 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Feature Attenuation to NLP
Jan 02, 2026Transformer classifiers such as BERT deliver impressive closed-set accuracy, yet they remain brittle when confronted with inputs from unseen categories--a common scenario for deployed NLP systems. We investigate Open-Set Recognition (OSR) for text by porting the feature attenuation hypothesis from computer vision to transformers and by benchmarking it against state-of-the-art baselines. Concretely, we adapt the COSTARR framework--originally designed for classification in computer vision--to two modest language models (BERT (base) and GPT-2) trained to label 176 arXiv subject areas. Alongside COSTARR, we evaluate Maximum Softmax Probability (MSP), MaxLogit, and the temperature-scaled free-energy score under the OOSA and AUOSCR metrics. Our results show (i) COSTARR extends to NLP without retraining but yields no statistically significant gain over MaxLogit or MSP, and (ii) free-energy lags behind all other scores in this high-class-count setting. The study highlights both the promise and the current limitations of transplanting vision-centric OSR ideas to language models, and points toward the need for larger backbones and task-tailored attenuation strategies.
GHOST: Gaussian Hypothesis Open-Set Technique
Feb 05, 2025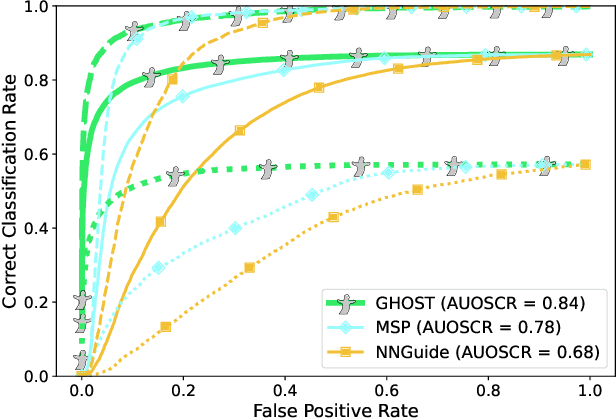

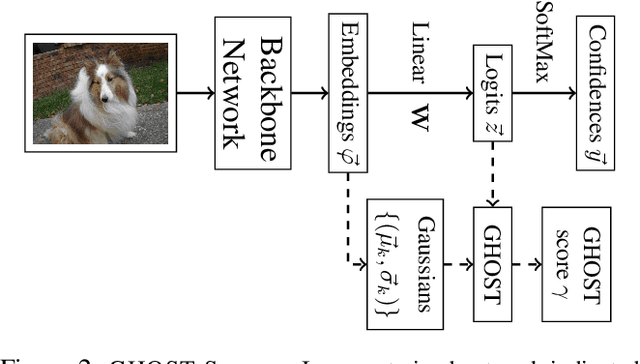
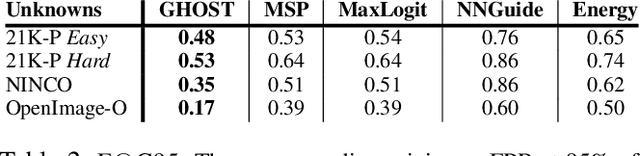
Evaluations of large-scale recognition methods typically focus on overall performance. While this approach is common, it often fails to provide insights into performance across individual classes, which can lead to fairness issues and misrepresentation. Addressing these gaps is crucial for accurately assessing how well methods handle novel or unseen classes and ensuring a fair evaluation. To address fairness in Open-Set Recognition (OSR), we demonstrate that per-class performance can vary dramatically. We introduce Gaussian Hypothesis Open Set Technique (GHOST), a novel hyperparameter-free algorithm that models deep features using class-wise multivariate Gaussian distributions with diagonal covariance matrices. We apply Z-score normalization to logits to mitigate the impact of feature magnitudes that deviate from the model's expectations, thereby reducing the likelihood of the network assigning a high score to an unknown sample. We evaluate GHOST across multiple ImageNet-1K pre-trained deep networks and test it with four different unknown datasets. Using standard metrics such as AUOSCR, AUROC and FPR95, we achieve statistically significant improvements, advancing the state-of-the-art in large-scale OSR. Source code is provided online.
