 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge AI without Compromise: Efficient, Versatile and Accurate Neurocomputing in Resistive Random-Access Memory
Aug 17, 2021
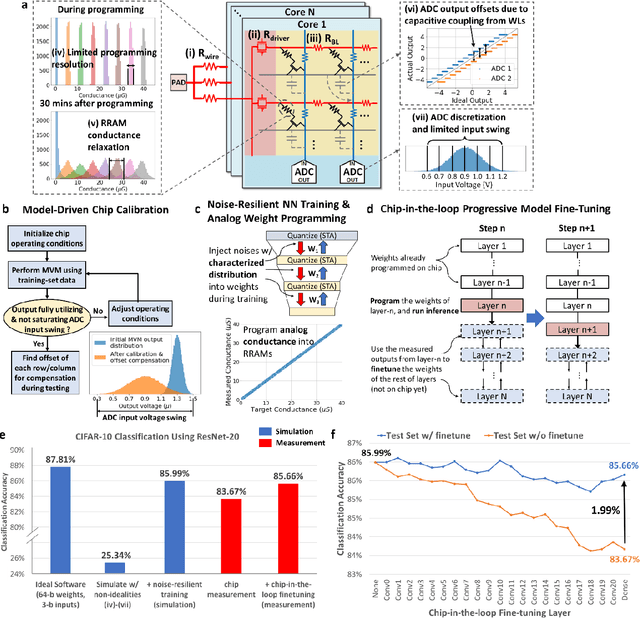
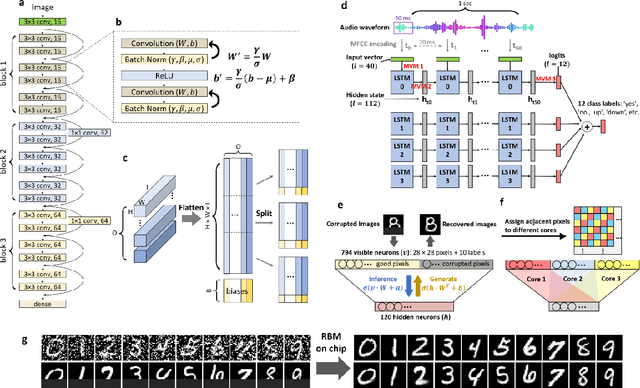
Realizing today's cloud-level artificial intelligence functionalities directly on devices distributed at the edge of the internet calls for edge hardware capable of processing multiple modalities of sensory data (e.g. video, audio) at unprecedented energy-efficiency. AI hardware architectures today cannot meet the demand due to a fundamental "memory wall": data movement between separate compute and memory units consumes large energy and incurs long latency. Resistive random-access memory (RRAM) based compute-in-memory (CIM) architectures promise to bring orders of magnitude energy-efficiency improvement by performing computation directly within memory. However, conventional approaches to CIM hardware design limit its functional flexibility necessary for processing diverse AI workloads, and must overcome hardware imperfections that degrade inference accuracy. Such trade-offs between efficiency, versatility and accuracy cannot be addressed by isolated improvements on any single level of the design. By co-optimizing across all hierarchies of the design from algorithms and architecture to circuits and devices, we present NeuRRAM - the first multimodal edge AI chip using RRAM CIM to simultaneously deliver a high degree of versatility for diverse model architectures, record energy-efficiency $5\times$ - $8\times$ better than prior art across various computational bit-precisions, and inference accuracy comparable to software models with 4-bit weights on all measured standard AI benchmarks including accuracy of 99.0% on MNIST and 85.7% on CIFAR-10 image classification, 84.7% accuracy on Google speech command recognition, and a 70% reduction in image reconstruction error on a Bayesian image recovery task. This work paves a way towards building highly efficient and reconfigurable edge AI hardware platforms for the more demanding and heterogeneous AI applications of the future.
