 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Adversarial Attack for Compute-in-Memory Accelerator Utilizing On-chip Finetune
Apr 13, 2021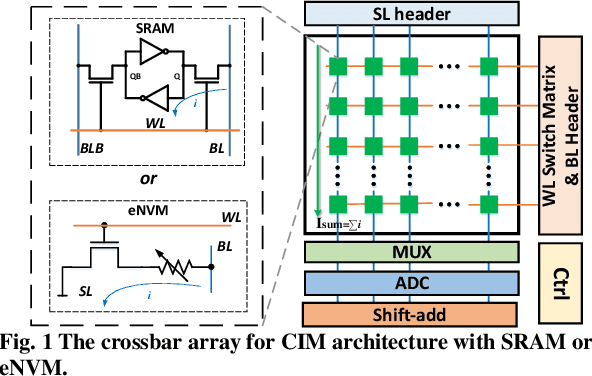
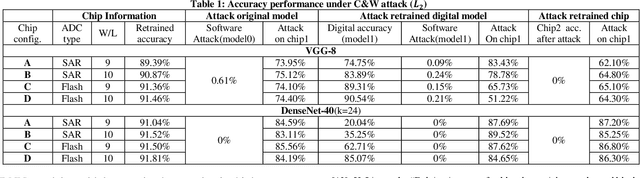
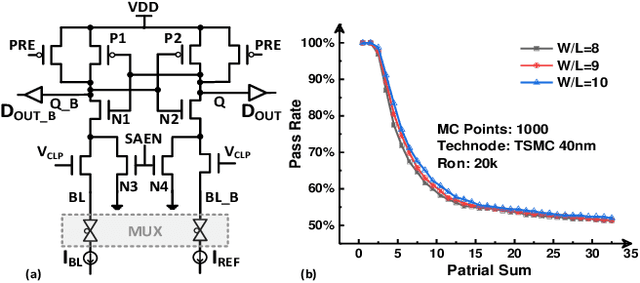

Compute-in-memory (CIM) has been proposed to accelerate the convolution neural network (CNN) computation by implementing parallel multiply and accumulation in analog domain. However, the subsequent processing is still preferred to be performed in digital domain. This makes the analog to digital converter (ADC) critical in CIM architectures. One drawback is the ADC error introduced by process variation. While research efforts are being made to improve ADC design to reduce the offset, we find that the accuracy loss introduced by the ADC error could be recovered by model weight finetune. In addition to compensate ADC offset, on-chip weight finetune could be leveraged to provide additional protection for adversarial attack that aims to fool the inference engine with manipulated input samples. Our evaluation results show that by adapting the model weights to the specific ADC offset pattern to each chip, the transferability of the adversarial attack is suppressed. For a chip being attacked by the C&W method, the classification for CIFAR-10 dataset will drop to almost 0%. However, when applying the similarly generated adversarial examples to other chips, the accuracy could still maintain more than 62% and 85% accuracy for VGG-8 and DenseNet-40, respectively.
DNN+NeuroSim V2.0: An End-to-End Benchmarking Framework for Compute-in-Memory Accelerators for On-chip Training
Mar 13, 2020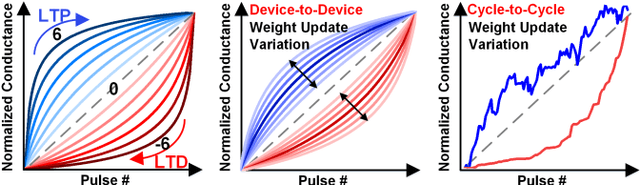
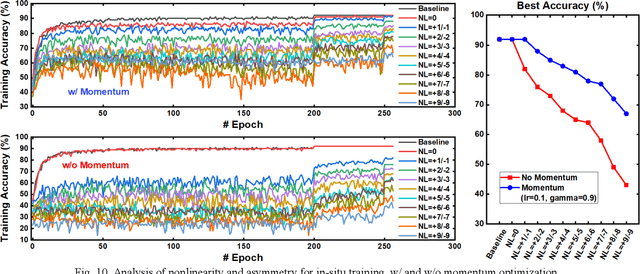
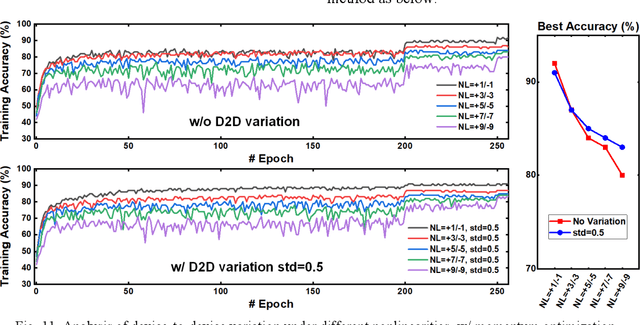
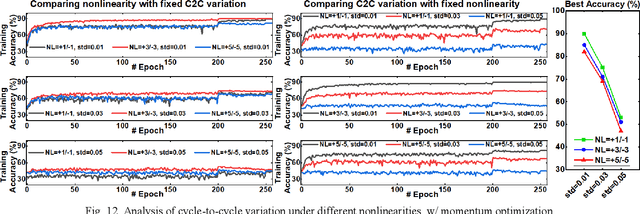
DNN+NeuroSim is an integrated framework to benchmark compute-in-memory (CIM) accelerators for deep neural networks, with hierarchical design options from device-level, to circuit-level and up to algorithm-level. A python wrapper is developed to interface NeuroSim with a popular machine learning platform: Pytorch, to support flexible network structures. The framework provides automatic algorithm-to-hardware mapping, and evaluates chip-level area, energy efficiency and throughput for training or inference, as well as training/inference accuracy with hardware constraints. Our prior work (DNN+NeuroSim V1.1) was developed to estimate the impact of reliability in synaptic devices, and analog-to-digital converter (ADC) quantization loss on the accuracy and hardware performance of inference engines. In this work, we further investigated the impact of the analog emerging non-volatile memory non-ideal device properties for on-chip training. By introducing the nonlinearity, asymmetry, device-to-device and cycle-to-cycle variation of weight update into the python wrapper, and peripheral circuits for error/weight gradient computation in NeuroSim core, we benchmarked CIM accelerators based on state-of-the-art SRAM and eNVM devices for VGG-8 on CIFAR-10 dataset, revealing the crucial specs of synaptic devices for on-chip training. The proposed DNN+NeuroSim V2.0 framework is available on GitHub.