 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroSim V1.5: Improved Software Backbone for Benchmarking Compute-in-Memory Accelerators with Device and Circuit-level Non-idealities
May 05, 2025



The exponential growth of artificial intelligence (AI) applications has exposed the inefficiency of conventional von Neumann architectures, where frequent data transfers between compute units and memory create significant energy and latency bottlenecks. Analog Computing-in-Memory (ACIM) addresses this challenge by performing multiply-accumulate (MAC) operations directly in the memory arrays, substantially reducing data movement. However, designing robust ACIM accelerators requires accurate modeling of device- and circuit-level non-idealities. In this work, we present NeuroSim V1.5, introducing several key advances: (1) seamless integration with TensorRT's post-training quantization flow enabling support for more neural networks including transformers, (2) a flexible noise injection methodology built on pre-characterized statistical models, making it straightforward to incorporate data from SPICE simulations or silicon measurements, (3) expanded device support including emerging non-volatile capacitive memories, and (4) up to 6.5x faster runtime than NeuroSim V1.4 through optimized behavioral simulation. The combination of these capabilities uniquely enables systematic design space exploration across both accuracy and hardware efficiency metrics. Through multiple case studies, we demonstrate optimization of critical design parameters while maintaining network accuracy. By bridging high-fidelity noise modeling with efficient simulation, NeuroSim V1.5 advances the design and validation of next-generation ACIM accelerators. All NeuroSim versions are available open-source at https://github.com/neurosim/NeuroSim.
Towards Reverse-Engineering the Brain: Brain-Derived Neuromorphic Computing Approach with Photonic, Electronic, and Ionic Dynamicity in 3D integrated circuits
