 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGHOST: Gaussian Hypothesis Open-Set Technique
Feb 05, 2025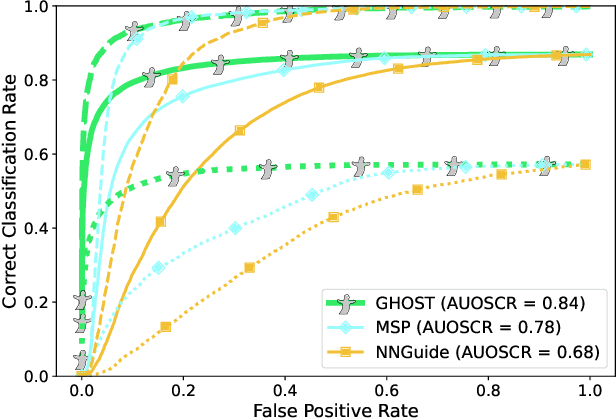

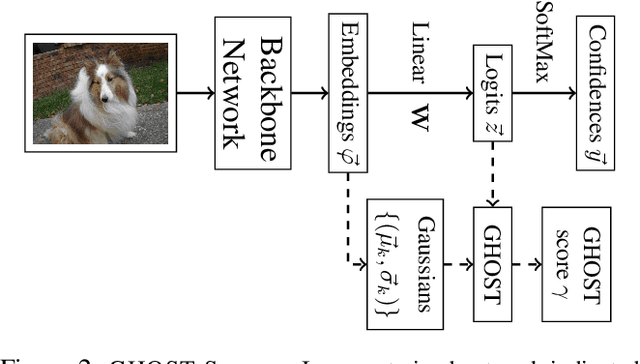
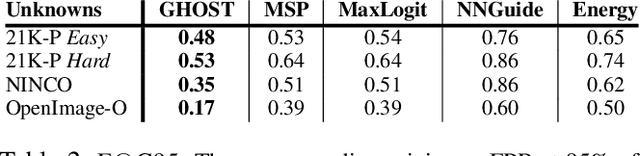
Evaluations of large-scale recognition methods typically focus on overall performance. While this approach is common, it often fails to provide insights into performance across individual classes, which can lead to fairness issues and misrepresentation. Addressing these gaps is crucial for accurately assessing how well methods handle novel or unseen classes and ensuring a fair evaluation. To address fairness in Open-Set Recognition (OSR), we demonstrate that per-class performance can vary dramatically. We introduce Gaussian Hypothesis Open Set Technique (GHOST), a novel hyperparameter-free algorithm that models deep features using class-wise multivariate Gaussian distributions with diagonal covariance matrices. We apply Z-score normalization to logits to mitigate the impact of feature magnitudes that deviate from the model's expectations, thereby reducing the likelihood of the network assigning a high score to an unknown sample. We evaluate GHOST across multiple ImageNet-1K pre-trained deep networks and test it with four different unknown datasets. Using standard metrics such as AUOSCR, AUROC and FPR95, we achieve statistically significant improvements, advancing the state-of-the-art in large-scale OSR. Source code is provided online.
Enhanced Performance of Pre-Trained Networks by Matched Augmentation Distributions
Jan 19, 2022
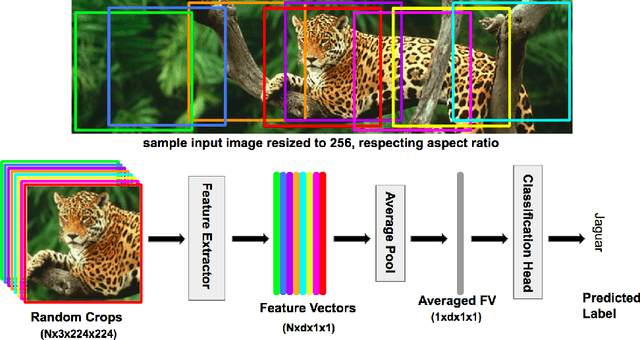
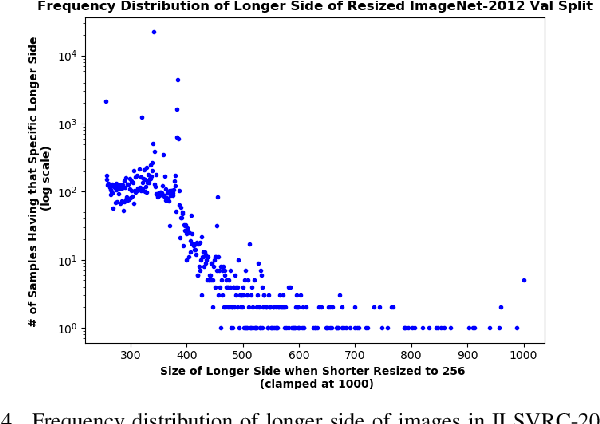
There exists a distribution discrepancy between training and testing, in the way images are fed to modern CNNs. Recent work tried to bridge this gap either by fine-tuning or re-training the network at different resolutions. However re-training a network is rarely cheap and not always viable. To this end, we propose a simple solution to address the train-test distributional shift and enhance the performance of pre-trained models -- which commonly ship as a package with deep learning platforms \eg, PyTorch. Specifically, we demonstrate that running inference on the center crop of an image is not always the best as important discriminatory information may be cropped-off. Instead we propose to combine results for multiple random crops for a test image. This not only matches the train time augmentation but also provides the full coverage of the input image. We explore combining representation of random crops through averaging at different levels \ie, deep feature level, logit level, and softmax level. We demonstrate that, for various families of modern deep networks, such averaging results in better validation accuracy compared to using a single central crop per image. The softmax averaging results in the best performance for various pre-trained networks without requiring any re-training or fine-tuning whatsoever. On modern GPUs with batch processing, the paper's approach to inference of pre-trained networks, is essentially free as all images in a batch can all be processed at once.
