 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Performance of Pre-Trained Networks by Matched Augmentation Distributions
Jan 19, 2022
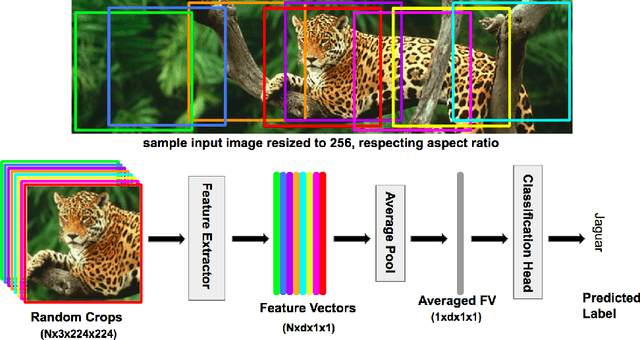
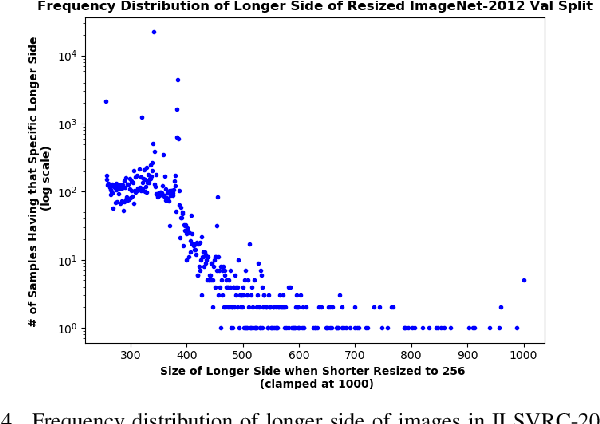
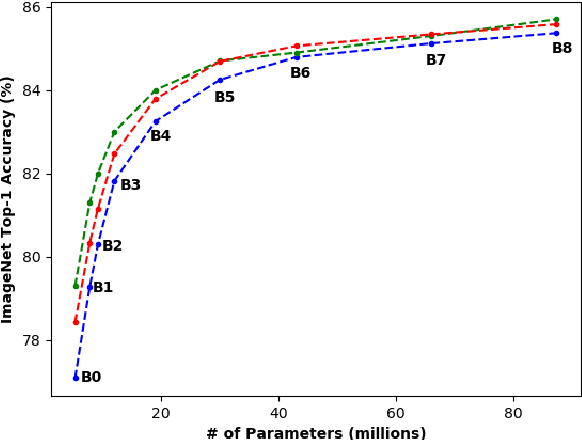
There exists a distribution discrepancy between training and testing, in the way images are fed to modern CNNs. Recent work tried to bridge this gap either by fine-tuning or re-training the network at different resolutions. However re-training a network is rarely cheap and not always viable. To this end, we propose a simple solution to address the train-test distributional shift and enhance the performance of pre-trained models -- which commonly ship as a package with deep learning platforms \eg, PyTorch. Specifically, we demonstrate that running inference on the center crop of an image is not always the best as important discriminatory information may be cropped-off. Instead we propose to combine results for multiple random crops for a test image. This not only matches the train time augmentation but also provides the full coverage of the input image. We explore combining representation of random crops through averaging at different levels \ie, deep feature level, logit level, and softmax level. We demonstrate that, for various families of modern deep networks, such averaging results in better validation accuracy compared to using a single central crop per image. The softmax averaging results in the best performance for various pre-trained networks without requiring any re-training or fine-tuning whatsoever. On modern GPUs with batch processing, the paper's approach to inference of pre-trained networks, is essentially free as all images in a batch can all be processed at once.