Mar 28, 2024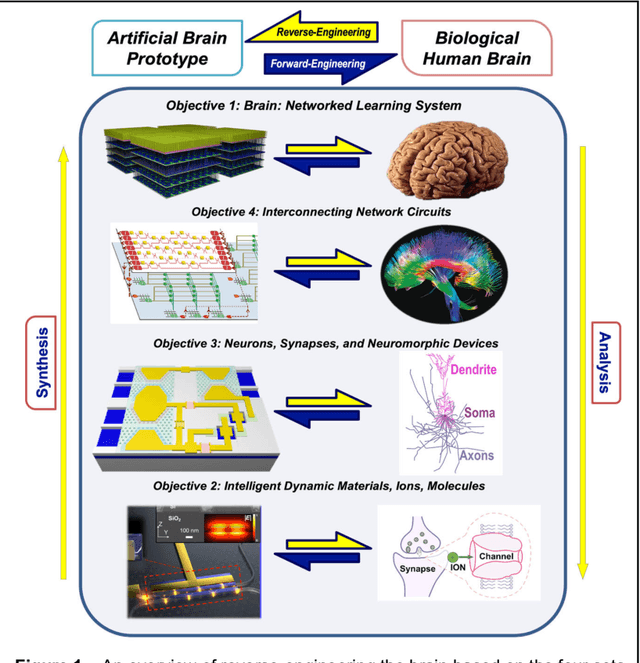

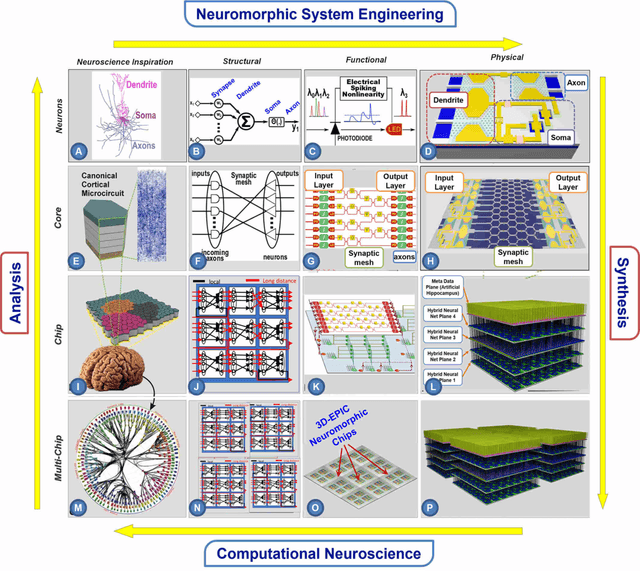
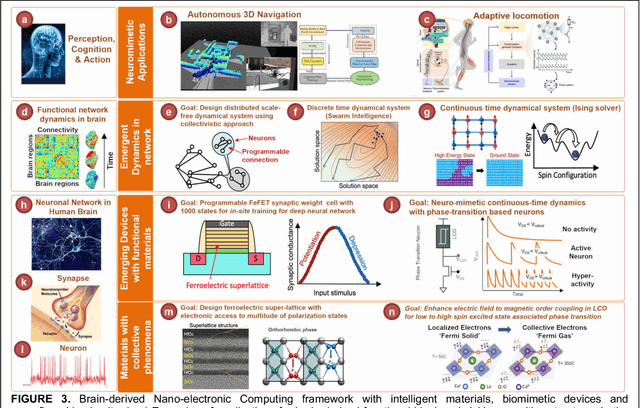
The human brain has immense learning capabilities at extreme energy efficiencies and scale that no artificial system has been able to match. For decades, reverse engineering the brain has been one of the top priorities of science and technology research. Despite numerous efforts, conventional electronics-based methods have failed to match the scalability, energy efficiency, and self-supervised learning capabilities of the human brain. On the other hand, very recent progress in the development of new generations of photonic and electronic memristive materials, device technologies, and 3D electronic-photonic integrated circuits (3D EPIC ) promise to realize new brain-derived neuromorphic systems with comparable connectivity, density, energy-efficiency, and scalability. When combined with bio-realistic learning algorithms and architectures, it may be possible to realize an 'artificial brain' prototype with general self-learning capabilities. This paper argues the possibility of reverse-engineering the brain through architecting a prototype of a brain-derived neuromorphic computing system consisting of artificial electronic, ionic, photonic materials, devices, and circuits with dynamicity resembling the bio-plausible molecular, neuro/synaptic, neuro-circuit, and multi-structural hierarchical macro-circuits of the brain based on well-tested computational models. We further argue the importance of bio-plausible local learning algorithms applicable to the neuromorphic computing system that capture the flexible and adaptive unsupervised and self-supervised learning mechanisms central to human intelligence. Most importantly, we emphasize that the unique capabilities in brain-derived neuromorphic computing prototype systems will enable us to understand links between specific neuronal and network-level properties with system-level functioning and behavior.