Neural Network Compression for Noisy Storage Devices
Feb 15, 2021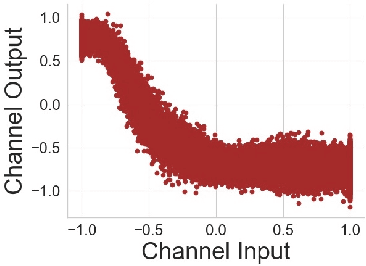
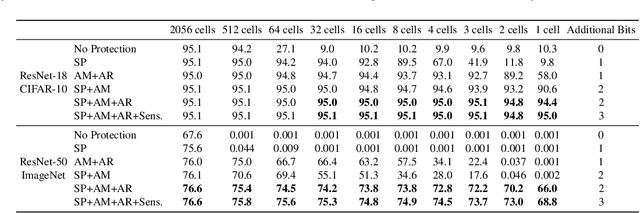
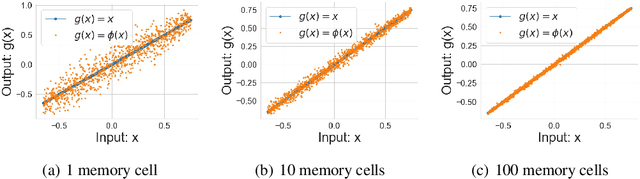
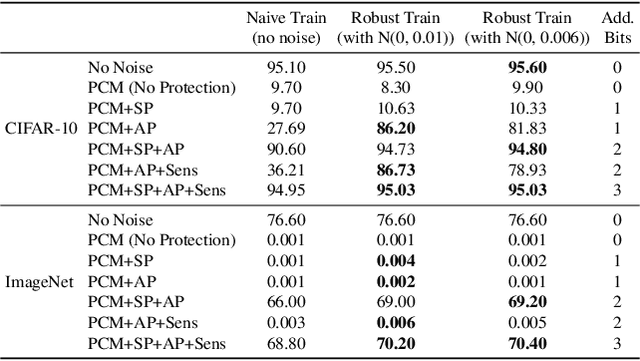
Compression and efficient storage of neural network (NN) parameters is critical for applications that run on resource-constrained devices. Although NN model compression has made significant progress, there has been considerably less investigation in the actual physical storage of NN parameters. Conventionally, model compression and physical storage are decoupled, as digital storage media with error correcting codes (ECCs) provide robust error-free storage. This decoupled approach is inefficient, as it forces the storage to treat each bit of the compressed model equally, and to dedicate the same amount of resources to each bit. We propose a radically different approach that: (i) employs analog memories to maximize the capacity of each memory cell, and (ii) jointly optimizes model compression and physical storage to maximize memory utility. We investigate the challenges of analog storage by studying model storage on phase change memory (PCM) arrays and develop a variety of robust coding strategies for NN model storage. We demonstrate the efficacy of our approach on MNIST, CIFAR-10 and ImageNet datasets