A wearable sensor vest for social humanoid robots with GPGPU, IoT, and modular software architecture
Jan 06, 2022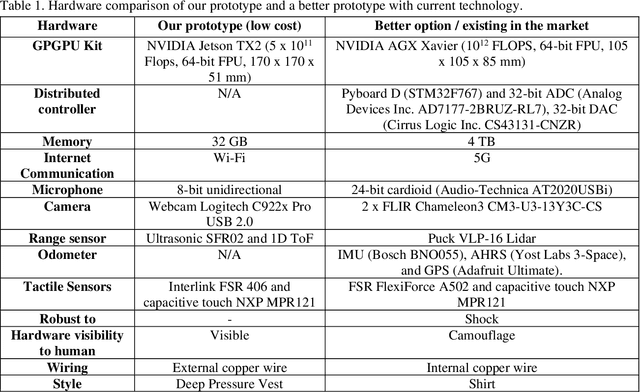
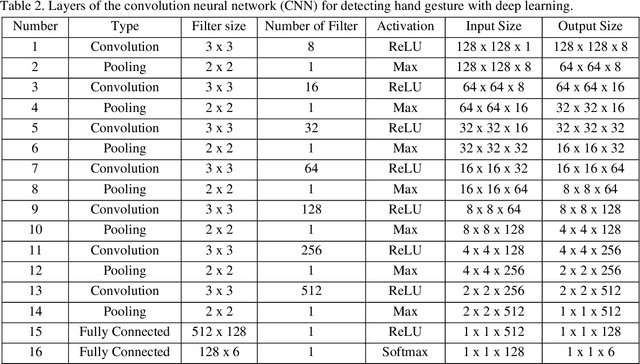
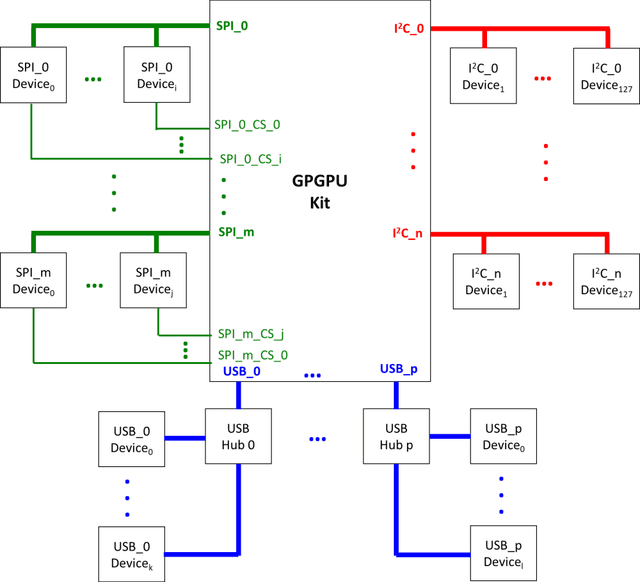
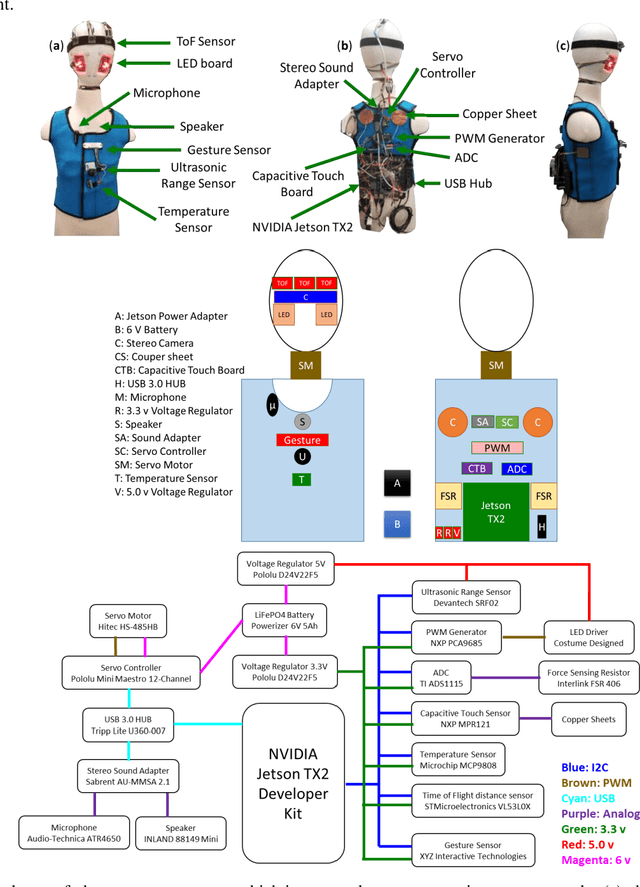
Currently, most social robots interact with their surroundings and humans through sensors that are integral parts of the robots, which limits the usability of the sensors, human-robot interaction, and interchangeability. A wearable sensor garment that fits many robots is needed in many applications. This article presents an affordable wearable sensor vest, and an open-source software architecture with the Internet of Things (IoT) for social humanoid robots. The vest consists of touch, temperature, gesture, distance, vision sensors, and a wireless communication module. The IoT feature allows the robot to interact with humans locally and over the Internet. The designed architecture works for any social robot that has a general-purpose graphics processing unit (GPGPU), I2C/SPI buses, Internet connection, and the Robotics Operating System (ROS). The modular design of this architecture enables developers to easily add/remove/update complex behaviors. The proposed software architecture provides IoT technology, GPGPU nodes, I2C and SPI bus mangers, audio-visual interaction nodes (speech to text, text to speech, and image understanding), and isolation between behavior nodes and other nodes. The proposed IoT solution consists of related nodes in the robot, a RESTful web service, and user interfaces. We used the HTTP protocol as a means of two-way communication with the social robot over the Internet. Developers can easily edit or add nodes in C, C++, and Python programming languages. Our architecture can be used for designing more sophisticated behaviors for social humanoid robots.