A wearable sensor vest for social humanoid robots with GPGPU, IoT, and modular software architecture
Jan 06, 2022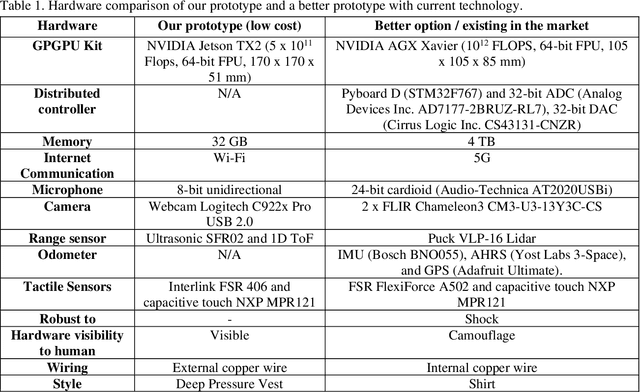
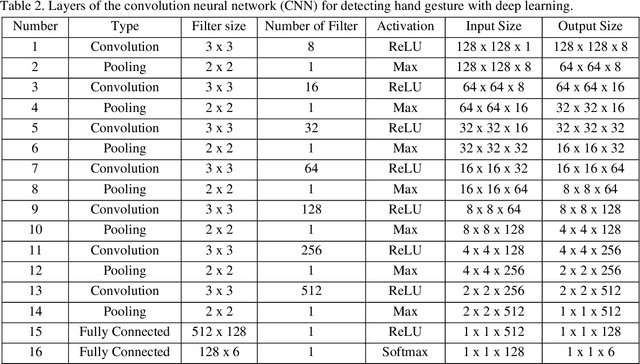
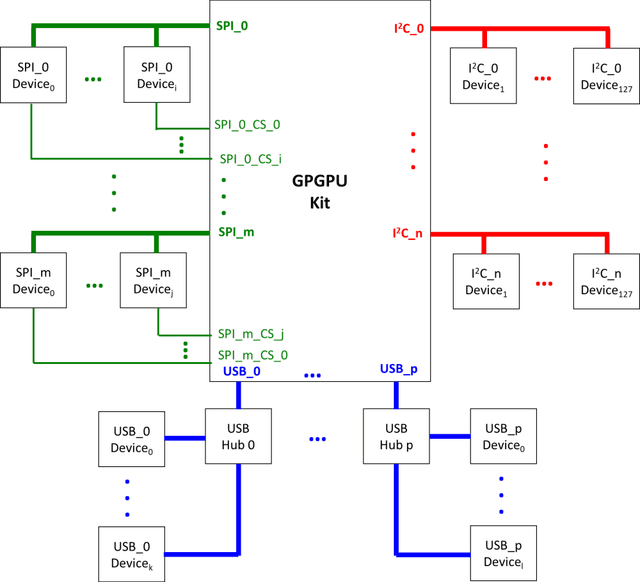
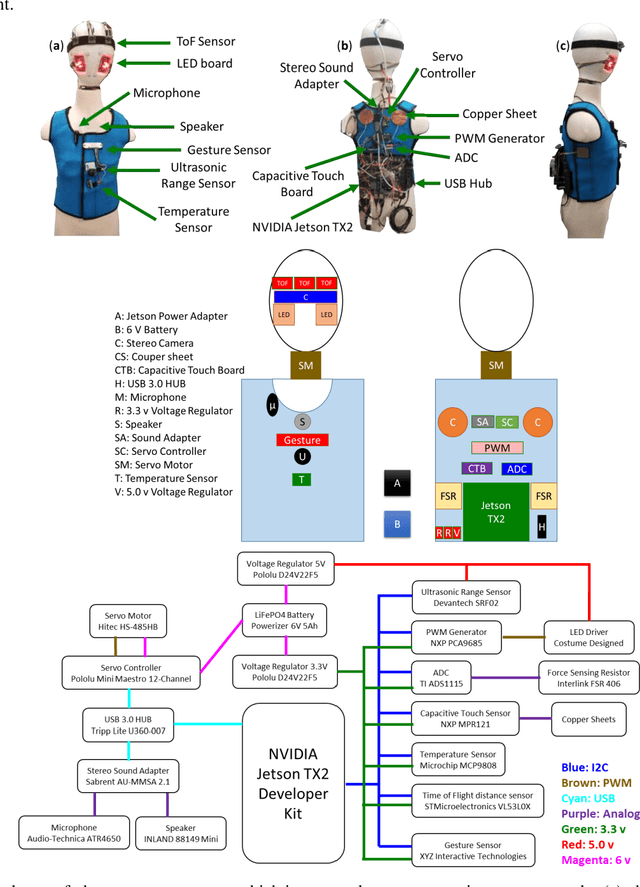
Currently, most social robots interact with their surroundings and humans through sensors that are integral parts of the robots, which limits the usability of the sensors, human-robot interaction, and interchangeability. A wearable sensor garment that fits many robots is needed in many applications. This article presents an affordable wearable sensor vest, and an open-source software architecture with the Internet of Things (IoT) for social humanoid robots. The vest consists of touch, temperature, gesture, distance, vision sensors, and a wireless communication module. The IoT feature allows the robot to interact with humans locally and over the Internet. The designed architecture works for any social robot that has a general-purpose graphics processing unit (GPGPU), I2C/SPI buses, Internet connection, and the Robotics Operating System (ROS). The modular design of this architecture enables developers to easily add/remove/update complex behaviors. The proposed software architecture provides IoT technology, GPGPU nodes, I2C and SPI bus mangers, audio-visual interaction nodes (speech to text, text to speech, and image understanding), and isolation between behavior nodes and other nodes. The proposed IoT solution consists of related nodes in the robot, a RESTful web service, and user interfaces. We used the HTTP protocol as a means of two-way communication with the social robot over the Internet. Developers can easily edit or add nodes in C, C++, and Python programming languages. Our architecture can be used for designing more sophisticated behaviors for social humanoid robots.