Open-World Learning Without Labels
Dec 14, 2020

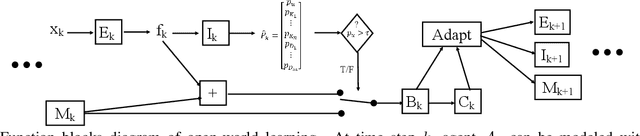
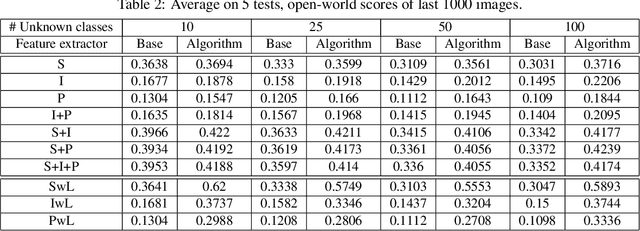
Open-world learning is a problem where an autonomous agent detects things that it does not know and learns them over time from a non-stationary and never-ending stream of data; in an open-world environment, the training data and objective criteria are never available at once. The agent should grasp new knowledge from learning without forgetting acquired prior knowledge. Researchers proposed a few open-world learning agents for image classification tasks that operate in complex scenarios. However, all prior work on open-world learning has all labeled data to learn the new classes from the stream of images. In scenarios where autonomous agents should respond in near real-time or work in areas with limited communication infrastructure, human labeling of data is not possible. Therefore, supervised open-world learning agents are not scalable solutions for such applications. Herein, we propose a new framework that enables agents to learn new classes from a stream of unlabeled data in an unsupervised manner. Also, we study the robustness and learning speed of such agents with supervised and unsupervised feature representation. We also introduce a new metric for open-world learning without labels. We anticipate our theories and method to be a starting point for developing autonomous true open-world never-ending learning agents.
Automatic Open-World Reliability Assessment
Nov 11, 2020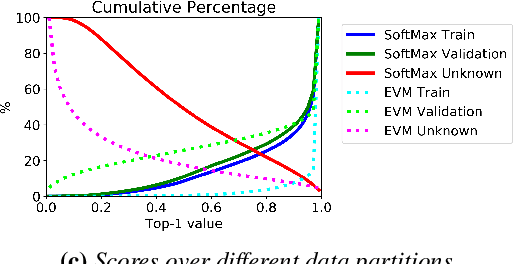
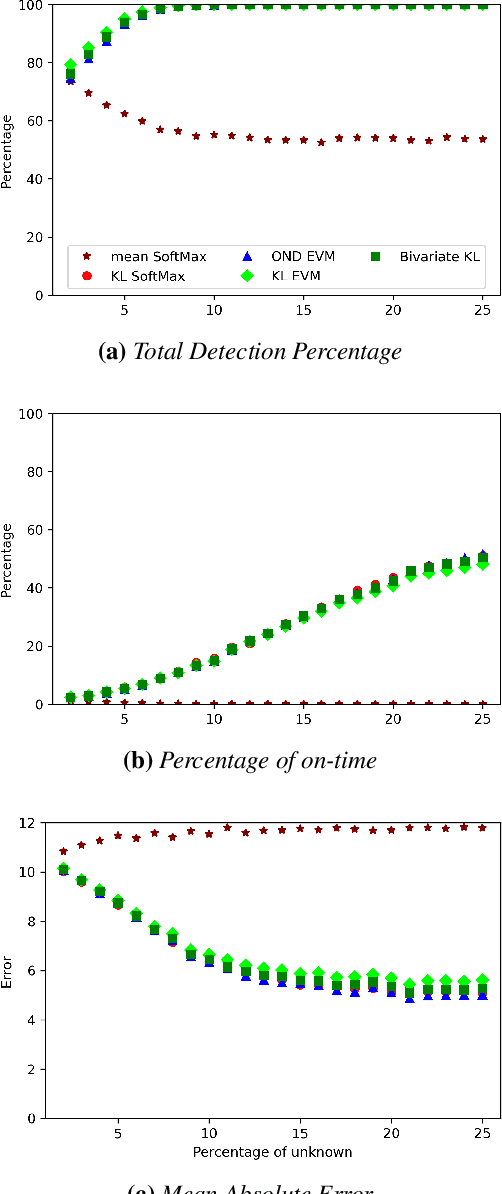
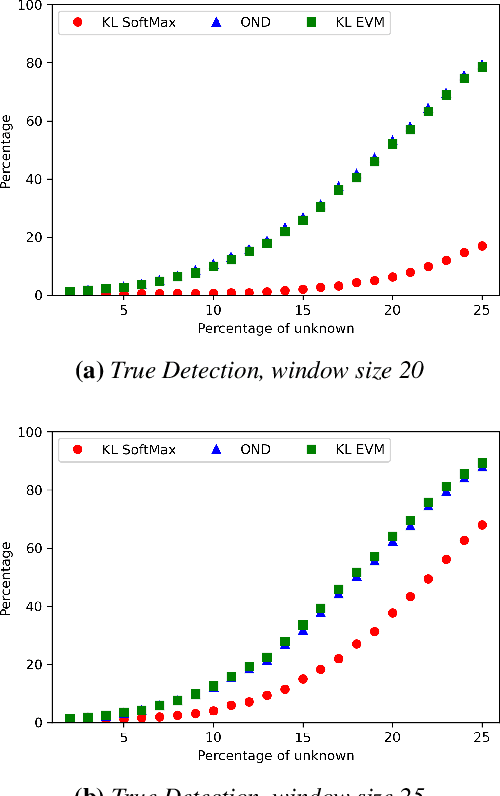
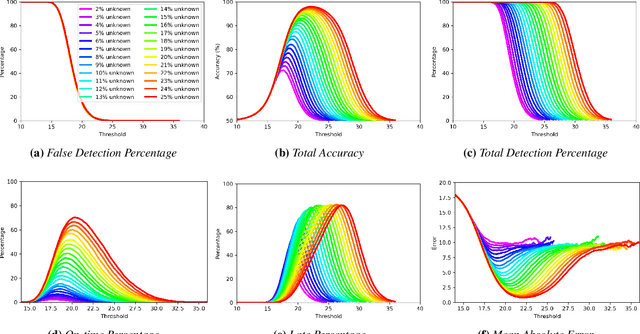
Image classification in the open-world must handle out-of-distribution (OOD) images. Systems should ideally reject OOD images, or they will map atop of known classes and reduce reliability. Using open-set classifiers that can reject OOD inputs can help. However, optimal accuracy of open-set classifiers depend on the frequency of OOD data. Thus, for either standard or open-set classifiers, it is important to be able to determine when the world changes and