* This is the preprint version. The final version is published in Robotics and Autonomous Systems, Volume 139, 2021, Page 103536, ISSN 0921-8890, https://doi.org/10.1016/j.robot.2020.103536
EMG Signal Classification Using Reflection Coefficients and Extreme Value Machine
Jun 19, 2021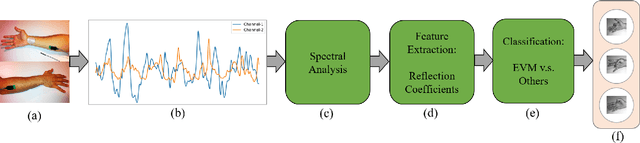
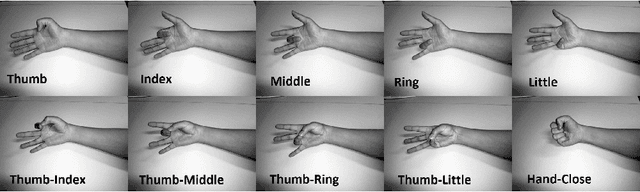
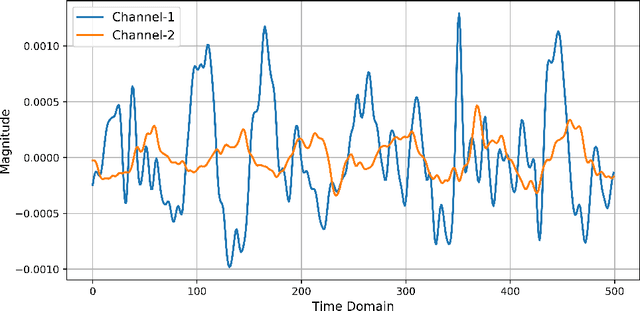
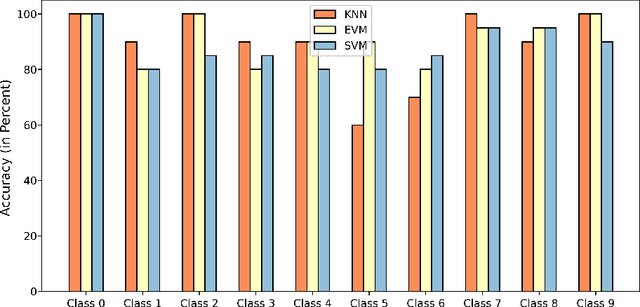
Electromyography is a promising approach to the gesture recognition of humans if an efficient classifier with high accuracy is available. In this paper, we propose to utilize Extreme Value Machine (EVM) as a high-performance algorithm for the classification of EMG signals. We employ reflection coefficients obtained from an Autoregressive (AR) model to train a set of classifiers. Our experimental results indicate that EVM has better accuracy in comparison to the conventional classifiers approved in the literature based on K-Nearest Neighbors (KNN) and Support Vector Machine (SVM).
