 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCacheFormer: High Attention-Based Segment Caching
Apr 18, 2025Efficiently handling long contexts in transformer-based language models with low perplexity is an active area of research. Numerous recent approaches like Linformer, Longformer, Performer, and Structured state space models (SSMs)., have not fully resolved this problem. All these models strive to reduce the quadratic time complexity of the attention mechanism while minimizing the loss in quality due to the effective compression of the long context. Inspired by the cache and virtual memory principle in computers, where in case of a cache miss, not only the needed data is retrieved from the memory, but the adjacent data is also obtained, we apply this concept to handling long contexts by dividing it into small segments. In our design, we retrieve the nearby segments in an uncompressed form when high segment-level attention occurs at the compressed level. Our en-hancements for handling long context include aggregating four attention mechanisms consisting of short sliding window attention, long compressed segmented attention, dynamically retrieving top k high attention uncompressed segments, and overlapping segments in long segment attention to avoid segment fragmentation. These enhancements result in an architecture that outperforms ex-isting SOTA architectures with an average perplexity improvement of 8.5% over similar model sizes.
Neural Attention: A Novel Mechanism for Enhanced Expressive Power in Transformer Models
Feb 24, 2025

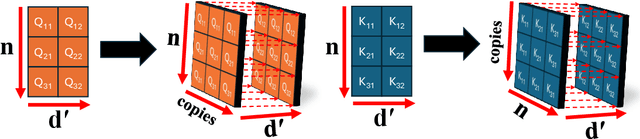

Transformer models typically calculate attention matrices using dot products, which have limitations when capturing nonlinear relationships between embedding vectors. We propose Neural Attention, a technique that replaces dot products with feed-forward networks, enabling a more expressive representation of relationships between tokens. This approach modifies only the attention matrix calculation while preserving the matrix dimensions, making it easily adaptable to existing transformer-based architectures. We provide a detailed mathematical justification for why Neural Attention increases representational capacity and conduct controlled experiments to validate this claim. When comparing Neural Attention and Dot-Product Attention, NLP experiments on WikiText-103 show a reduction in perplexity of over 5 percent. Similarly, experiments on CIFAR-10 and CIFAR-100 show comparable improvements for image classification tasks. While Neural Attention introduces higher computational demands, we develop techniques to mitigate these challenges, ensuring practical usability without sacrificing the increased expressivity it provides. This work establishes Neural Attention as an effective means of enhancing the predictive capabilities of transformer models across a variety of applications.
xLSTMTime : Long-term Time Series Forecasting With xLSTM
Jul 14, 2024
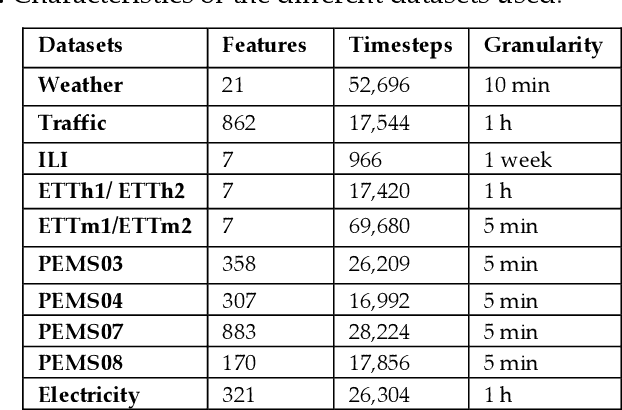


In recent years, transformer-based models have gained prominence in multivariate long-term time series forecasting (LTSF), demonstrating significant advancements despite facing challenges such as high computational demands, difficulty in capturing temporal dynamics, and managing long-term dependencies. The emergence of LTSF-Linear, with its straightforward linear architecture, has notably outperformed transformer-based counterparts, prompting a reevaluation of the transformer's utility in time series forecasting. In response, this paper presents an adaptation of a recent architecture termed extended LSTM (xLSTM) for LTSF. xLSTM incorporates exponential gating and a revised memory structure with higher capacity that has good potential for LTSF. Our adopted architecture for LTSF termed as xLSTMTime surpasses current approaches. We compare xLSTMTime's performance against various state-of-the-art models across multiple real-world da-tasets, demonstrating superior forecasting capabilities. Our findings suggest that refined recurrent architectures can offer competitive alternatives to transformer-based models in LTSF tasks, po-tentially redefining the landscape of time series forecasting.
Neural Generative Models for 3D Faces with Application in 3D Texture Free Face Recognition
Nov 11, 2018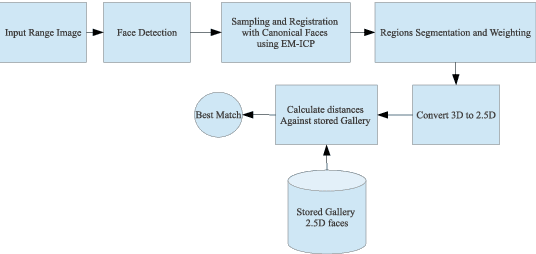
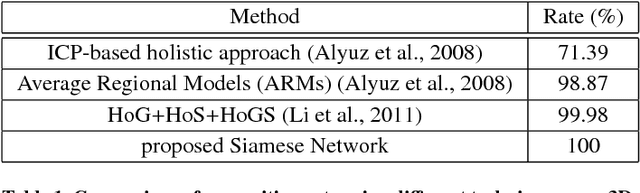
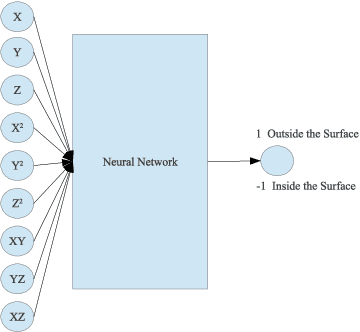
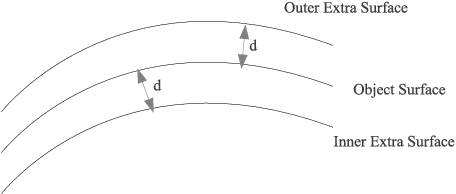
Using heterogeneous depth cameras and 3D scanners in 3D face verification causes variations in the resolution of the 3D point clouds. To solve this issue, previous studies use 3D registration techniques. Out of these proposed techniques, detecting points of correspondence is proven to be an efficient method given that the data belongs to the same individual. However, if the data belongs to different persons, the registration algorithms can convert the 3D point cloud of one person to another, destroying the distinguishing features between the two point clouds. Another issue regarding the storage size of the point clouds. That is, if the captured depth image contains around 50 thousand points in the cloud for a single pose for one individual, then the storage size of the entire dataset will be in order of giga if not tera bytes. With these motivations, this work introduces a new technique for 3D point clouds generation using a neural modeling system to handle the differences caused by heterogeneous depth cameras, and to generate a new face canonical compact representation. The proposed system reduces the stored 3D dataset size, and if required, provides an accurate dataset regeneration. Furthermore, the system generates neural models for all gallery point clouds and stores these models to represent the faces in the recognition or verification processes. For the probe cloud to be verified, a new model is generated specifically for that particular cloud and is matched against pre-stored gallery model presentations to identify the query cloud. This work also introduces the utilization of Siamese deep neural network in 3D face verification using generated model representations as raw data for the deep network, and shows that the accuracy of the trained network is comparable all published results on Bosphorus dataset.
Effect of Super Resolution on High Dimensional Features for Unsupervised Face Recognition in the Wild
May 13, 2017