* This is the preprint version. The final version is published in Robotics and Autonomous Systems, Volume 139, 2021, Page 103536, ISSN 0921-8890, https://doi.org/10.1016/j.robot.2020.103536
Mitigating Adversarial Attack for Compute-in-Memory Accelerator Utilizing On-chip Finetune
Apr 13, 2021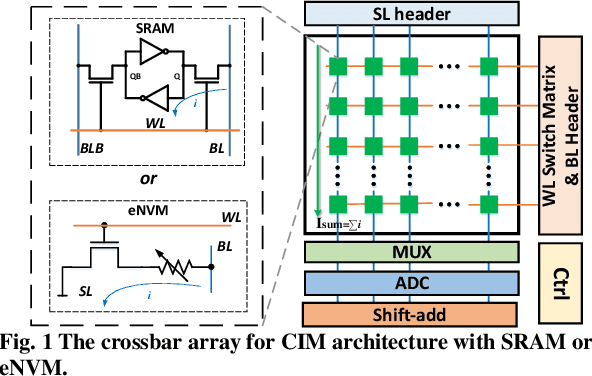
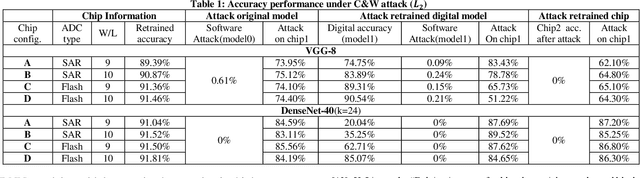
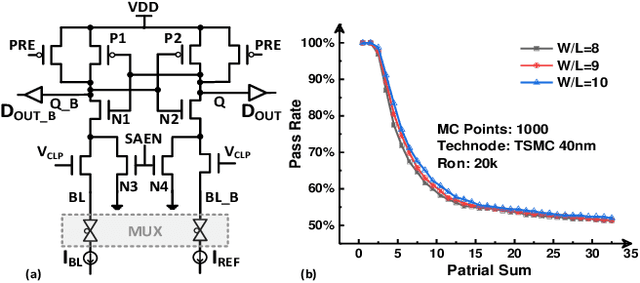

Compute-in-memory (CIM) has been proposed to accelerate the convolution neural network (CNN) computation by implementing parallel multiply and accumulation in analog domain. However, the subsequent processing is still preferred to be performed in digital domain. This makes the analog to digital converter (ADC) critical in CIM architectures. One drawback is the ADC error introduced by process variation. While research efforts are being made to improve ADC design to reduce the offset, we find that the accuracy loss introduced by the ADC error could be recovered by model weight finetune. In addition to compensate ADC offset, on-chip weight finetune could be leveraged to provide additional protection for adversarial attack that aims to fool the inference engine with manipulated input samples. Our evaluation results show that by adapting the model weights to the specific ADC offset pattern to each chip, the transferability of the adversarial attack is suppressed. For a chip being attacked by the C&W method, the classification for CIFAR-10 dataset will drop to almost 0%. However, when applying the similarly generated adversarial examples to other chips, the accuracy could still maintain more than 62% and 85% accuracy for VGG-8 and DenseNet-40, respectively.
DNN+NeuroSim V2.0: An End-to-End Benchmarking Framework for Compute-in-Memory Accelerators for On-chip Training