Self-Supervised Features Improve Open-World Learning
Feb 15, 2021
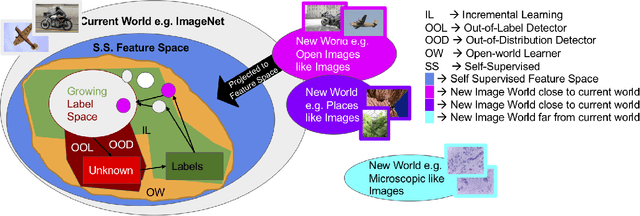
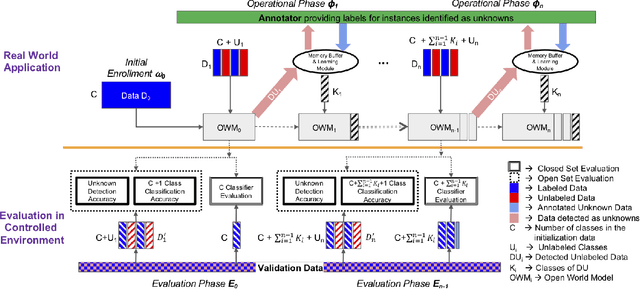
This is a position paper that addresses the problem of Open-World learning while proposing for the underlying feature representation to be learnt using self-supervision. We also present an unifying open-world framework combining three individual research dimensions which have been explored independently \ie Incremental Learning, Out-of-Distribution detection and Open-World learning. We observe that the supervised feature representations are limited and degenerate for the Open-World setting and unsupervised feature representation is native to each of these three problem domains. Under an unsupervised feature representation, we categorize the problem of detecting unknowns as either Out-of-Label-space or Out-of-Distribution detection, depending on the data used during system training versus system testing. The incremental learning component of our pipeline is a zero-exemplar online model which performs comparatively against state-of-the-art on ImageNet-100 protocol and does not require any back-propagation or retraining of the underlying deep-network. It further outperforms the current state-of-the-art by simply using the same number of exemplars as its counterparts. To evaluate our approach for Open-World learning, we propose a new comprehensive protocol and evaluate its performance in both Out-of-Label and Out-of-Distribution settings for each incremental stage. We also demonstrate the adaptability of our approach by showing how it can work as a plug-in with any of the recently proposed self-supervised feature representation methods.
Open-World Learning Without Labels
Dec 14, 2020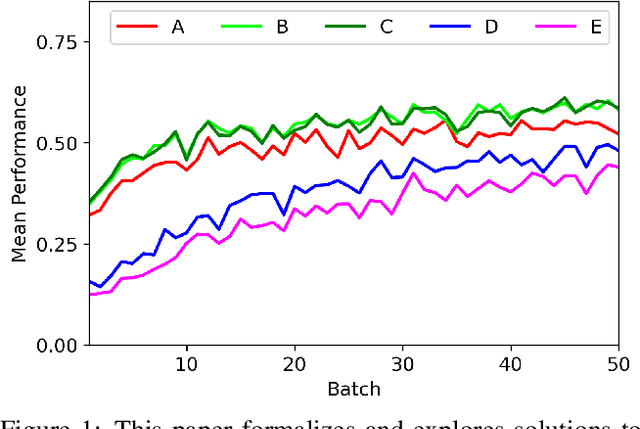

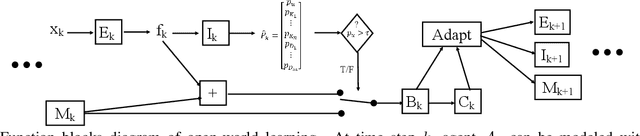
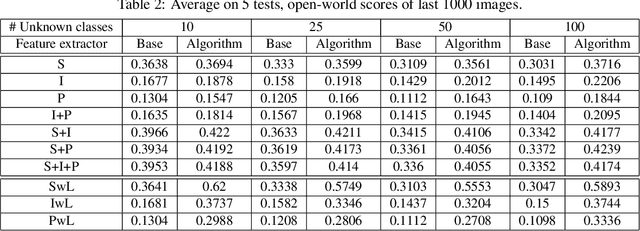
Open-world learning is a problem where an autonomous agent detects things that it does not know and learns them over time from a non-stationary and never-ending stream of data; in an open-world environment, the training data and objective criteria are never available at once. The agent should grasp new knowledge from learning without forgetting acquired prior knowledge. Researchers proposed a few open-world learning agents for image classification tasks that operate in complex scenarios. However, all prior work on open-world learning has all labeled data to learn the new classes from the stream of images. In scenarios where autonomous agents should respond in near real-time or work in areas with limited communication infrastructure, human labeling of data is not possible. Therefore, supervised open-world learning agents are not scalable solutions for such applications. Herein, we propose a new framework that enables agents to learn new classes from a stream of unlabeled data in an unsupervised manner. Also, we study the robustness and learning speed of such agents with supervised and unsupervised feature representation. We also introduce a new metric for open-world learning without labels. We anticipate our theories and method to be a starting point for developing autonomous true open-world never-ending learning agents.
