 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Performance of Pre-Trained Networks by Matched Augmentation Distributions
Jan 19, 2022
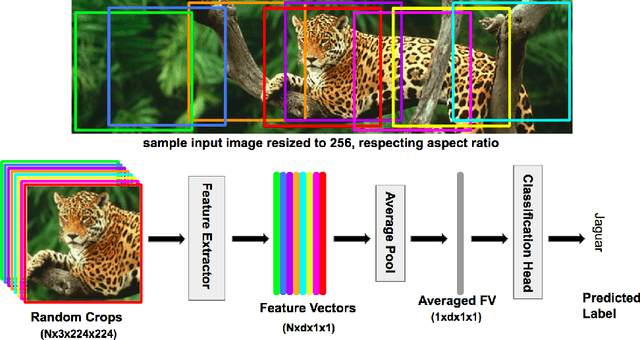
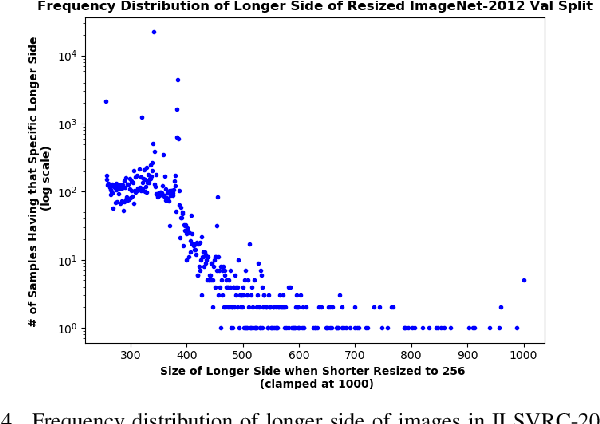
There exists a distribution discrepancy between training and testing, in the way images are fed to modern CNNs. Recent work tried to bridge this gap either by fine-tuning or re-training the network at different resolutions. However re-training a network is rarely cheap and not always viable. To this end, we propose a simple solution to address the train-test distributional shift and enhance the performance of pre-trained models -- which commonly ship as a package with deep learning platforms \eg, PyTorch. Specifically, we demonstrate that running inference on the center crop of an image is not always the best as important discriminatory information may be cropped-off. Instead we propose to combine results for multiple random crops for a test image. This not only matches the train time augmentation but also provides the full coverage of the input image. We explore combining representation of random crops through averaging at different levels \ie, deep feature level, logit level, and softmax level. We demonstrate that, for various families of modern deep networks, such averaging results in better validation accuracy compared to using a single central crop per image. The softmax averaging results in the best performance for various pre-trained networks without requiring any re-training or fine-tuning whatsoever. On modern GPUs with batch processing, the paper's approach to inference of pre-trained networks, is essentially free as all images in a batch can all be processed at once.
Self-Supervised Features Improve Open-World Learning
Feb 15, 2021
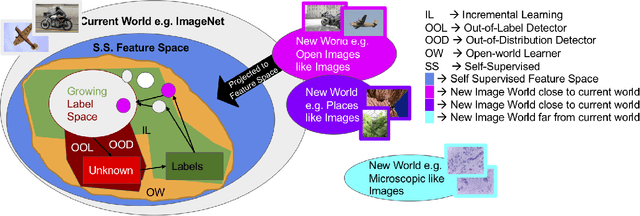
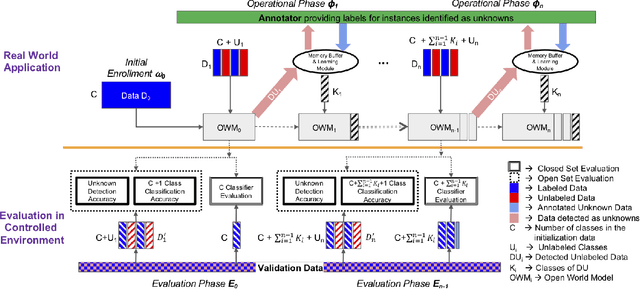
This is a position paper that addresses the problem of Open-World learning while proposing for the underlying feature representation to be learnt using self-supervision. We also present an unifying open-world framework combining three individual research dimensions which have been explored independently \ie Incremental Learning, Out-of-Distribution detection and Open-World learning. We observe that the supervised feature representations are limited and degenerate for the Open-World setting and unsupervised feature representation is native to each of these three problem domains. Under an unsupervised feature representation, we categorize the problem of detecting unknowns as either Out-of-Label-space or Out-of-Distribution detection, depending on the data used during system training versus system testing. The incremental learning component of our pipeline is a zero-exemplar online model which performs comparatively against state-of-the-art on ImageNet-100 protocol and does not require any back-propagation or retraining of the underlying deep-network. It further outperforms the current state-of-the-art by simply using the same number of exemplars as its counterparts. To evaluate our approach for Open-World learning, we propose a new comprehensive protocol and evaluate its performance in both Out-of-Label and Out-of-Distribution settings for each incremental stage. We also demonstrate the adaptability of our approach by showing how it can work as a plug-in with any of the recently proposed self-supervised feature representation methods.