increasing OOD inputs will result in reduced system reliability. However, during operations, we cannot directly assess accuracy as there are no labels. Thus, the reliability assessment of these classifiers must be done by human operators, made more complex because networks are not 100% accurate, so some failures are to be expected. To automate this process, herein, we formalize the open-world recognition reliability problem and propose multiple automatic reliability assessment policies to address this new problem using only the distribution of reported scores/probability data. The distributional algorithms can be applied to both classic classifiers with SoftMax as well as the open-world Extreme Value Machine (EVM) to provide automated reliability assessment. We show that all of the new algorithms significantly outperform detection using the mean of SoftMax.
* 2021 IEEE Winter Conference on Applications of Computer Vision (WACV)
To Beta or Not To Beta: Information Bottleneck for DigitaL Image Forensics
Aug 11, 2019
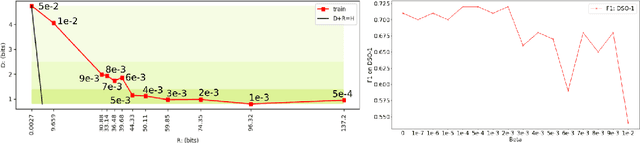

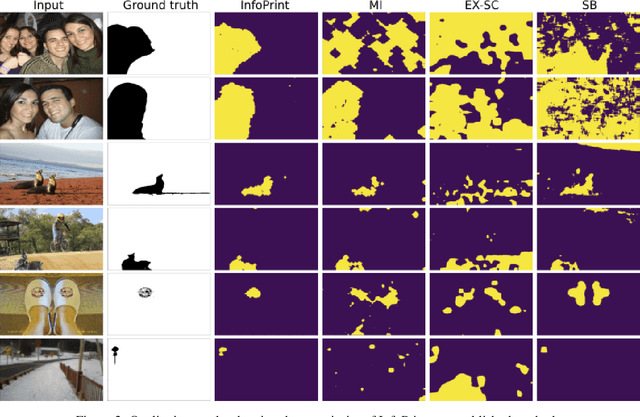
We consider an information theoretic approach to address the problem of identifying fake digital images. We propose an innovative method to formulate the issue of localizing manipulated regions in an image as a deep representation learning problem using the Information Bottleneck (IB), which has recently gained popularity as a framework for interpreting deep neural networks. Tampered images pose a serious predicament since digitized media is a ubiquitous part of our lives. These are facilitated by the easy availability of image editing software and aggravated by recent advances in deep generative models such as GANs. We propose InfoPrint, a computationally efficient solution to the IB formulation using approximate variational inference and compare it to a numerical solution that is computationally expensive. Testing on a number of standard datasets, we demonstrate that InfoPrint outperforms the state-of-the-art and the numerical solution. Additionally, it also has the ability to detect alterations made by inpainting GANs.