Mar 13, 2020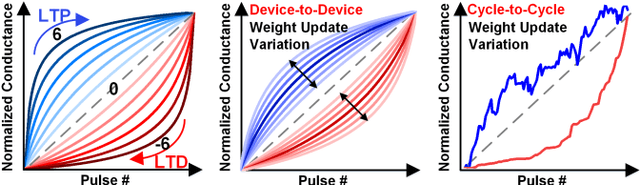
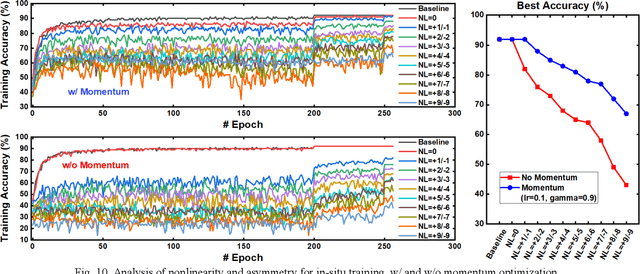
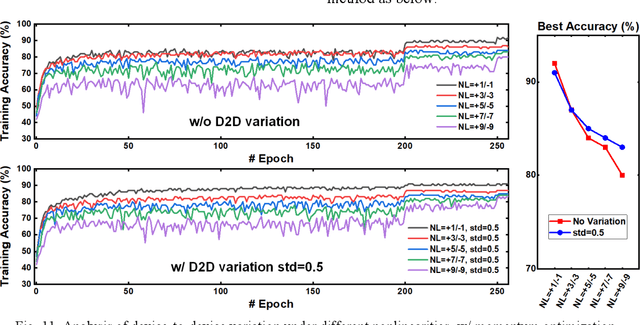
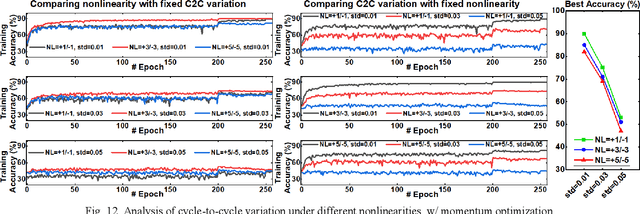
DNN+NeuroSim is an integrated framework to benchmark compute-in-memory (CIM) accelerators for deep neural networks, with hierarchical design options from device-level, to circuit-level and up to algorithm-level. A python wrapper is developed to interface NeuroSim with a popular machine learning platform: Pytorch, to support flexible network structures. The framework provides automatic algorithm-to-hardware mapping, and evaluates chip-level area, energy efficiency and throughput for training or inference, as well as training/inference accuracy with hardware constraints. Our prior work (DNN+NeuroSim V1.1) was developed to estimate the impact of reliability in synaptic devices, and analog-to-digital converter (ADC) quantization loss on the accuracy and hardware performance of inference engines. In this work, we further investigated the impact of the analog emerging non-volatile memory non-ideal device properties for on-chip training. By introducing the nonlinearity, asymmetry, device-to-device and cycle-to-cycle variation of weight update into the python wrapper, and peripheral circuits for error/weight gradient computation in NeuroSim core, we benchmarked CIM accelerators based on state-of-the-art SRAM and eNVM devices for VGG-8 on CIFAR-10 dataset, revealing the crucial specs of synaptic devices for on-chip training. The proposed DNN+NeuroSim V2.0 framework is available on GitHub.
High-Throughput In-Memory Computing for Binary Deep Neural Networks with Monolithically Integrated RRAM and 90nm CMOS