COOOL: Challenge Of Out-Of-Label A Novel Benchmark for Autonomous Driving
Dec 06, 2024As the Computer Vision community rapidly develops and advances algorithms for autonomous driving systems, the goal of safer and more efficient autonomous transportation is becoming increasingly achievable. However, it is 2024, and we still do not have fully self-driving cars. One of the remaining core challenges lies in addressing the novelty problem, where self-driving systems still struggle to handle previously unseen situations on the open road. With our Challenge of Out-Of-Label (COOOL) benchmark, we introduce a novel dataset for hazard detection, offering versatile evaluation metrics applicable across various tasks, including novelty-adjacent domains such as Anomaly Detection, Open-Set Recognition, Open Vocabulary, and Domain Adaptation. COOOL comprises over 200 collections of dashcam-oriented videos, annotated by human labelers to identify objects of interest and potential driving hazards. It includes a diverse range of hazards and nuisance objects. Due to the dataset's size and data complexity, COOOL serves exclusively as an evaluation benchmark.
Enhanced Performance of Pre-Trained Networks by Matched Augmentation Distributions
Jan 19, 2022
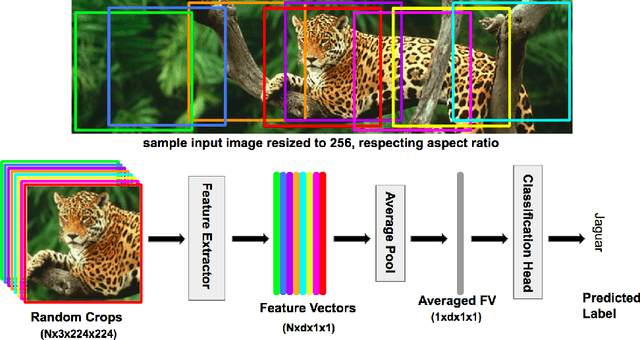
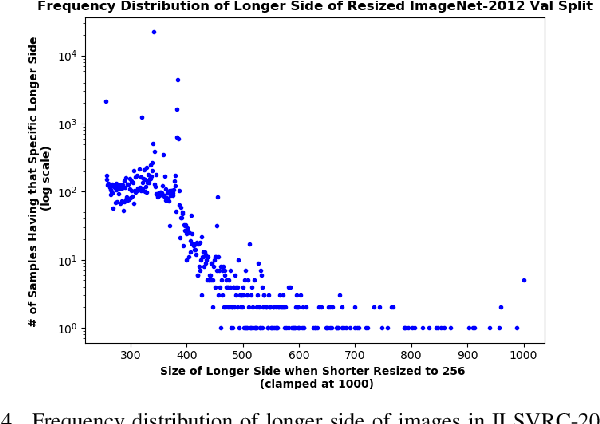
There exists a distribution discrepancy between training and testing, in the way images are fed to modern CNNs. Recent work tried to bridge this gap either by fine-tuning or re-training the network at different resolutions. However re-training a network is rarely cheap and not always viable. To this end, we propose a simple solution to address the train-test distributional shift and enhance the performance of pre-trained models -- which commonly ship as a package with deep learning platforms \eg, PyTorch. Specifically, we demonstrate that running inference on the center crop of an image is not always the best as important discriminatory information may be cropped-off. Instead we propose to combine results for multiple random crops for a test image. This not only matches the train time augmentation but also provides the full coverage of the input image. We explore combining representation of random crops through averaging at different levels \ie, deep feature level, logit level, and softmax level. We demonstrate that, for various families of modern deep networks, such averaging results in better validation accuracy compared to using a single central crop per image. The softmax averaging results in the best performance for various pre-trained networks without requiring any re-training or fine-tuning whatsoever. On modern GPUs with batch processing, the paper's approach to inference of pre-trained networks, is essentially free as all images in a batch can all be processed at once.