Toward Open-Set Face Recognition
May 19, 2017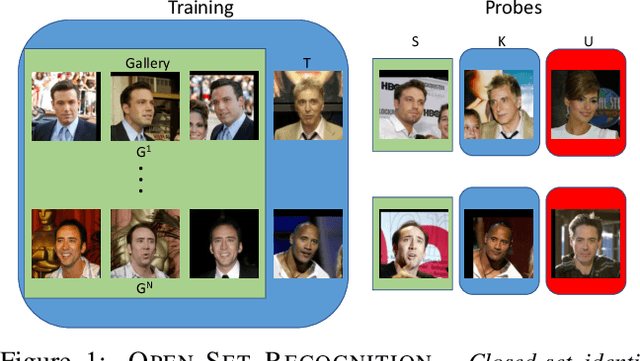
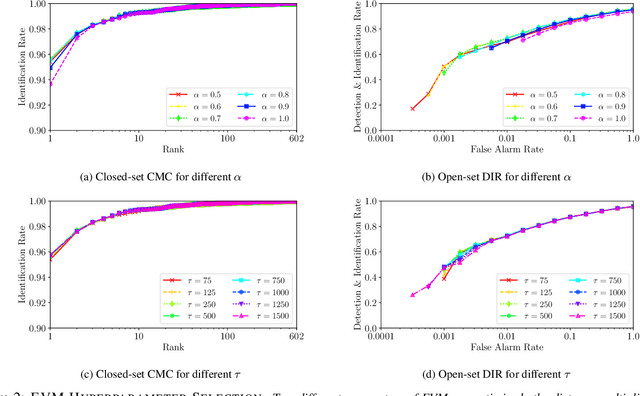
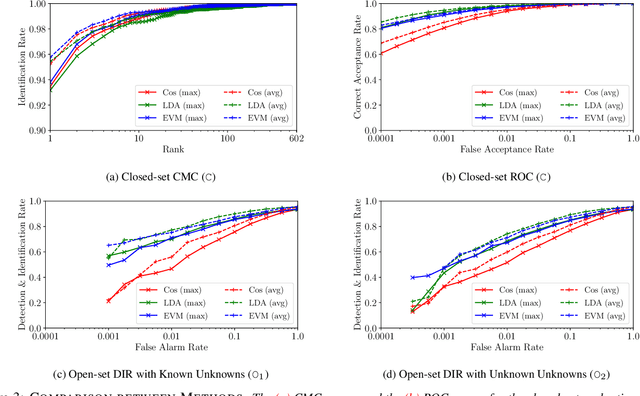
Much research has been conducted on both face identification and face verification, with greater focus on the latter. Research on face identification has mostly focused on using closed-set protocols, which assume that all probe images used in evaluation contain identities of subjects that are enrolled in the gallery. Real systems, however, where only a fraction of probe sample identities are enrolled in the gallery, cannot make this closed-set assumption. Instead, they must assume an open set of probe samples and be able to reject/ignore those that correspond to unknown identities. In this paper, we address the widespread misconception that thresholding verification-like scores is a good way to solve the open-set face identification problem, by formulating an open-set face identification protocol and evaluating different strategies for assessing similarity. Our open-set identification protocol is based on the canonical labeled faces in the wild (LFW) dataset. Additionally to the known identities, we introduce the concepts of known unknowns (known, but uninteresting persons) and unknown unknowns (people never seen before) to the biometric community. We compare three algorithms for assessing similarity in a deep feature space under an open-set protocol: thresholded verification-like scores, linear discriminant analysis (LDA) scores, and an extreme value machine (EVM) probabilities. Our findings suggest that thresholding EVM probabilities, which are open-set by design, outperforms thresholding verification-like scores.