Sep 16, 2019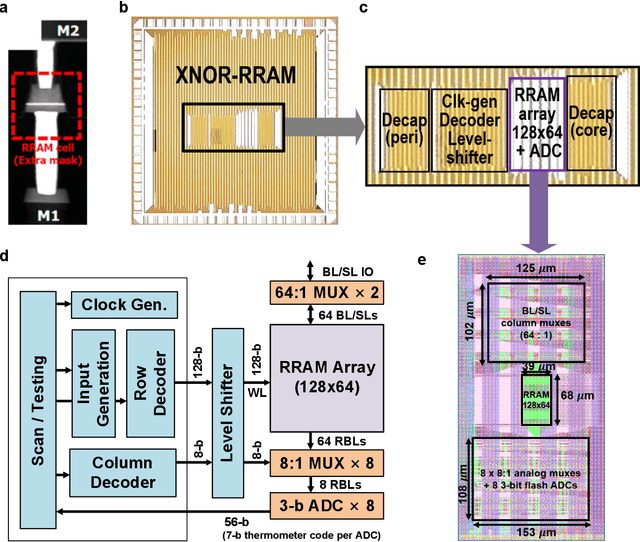
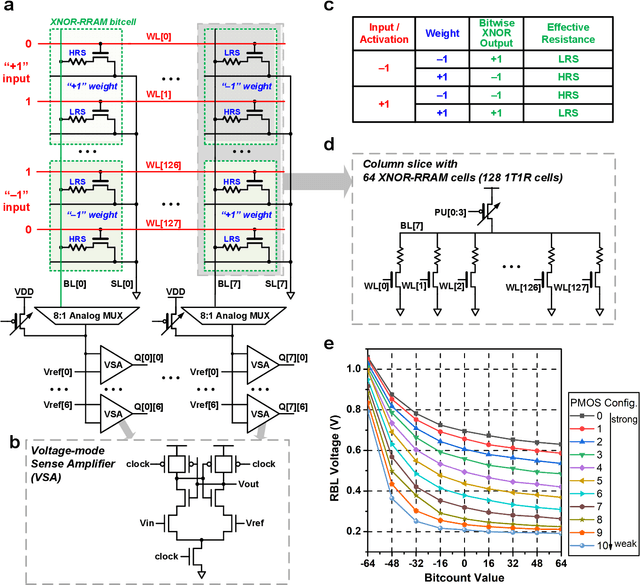
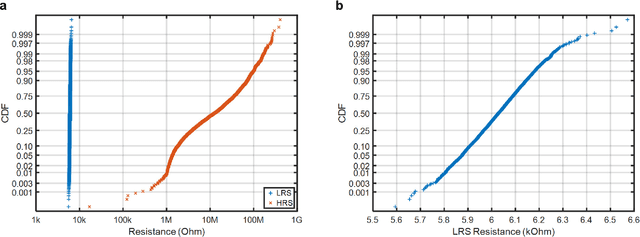
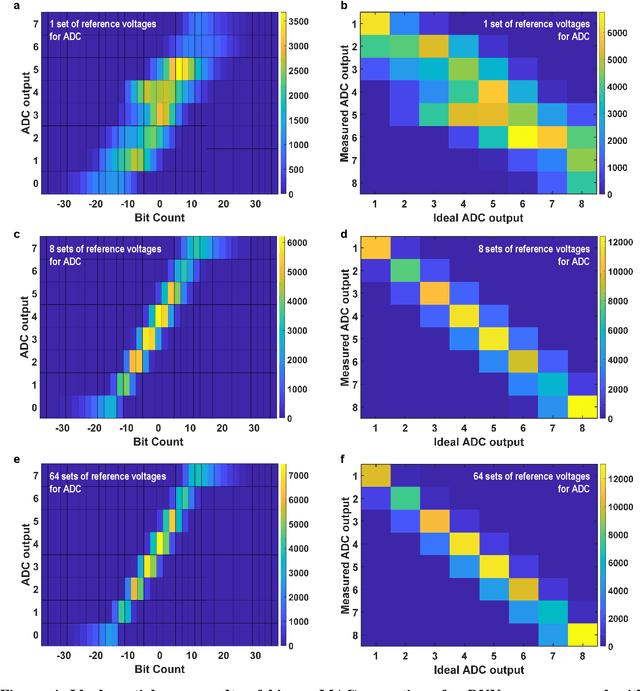
Deep learning hardware designs have been bottlenecked by conventional memories such as SRAM due to density, leakage and parallel computing challenges. Resistive devices can address the density and volatility issues, but have been limited by peripheral circuit integration. In this work, we demonstrate a scalable RRAM based in-memory computing design, termed XNOR-RRAM, which is fabricated in a 90nm CMOS technology with monolithic integration of RRAM devices between metal 1 and 2. We integrated a 128x64 RRAM array with CMOS peripheral circuits including row/column decoders and flash analog-to-digital converters (ADCs), which collectively become a core component for scalable RRAM-based in-memory computing towards large deep neural networks (DNNs). To maximize the parallelism of in-memory computing, we assert all 128 wordlines of the RRAM array simultaneously, perform analog computing along the bitlines, and digitize the bitline voltages using ADCs. The resistance distribution of low resistance states is tightened by write-verify scheme, and the ADC offset is calibrated. Prototype chip measurements show that the proposed design achieves high binary DNN accuracy of 98.5% for MNIST and 83.5% for CIFAR-10 datasets, respectively, with energy efficiency of 24 TOPS/W and 158 GOPS throughput. This represents 5.6X, 3.2X, 14.1X improvements in throughput, energy-delay product (EDP), and energy-delay-squared product (ED2P), respectively, compared to the state-of-the-art literature. The proposed XNOR-RRAM can enable intelligent functionalities for area-/energy-constrained edge computing devices.