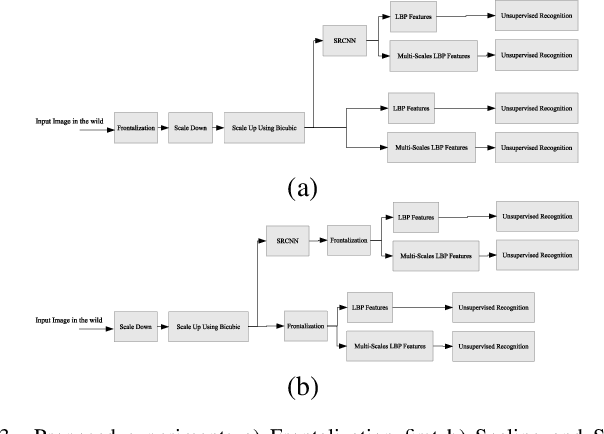
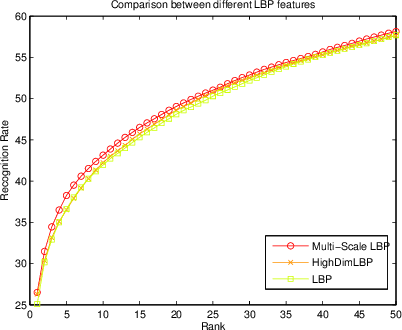
Majority of the face recognition algorithms use query faces captured from uncontrolled, in the wild, environment. Often caused by the cameras limited capabilities, it is common for these captured facial images to be blurred or low resolution. Super resolution algorithms are therefore crucial in improving the resolution of such images especially when the image size is small requiring enlargement. This paper aims to demonstrate the effect of one of the state-of-the-art algorithms in the field of image super resolution. To demonstrate the functionality of the algorithm, various before and after 3D face alignment cases are provided using the images from the Labeled Faces in the Wild (lfw). Resulting images are subject to testing on a closed set face recognition protocol using unsupervised algorithms with high dimension extracted features. The inclusion of super resolution algorithm resulted in significant improved recognition rate over recently reported results obtained from unsupervised algorithms.
Highly Scalable, Parallel and Distributed AdaBoost Algorithm using Light Weight Threads and Web Services on a Network of Multi-Core Machines
Jun 06, 2013

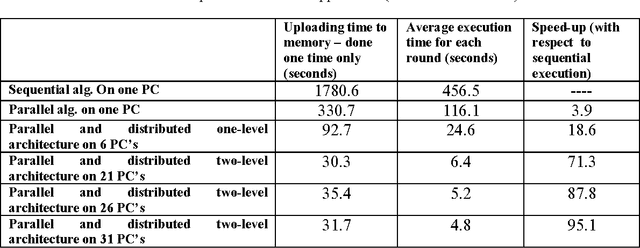
AdaBoost is an important algorithm in machine learning and is being widely used in object detection. AdaBoost works by iteratively selecting the best amongst weak classifiers, and then combines several weak classifiers to obtain a strong classifier. Even though AdaBoost has proven to be very effective, its learning execution time can be quite large depending upon the application e.g., in face detection, the learning time can be several days. Due to its increasing use in computer vision applications, the learning time needs to be drastically reduced so that an adaptive near real time object detection system can be incorporated. In this paper, we develop a hybrid parallel and distributed AdaBoost algorithm that exploits the multiple cores in a CPU via light weight threads, and also uses multiple machines via a web service software architecture to achieve high scalability. We present a novel hierarchical web services based distributed architecture and achieve nearly linear speedup up to the number of processors available to us. In comparison with the previously published work, which used a single level master-slave parallel and distributed implementation [1] and only achieved a speedup of 2.66 on four nodes, we achieve a speedup of 95.1 on 31 workstations each having a quad-core processor, resulting in a learning time of only 4.8 seconds per feature.