Open-World Learning Without Labels
Dec 14, 2020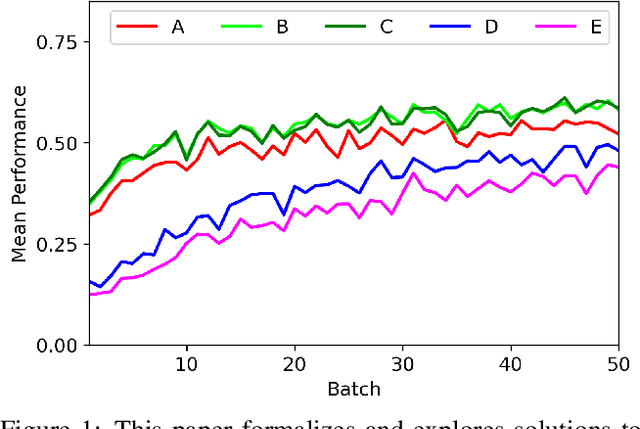

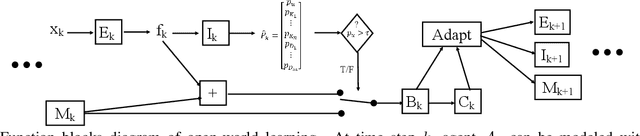
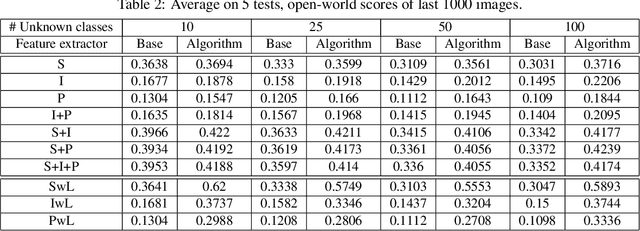
Open-world learning is a problem where an autonomous agent detects things that it does not know and learns them over time from a non-stationary and never-ending stream of data; in an open-world environment, the training data and objective criteria are never available at once. The agent should grasp new knowledge from learning without forgetting acquired prior knowledge. Researchers proposed a few open-world learning agents for image classification tasks that operate in complex scenarios. However, all prior work on open-world learning has all labeled data to learn the new classes from the stream of images. In scenarios where autonomous agents should respond in near real-time or work in areas with limited communication infrastructure, human labeling of data is not possible. Therefore, supervised open-world learning agents are not scalable solutions for such applications. Herein, we propose a new framework that enables agents to learn new classes from a stream of unlabeled data in an unsupervised manner. Also, we study the robustness and learning speed of such agents with supervised and unsupervised feature representation. We also introduce a new metric for open-world learning without labels. We anticipate our theories and method to be a starting point for developing autonomous true open-world never-ending learning agents.
