNO consistently yields superior results on open world recognition.