Automatic Open-World Reliability Assessment
Nov 11, 2020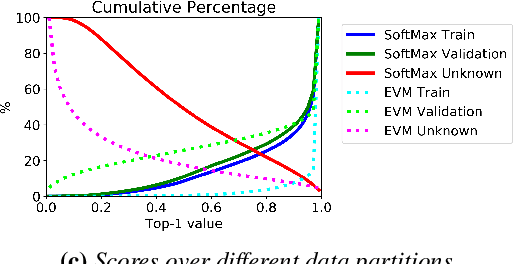
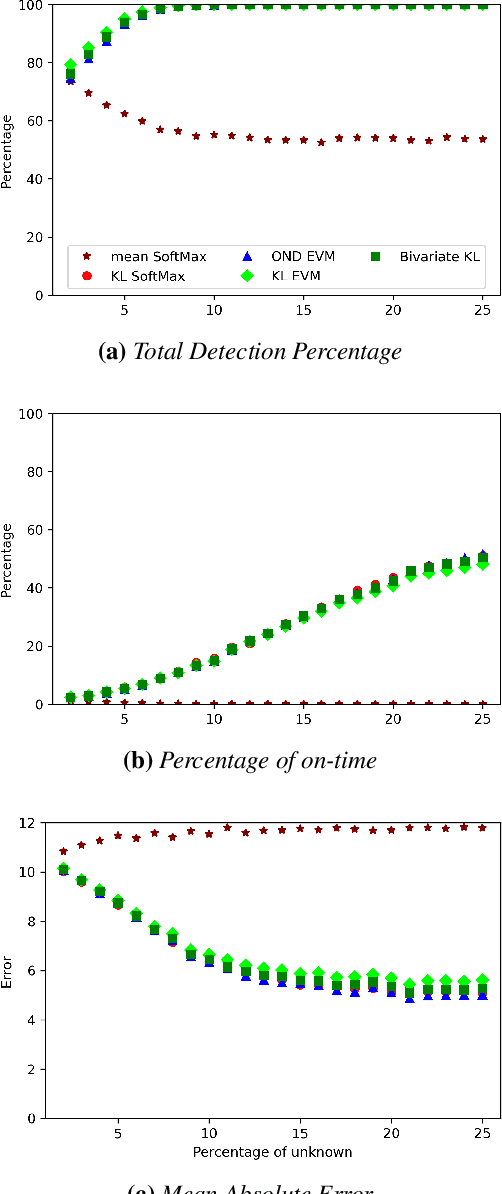
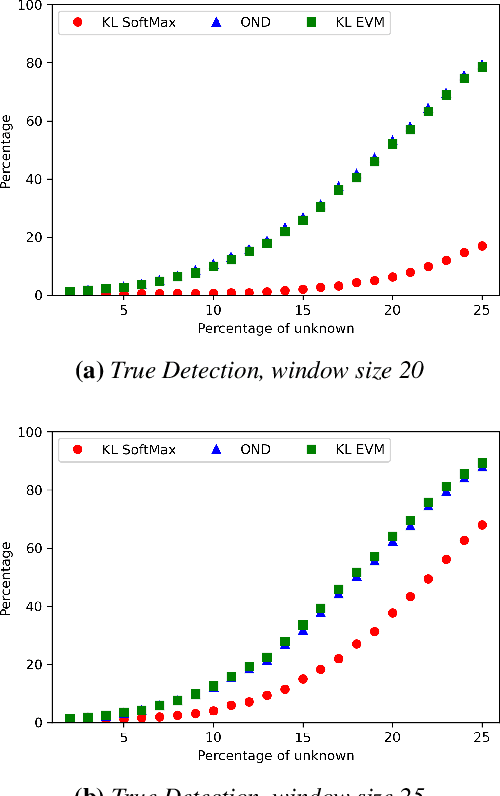
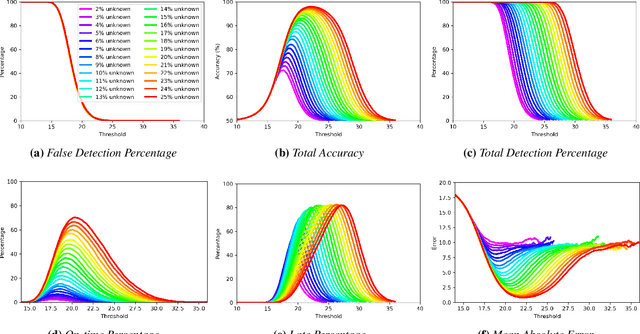
Image classification in the open-world must handle out-of-distribution (OOD) images. Systems should ideally reject OOD images, or they will map atop of known classes and reduce reliability. Using open-set classifiers that can reject OOD inputs can help. However, optimal accuracy of open-set classifiers depend on the frequency of OOD data. Thus, for either standard or open-set classifiers, it is important to be able to determine when the world changes and increasing OOD inputs will result in reduced system reliability. However, during operations, we cannot directly assess accuracy as there are no labels. Thus, the reliability assessment of these classifiers must be done by human operators, made more complex because networks are not 100% accurate, so some failures are to be expected. To automate this process, herein, we formalize the open-world recognition reliability problem and propose multiple automatic reliability assessment policies to address this new problem using only the distribution of reported scores/probability data. The distributional algorithms can be applied to both classic classifiers with SoftMax as well as the open-world Extreme Value Machine (EVM) to provide automated reliability assessment. We show that all of the new algorithms significantly outperform detection using the mean of SoftMax.
* 2021 IEEE Winter Conference on Applications of Computer Vision (WACV)
End-to-End Learning of Speech 2D Feature-Trajectory for Prosthetic Hands
Sep 22, 2020