Automatic Open-World Reliability Assessment
Nov 11, 2020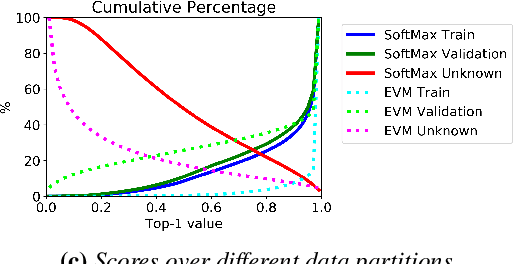
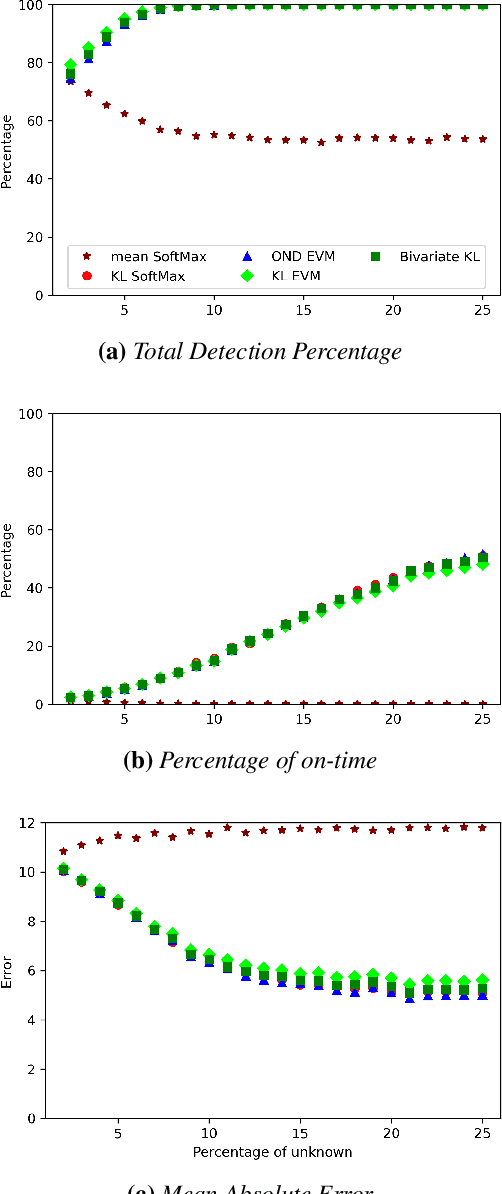
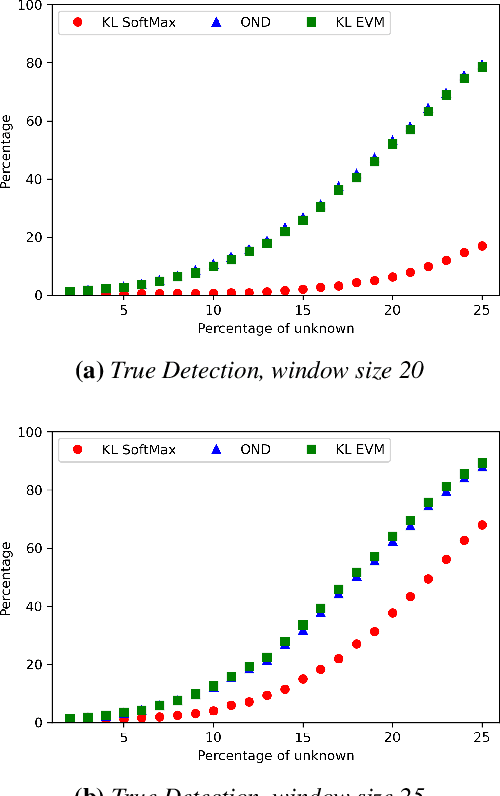
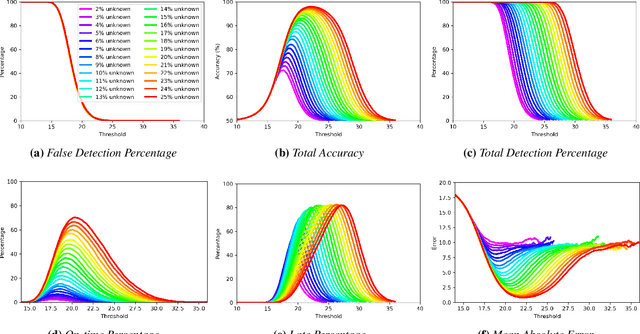
Image classification in the open-world must handle out-of-distribution (OOD) images. Systems should ideally reject OOD images, or they will map atop of known classes and reduce reliability. Using open-set classifiers that can reject OOD inputs can help. However, optimal accuracy of open-set classifiers depend on the frequency of OOD data. Thus, for either standard or open-set classifiers, it is important to be able to determine when the world changes and increasing OOD inputs will result in reduced system reliability. However, during operations, we cannot directly assess accuracy as there are no labels. Thus, the reliability assessment of these classifiers must be done by human operators, made more complex because networks are not 100% accurate, so some failures are to be expected. To automate this process, herein, we formalize the open-world recognition reliability problem and propose multiple automatic reliability assessment policies to address this new problem using only the distribution of reported scores/probability data. The distributional algorithms can be applied to both classic classifiers with SoftMax as well as the open-world Extreme Value Machine (EVM) to provide automated reliability assessment. We show that all of the new algorithms significantly outperform detection using the mean of SoftMax.
