 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Performance of Pre-Trained Networks by Matched Augmentation Distributions
Paper and Code
Jan 19, 2022
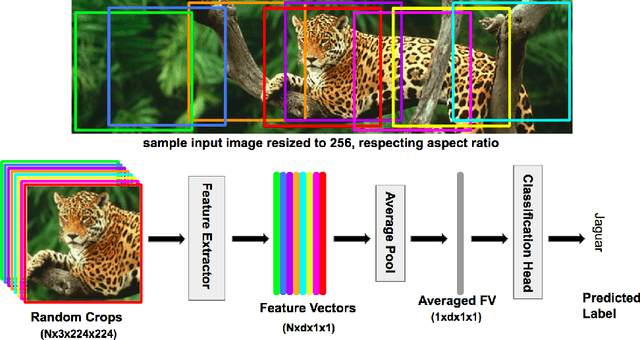
There exists a distribution discrepancy between training and testing, in the way images are fed to modern CNNs. Recent work tried to bridge this gap either by fine-tuning or re-training the network at different resolutions. However re-training a network is rarely cheap and not always viable. To this end, we propose a simple solution to address the train-test distributional shift and enhance the performance of pre-trained models -- which commonly ship as a package with deep learning platforms \eg, PyTorch. Specifically, we demonstrate that running inference on the center crop of an image is not always the best as important discriminatory information may be cropped-off. Instead we propose to combine results for multiple random crops for a test image. This not only matches the train time augmentation but also provides the full coverage of the input image. We explore combining representation of random crops through averaging at different levels \ie, deep feature level, logit level, and softmax level. We demonstrate that, for various families of modern deep networks, such averaging results in better validation accuracy compared to using a single central crop per image. The softmax averaging results in the best performance for various pre-trained networks without requiring any re-training or fine-tuning whatsoever. On modern GPUs with batch processing, the paper's approach to inference of pre-trained networks, is essentially free as all images in a batch can all be processed at once.