Speech is one of the most common forms of communication in humans. Speech commands are essential parts of multimodal controlling of prosthetic hands. In the past decades, researchers used automatic speech recognition systems for controlling prosthetic hands by using speech commands. Automatic speech recognition systems learn how to map human speech to text. Then, they used natural language processing or a look-up table to map the estimated text to a trajectory. However, the performance of conventional speech-controlled prosthetic hands is still unsatisfactory. Recent advancements in general-purpose graphics processing units (GPGPUs) enable intelligent devices to run deep neural networks in real-time. Thus, architectures of intelligent systems have rapidly transformed from the paradigm of composite subsystems optimization to the paradigm of end-to-end optimization. In this paper, we propose an end-to-end convolutional neural network (CNN) that maps speech 2D features directly to trajectories for prosthetic hands. The proposed convolutional neural network is lightweight, and thus it runs in real-time in an embedded GPGPU. The proposed method can use any type of speech 2D feature that has local correlations in each dimension such as spectrogram, MFCC, or PNCC. We omit the speech to text step in controlling the prosthetic hand in this paper. The network is written in Python with Keras library that has a TensorFlow backend. We optimized the CNN for NVIDIA Jetson TX2 developer kit. Our experiment on this CNN demonstrates a root-mean-square error of 0.119 and 20ms running time to produce trajectory outputs corresponding to the voice input data. To achieve a lower error in real-time, we can optimize a similar CNN for a more powerful embedded GPGPU such as NVIDIA AGX Xavier.