for both existing and novel compression methods. Compared to conventional error-free digital storage, our method has the potential to reduce the memory size by one order of magnitude, without significantly compromising the stored model's accuracy.
Hyperdimensional Computing Nanosystem
Nov 23, 2018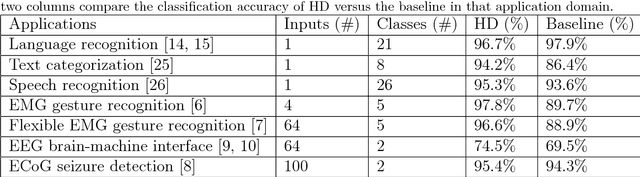
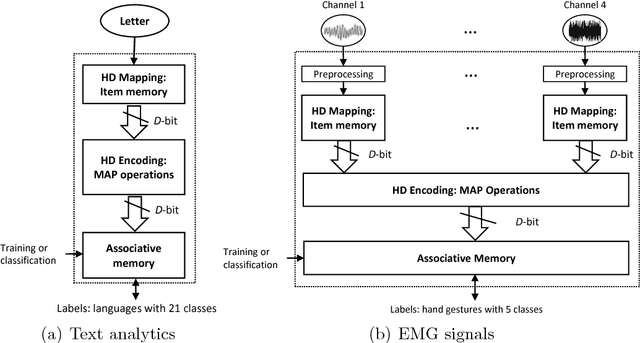
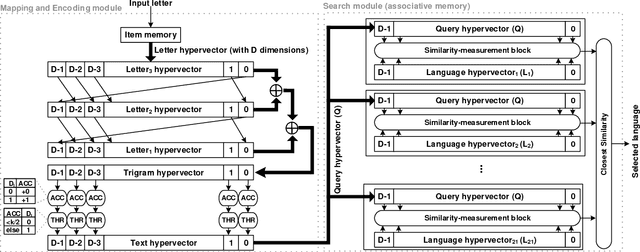
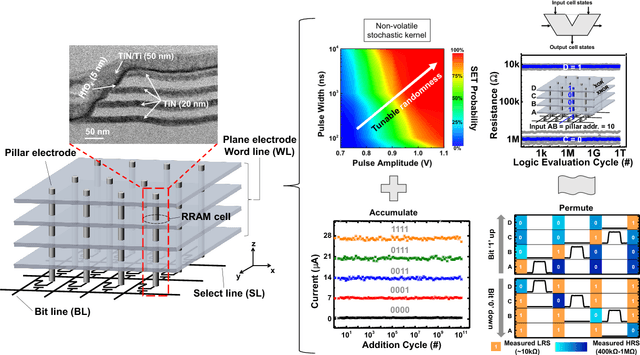
One viable solution for continuous reduction in energy-per-operation is to rethink functionality to cope with uncertainty by adopting computational approaches that are inherently robust to uncertainty. It requires a novel look at data representations, associated operations, and circuits, and at materials and substrates that enable them. 3D integrated nanotechnologies combined with novel brain-inspired computational paradigms that support fast learning and fault tolerance could lead the way. Recognizing the very size of the brain's circuits, hyperdimensional (HD) computing can model neural activity patterns with points in a HD space, that is, with hypervectors as large randomly generated patterns. At its very core, HD computing is about manipulating and comparing these patterns inside memory. Emerging nanotechnologies such as carbon nanotube field effect transistors (CNFETs) and resistive RAM (RRAM), and their monolithic 3D integration offer opportunities for hardware implementations of HD computing through tight integration of logic and memory, energy-efficient computation, and unique device characteristics. We experimentally demonstrate and characterize an end-to-end HD computing nanosystem built using monolithic 3D integration of CNFETs and RRAM. With our nanosystem, we experimentally demonstrate classification of 21 languages with measured accuracy of up to 98% on >20,000 sentences (6.4 million characters), training using one text sample (~100,000 characters) per language, and resilient operation (98% accuracy) despite 78% hardware errors in HD representation (outputs stuck at 0 or 1). By exploiting the unique properties of the underlying nanotechnologies, we show that HD computing, when implemented with monolithic 3D integration, can be up to 420X more energy-efficient while using 25X less area compared to traditional silicon CMOS implementations.
Training a Probabilistic Graphical Model with Resistive Switching Electronic Synapses
Oct 10, 2016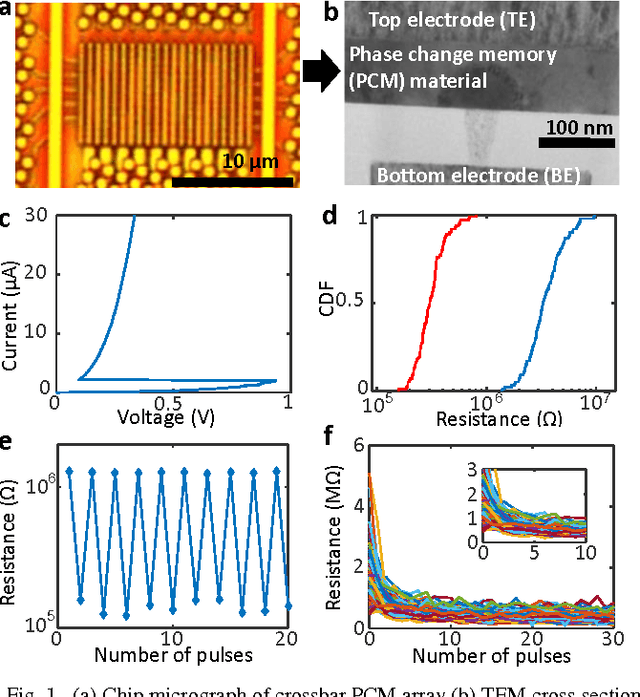
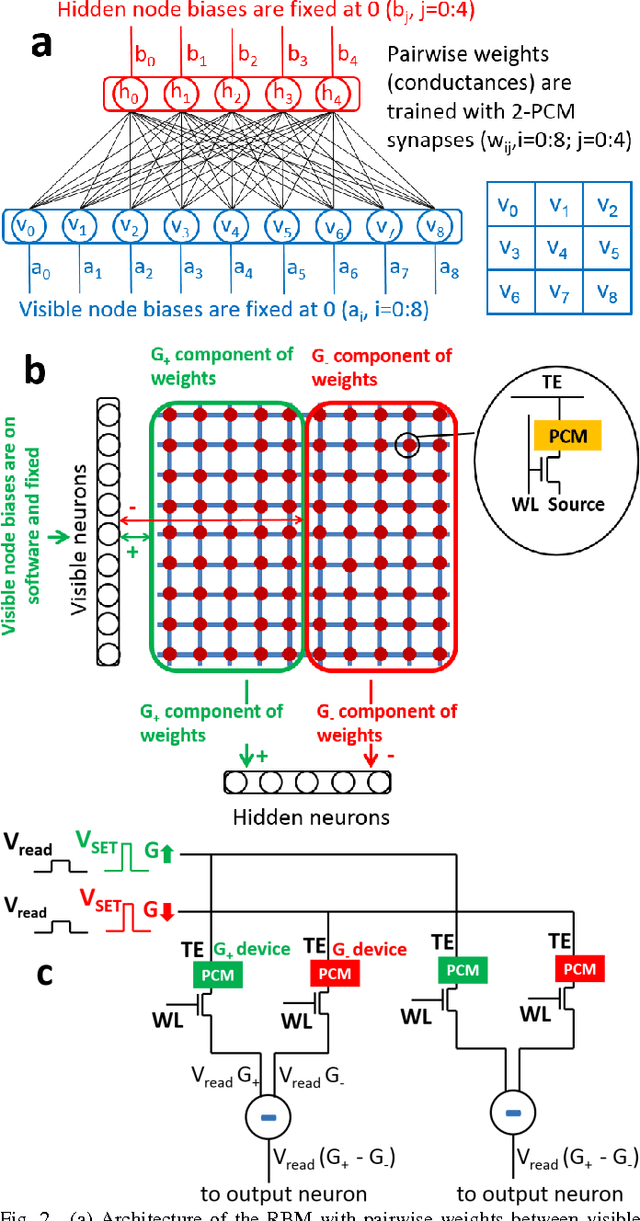
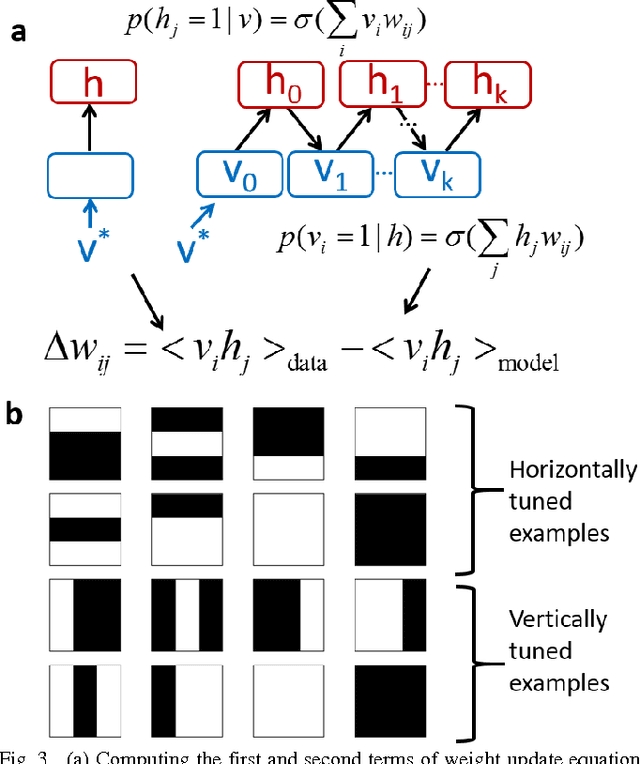
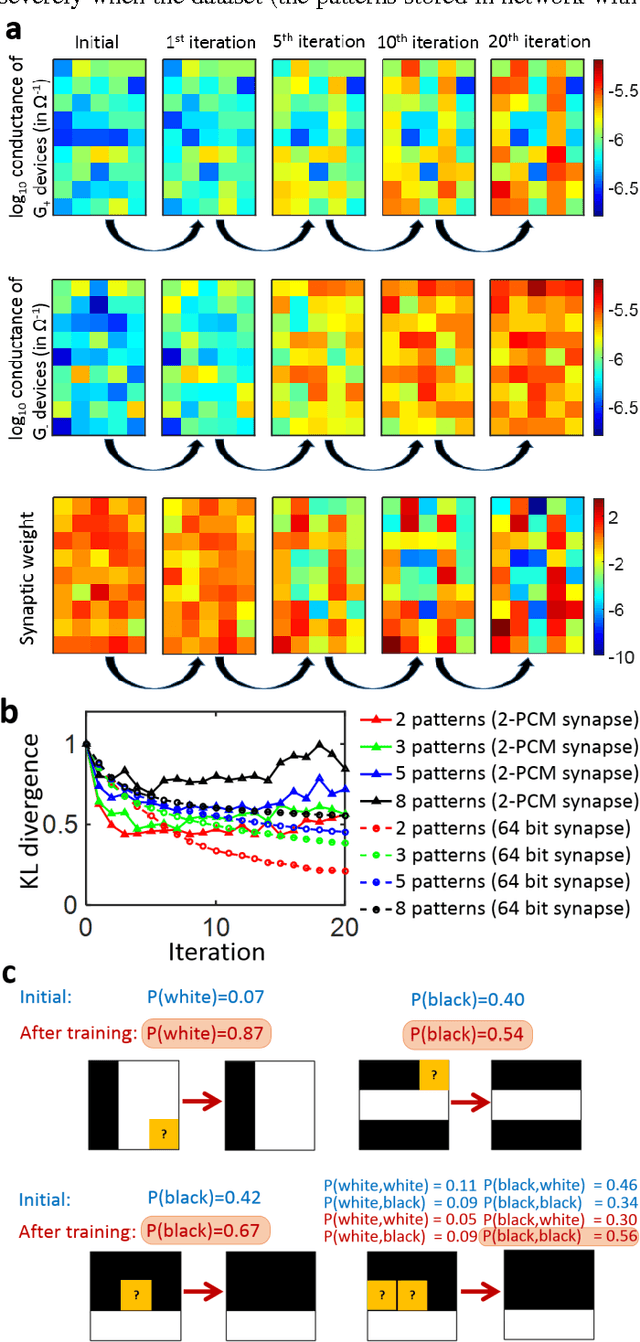
Current large scale implementations of deep learning and data mining require thousands of processors, massive amounts of off-chip memory, and consume gigajoules of energy. Emerging memory technologies such as nanoscale two-terminal resistive switching memory devices offer a compact, scalable and low power alternative that permits on-chip co-located processing and memory in fine-grain distributed parallel architecture. Here we report first use of resistive switching memory devices for implementing and training a Restricted Boltzmann Machine (RBM), a generative probabilistic graphical model as a key component for unsupervised learning in deep networks. We experimentally demonstrate a 45-synapse RBM realized with 90 resistive switching phase change memory (PCM) elements trained with a bio-inspired variant of the Contrastive Divergence (CD) algorithm, implementing Hebbian and anti-Hebbian weight updates. The resistive PCM devices show a two-fold to ten-fold reduction in error rate in a missing pixel pattern completion task trained over 30 epochs, compared to untrained case. Measured programming energy consumption is 6.1 nJ per epoch with the resistive switching PCM devices, a factor of ~150 times lower than conventional processor-memory systems. We analyze and discuss the dependence of learning performance on cycle-to-cycle variations as well as number of gradual levels in the PCM analog memory devices.