Large-Scale Neuromorphic Spiking Array Processors: A quest to mimic the brain
May 23, 2018
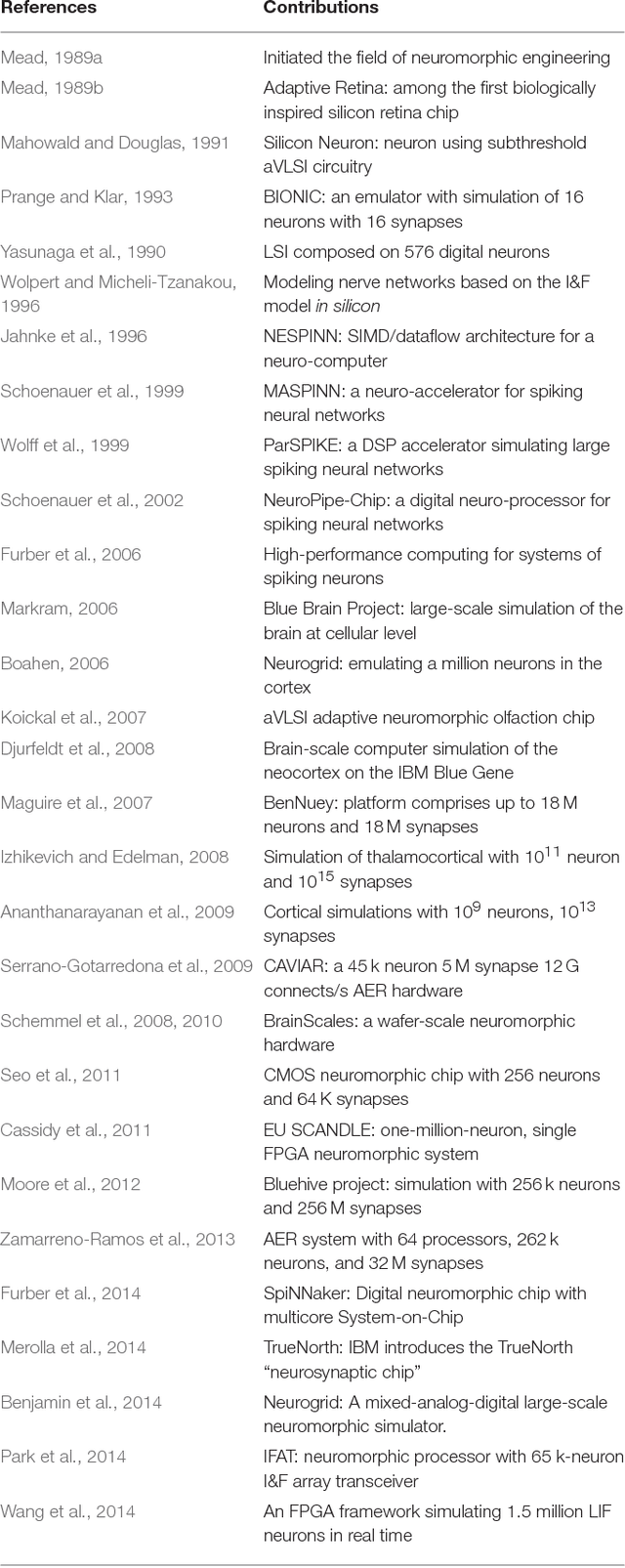
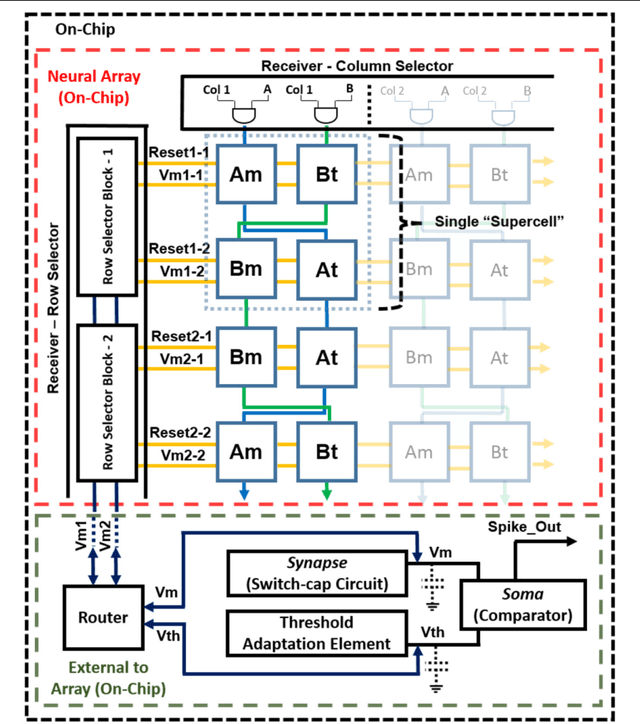
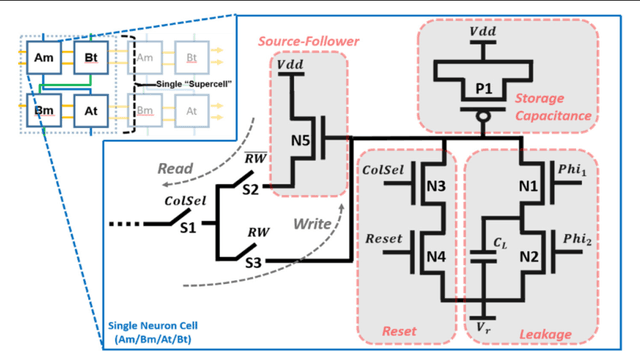
Neuromorphic engineering (NE) encompasses a diverse range of approaches to information processing that are inspired by neurobiological systems, and this feature distinguishes neuromorphic systems from conventional computing systems. The brain has evolved over billions of years to solve difficult engineering problems by using efficient, parallel, low-power computation. The goal of NE is to design systems capable of brain-like computation. Numerous large-scale neuromorphic projects have emerged recently. This interdisciplinary field was listed among the top 10 technology breakthroughs of 2014 by the MIT Technology Review and among the top 10 emerging technologies of 2015 by the World Economic Forum. NE has two-way goals: one, a scientific goal to understand the computational properties of biological neural systems by using models implemented in integrated circuits (ICs); second, an engineering goal to exploit the known properties of biological systems to design and implement efficient devices for engineering applications. Building hardware neural emulators can be extremely useful for simulating large-scale neural models to explain how intelligent behavior arises in the brain. The principle advantages of neuromorphic emulators are that they are highly energy efficient, parallel and distributed, and require a small silicon area. Thus, compared to conventional