Convolutional Neural Networks for Speech Controlled Prosthetic Hands
Oct 03, 2019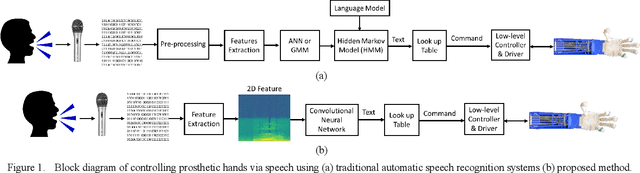
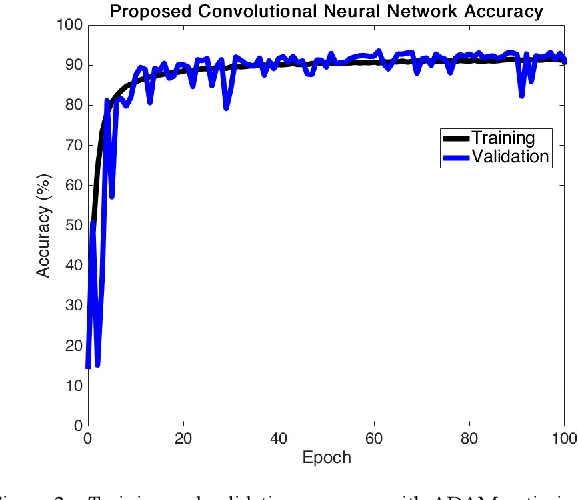
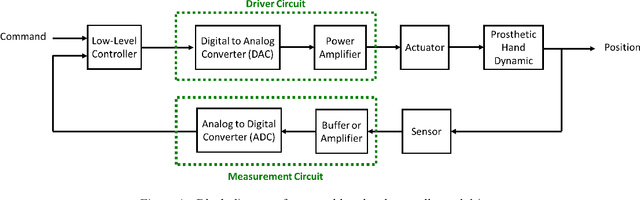
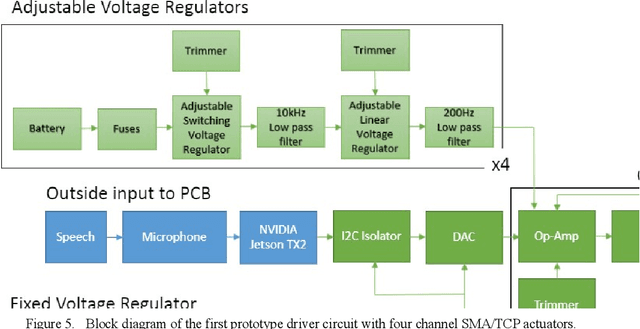
Speech recognition is one of the key topics in artificial intelligence, as it is one of the most common forms of communication in humans. Researchers have developed many speech-controlled prosthetic hands in the past decades, utilizing conventional speech recognition systems that use a combination of neural network and hidden Markov model. Recent advancements in general-purpose graphics processing units (GPGPUs) enable intelligent devices to run deep neural networks in real-time. Thus, state-of-the-art speech recognition systems have rapidly shifted from the paradigm of composite subsystems optimization to the paradigm of end-to-end optimization. However, a low-power embedded GPGPU cannot run these speech recognition systems in real-time. In this paper, we show the development of deep convolutional neural networks (CNN) for speech control of prosthetic hands that run in real-time on a NVIDIA Jetson TX2 developer kit. First, the device captures and converts speech into 2D features (like spectrogram). The CNN receives the 2D features and classifies the hand gestures. Finally, the hand gesture classes are sent to the prosthetic hand motion control system. The whole system is written in Python with Keras, a deep learning library that has a TensorFlow backend. Our experiments on the CNN demonstrate the 91% accuracy and 2ms running time of hand gestures (text output) from speech commands, which can be used to control the prosthetic hands in real-time.
* 2019 First International Conference on Transdisciplinary AI (TransAI), Laguna Hills, California, USA, 2019, pp. 35-42
Deep learning approach to control of prosthetic hands with electromyography signals