Device and System Level Design Considerations for Analog-Non-Volatile-Memory Based Neuromorphic Architectures
May 06, 2016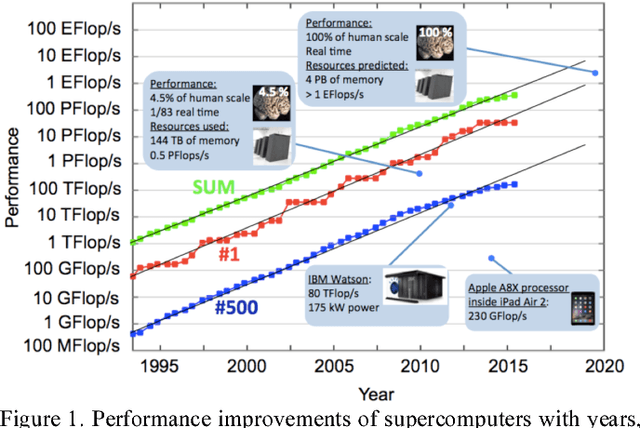

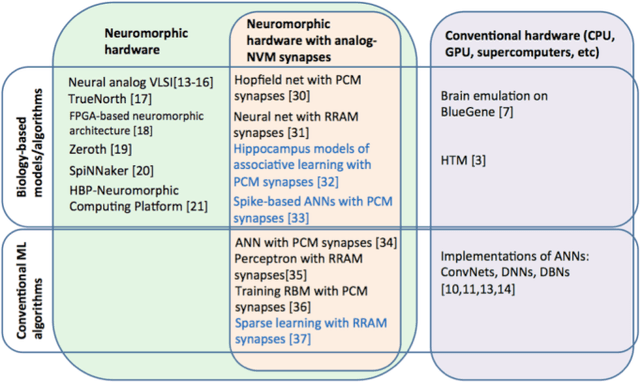
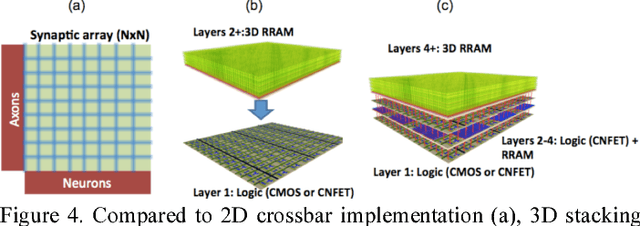
This paper gives an overview of recent progress in the brain inspired computing field with a focus on implementation using emerging memories as electronic synapses. Design considerations and challenges such as requirements and design targets on multilevel states, device variability, programming energy, array-level connectivity, fan-in/fanout, wire energy, and IR drop are presented. Wires are increasingly important in design decisions, especially for large systems, and cycle-to-cycle variations have large impact on learning performance.
* 4 pages, In Electron Devices Meeting (IEDM), 2015 IEEE International (pp. 4.1). IEEE. Original paper can be found here: http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7409622. Abstract can be found here: http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=7409622&refinements%3D4224410500%26filter%3DAND%28p_IS_Number%3A7409598%29
Brain-like associative learning using a nanoscale non-volatile phase change synaptic device array
Jul 14, 2014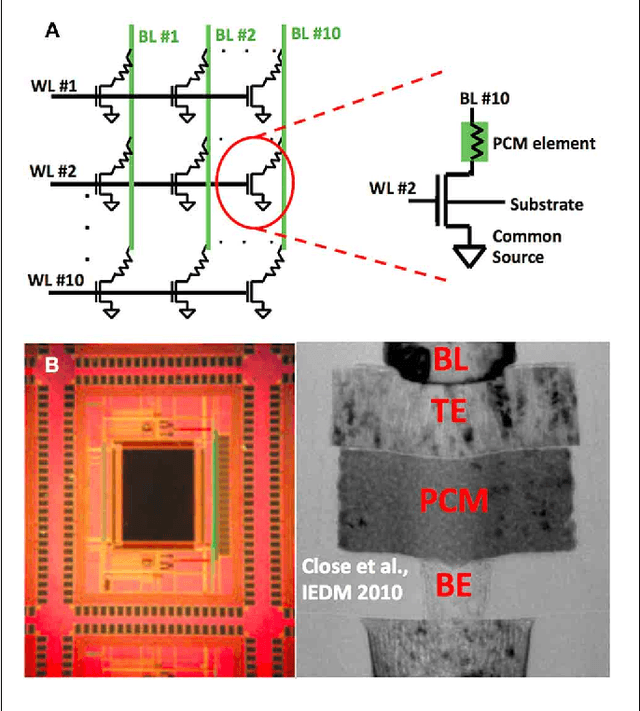



Recent advances in neuroscience together with nanoscale electronic device technology have resulted in huge interests in realizing brain-like computing hardwares using emerging nanoscale memory devices as synaptic elements. Although there has been experimental work that demonstrated the operation of nanoscale synaptic element at the single device level, network level studies have been limited to simulations. In this work, we demonstrate, using experiments, array level associative learning using phase change synaptic devices connected in a grid like configuration similar to the organization of the biological brain. Implementing Hebbian learning with phase change memory cells, the synaptic grid was able to store presented patterns and recall missing patterns in an associative brain-like fashion. We found that the system is robust to device variations, and large variations in cell resistance states can be accommodated by increasing the number of training epochs. We illustrated the tradeoff between variation tolerance of the network and the overall energy consumption, and found that energy consumption is decreased significantly for lower variation tolerance.