* 2021 IEEE Winter Conference on Applications of Computer Vision (WACV)
Reducing Network Agnostophobia
Nov 09, 2018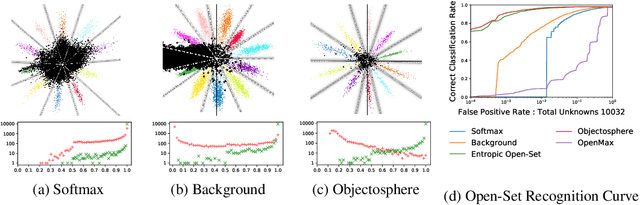


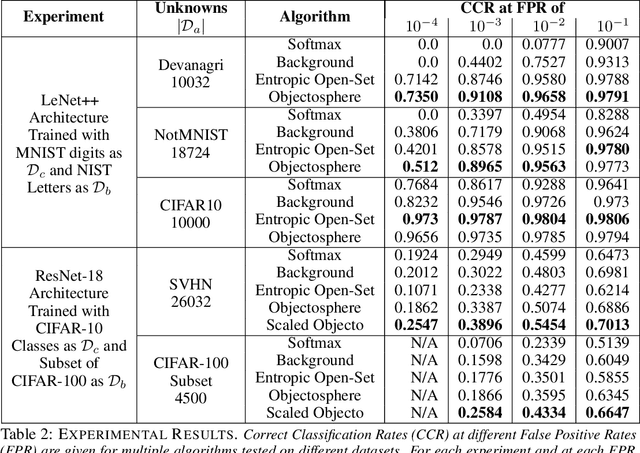
Agnostophobia, the fear of the unknown, can be experienced by deep learning engineers while applying their networks to real-world applications. Unfortunately, network behavior is not well defined for inputs far from a networks training set. In an uncontrolled environment, networks face many instances that are not of interest to them and have to be rejected in order to avoid a false positive. This problem has previously been tackled by researchers by either a) thresholding softmax, which by construction cannot return "none of the known classes", or b) using an additional background or garbage class. In this paper, we show that both of these approaches help, but are generally insufficient when previously unseen classes are encountered. We also introduce a new evaluation metric that focuses on comparing the performance of multiple approaches in scenarios where such unseen classes or unknowns are encountered. Our major contributions are simple yet effective Entropic Open-Set and Objectosphere losses that train networks using negative samples from some classes. These novel losses are designed to maximize entropy for unknown inputs while increasing separation in deep feature space by modifying magnitudes of known and unknown samples. Experiments on networks trained to classify classes from MNIST and CIFAR-10 show that our novel loss functions are significantly better at dealing with unknown inputs from datasets such as Devanagari, NotMNIST, CIFAR-100, and SVHN.
Unconstrained Face Detection and Open-Set Face Recognition Challenge
Sep 25, 2018

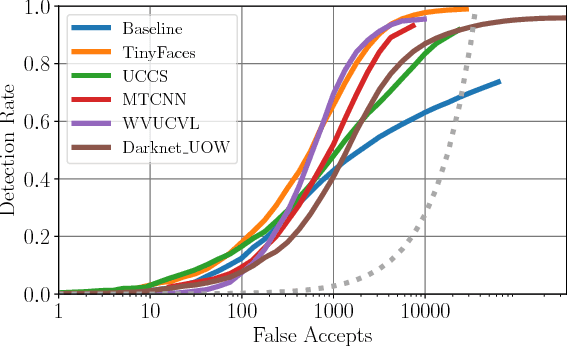

Face detection and recognition benchmarks have shifted toward more difficult environments. The challenge presented in this paper addresses the next step in the direction of automatic detection and identification of people from outdoor surveillance cameras. While face detection has shown remarkable success in images collected from the web, surveillance cameras include more diverse occlusions, poses, weather conditions and image blur. Although face verification or closed-set face identification have surpassed human capabilities on some datasets, open-set identification is much more complex as it needs to reject both unknown identities and false accepts from the face detector. We show that unconstrained face detection can approach high detection rates albeit with moderate false accept rates. By contrast, open-set face recognition is currently weak and requires much more attention.