Sep 21, 2019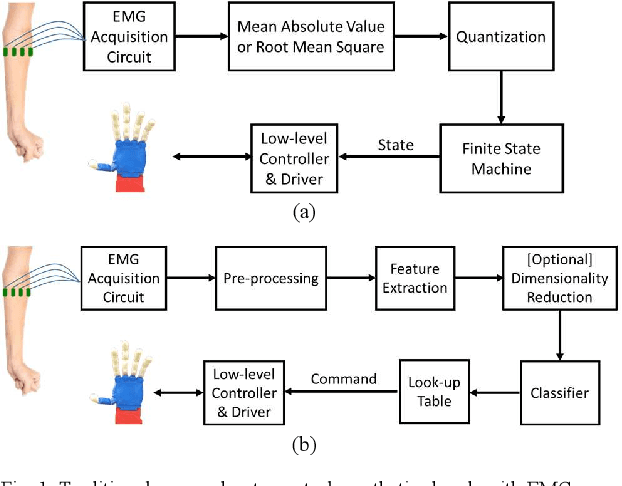
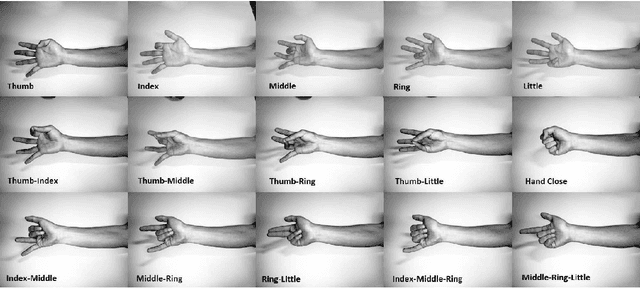
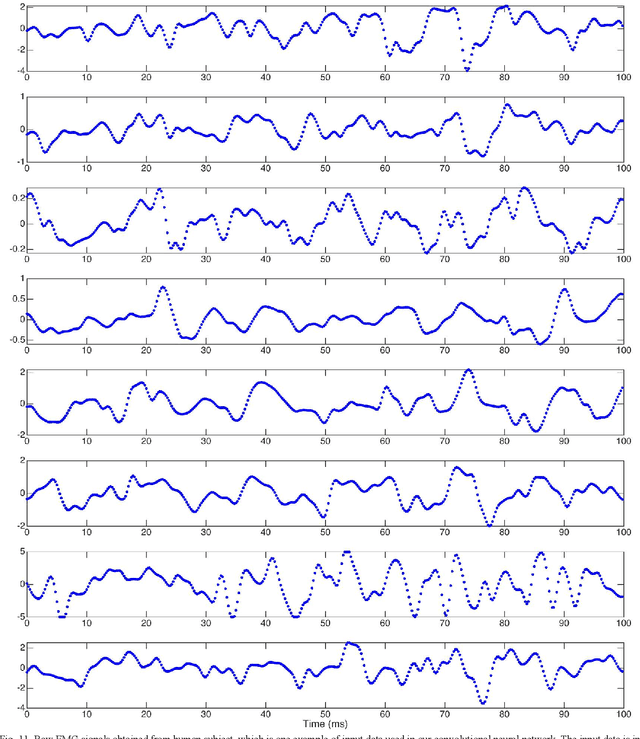
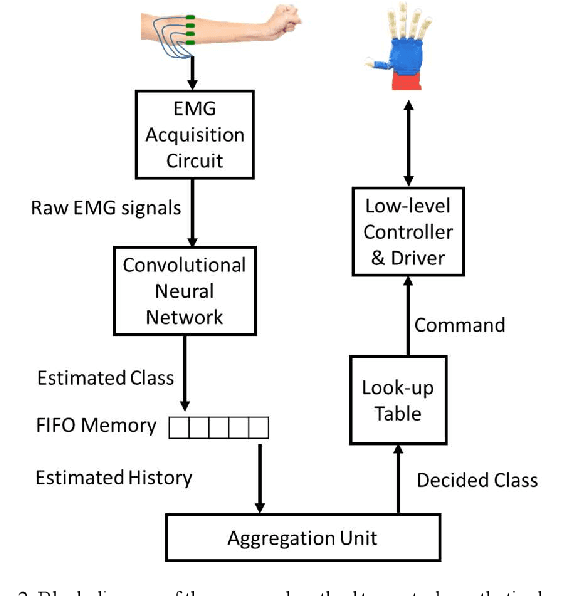
Natural muscles provide mobility in response to nerve impulses. Electromyography (EMG) measures the electrical activity of muscles in response to a nerve's stimulation. In the past few decades, EMG signals have been used extensively in the identification of user intention to potentially control assistive devices such as smart wheelchairs, exoskeletons, and prosthetic devices. In the design of conventional assistive devices, developers optimize multiple subsystems independently. Feature extraction and feature description are essential subsystems of this approach. Therefore, researchers proposed various hand-crafted features to interpret EMG signals. However, the performance of conventional assistive devices is still unsatisfactory. In this paper, we propose a deep learning approach to control prosthetic hands with raw EMG signals. We use a novel deep convolutional neural network to eschew the feature-engineering step. Removing the feature extraction and feature description is an important step toward the paradigm of end-to-end optimization. Fine-tuning and personalization are additional advantages of our approach. The proposed approach is implemented in Python with TensorFlow deep learning library, and it runs in real-time in general-purpose graphics processing units of NVIDIA Jetson TX2 developer kit. Our results demonstrate the ability of our system to predict fingers position from raw EMG signals. We anticipate our EMG-based control system to be a starting point to design more sophisticated prosthetic hands. For example, a pressure measurement unit can be added to transfer the perception of the environment to the user. Furthermore, our system can be modified for other prosthetic devices.
* Conference. Houston, Texas, USA. September, 2019