CPUs, these neuromorphic emulators are beneficial in many engineering applications such as for the porting of deep learning algorithms for various recognitions tasks. In this review article, we describe some of the most significant neuromorphic spiking emulators, compare the different architectures and approaches used by them, illustrate their advantages and drawbacks, and highlight the capabilities that each can deliver to neural modelers.
Device and System Level Design Considerations for Analog-Non-Volatile-Memory Based Neuromorphic Architectures
May 06, 2016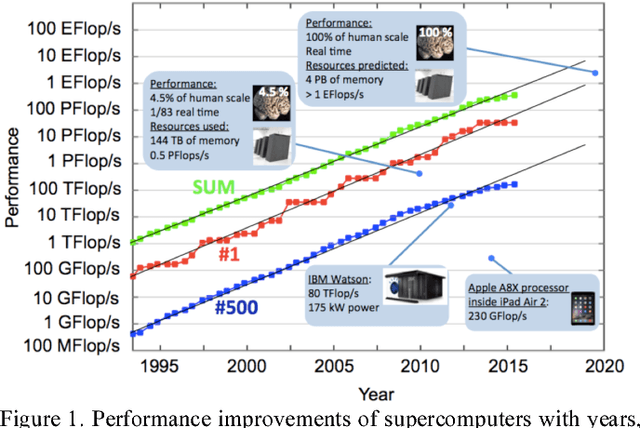

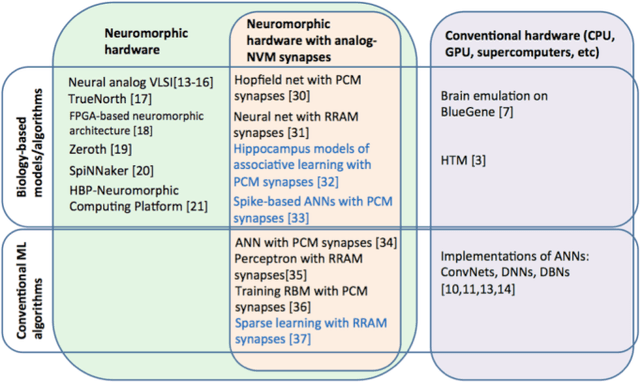
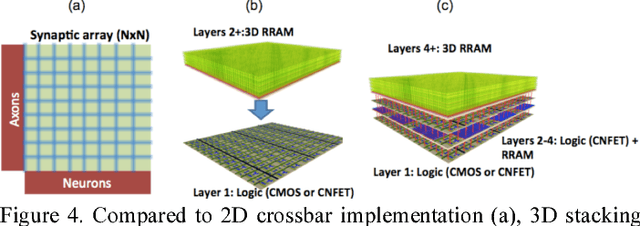
This paper gives an overview of recent progress in the brain inspired computing field with a focus on implementation using emerging memories as electronic synapses. Design considerations and challenges such as requirements and design targets on multilevel states, device variability, programming energy, array-level connectivity, fan-in/fanout, wire energy, and IR drop are presented. Wires are increasingly important in design decisions, especially for large systems, and cycle-to-cycle variations have large impact on learning performance.
* 4 pages, In Electron Devices Meeting (IEDM), 2015 IEEE International (pp. 4.1). IEEE. Original paper can be found here: http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7409622. Abstract can be found here: http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=7409622&refinements%3D4224410500%26filter%3DAND%28p_IS_Number%3A7409598%29