* Original article can be found here: http://journal.frontiersin.org/Journal/10.3389/fnins.2014.00205/abstract
Experimental Demonstration of Array-level Learning with Phase Change Synaptic Devices
Jun 03, 2014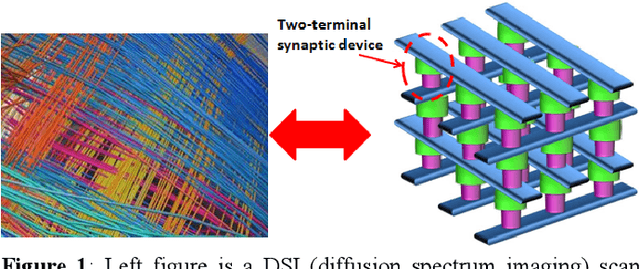
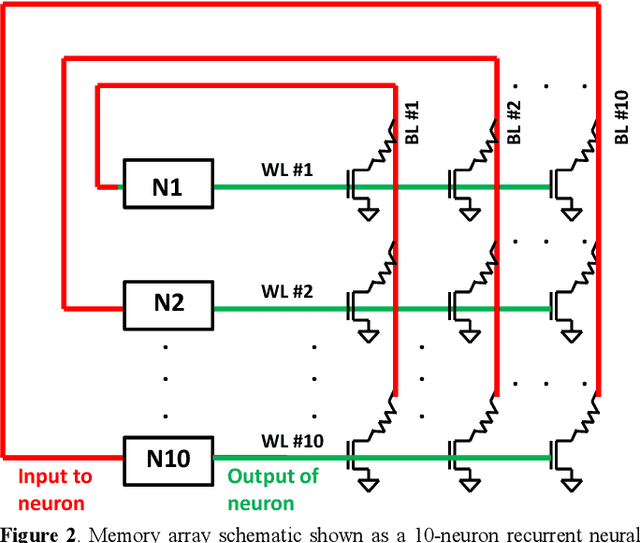

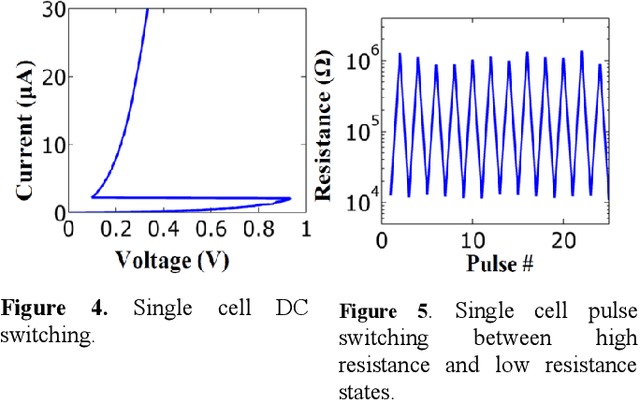
The computational performance of the biological brain has long attracted significant interest and has led to inspirations in operating principles, algorithms, and architectures for computing and signal processing. In this work, we focus on hardware implementation of brain-like learning in a brain-inspired architecture. We demonstrate, in hardware, that 2-D crossbar arrays of phase change synaptic devices can achieve associative learning and perform pattern recognition. Device and array-level studies using an experimental 10x10 array of phase change synaptic devices have shown that pattern recognition is robust against synaptic resistance variations and large variations can be tolerated by increasing the number of training iterations. Our measurements show that increase in initial variation from 9 % to 60 % causes required training iterations to increase from 1 to 11.
* IEDM 2013