 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Open-Set Face Recognition
Paper and Code
May 19, 2017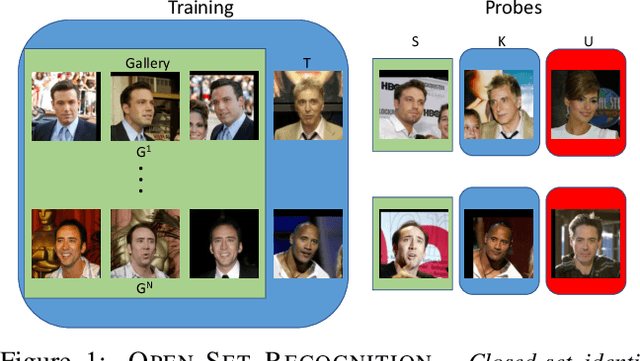
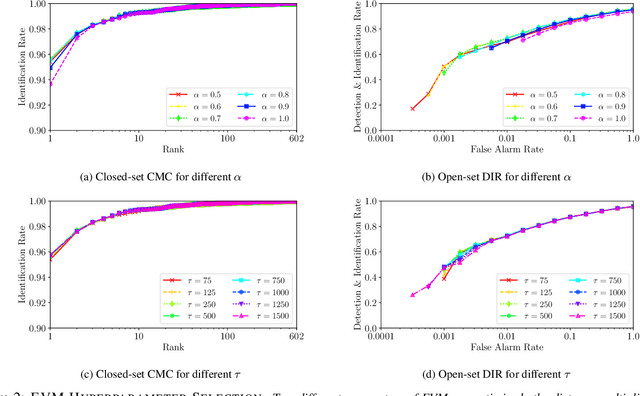
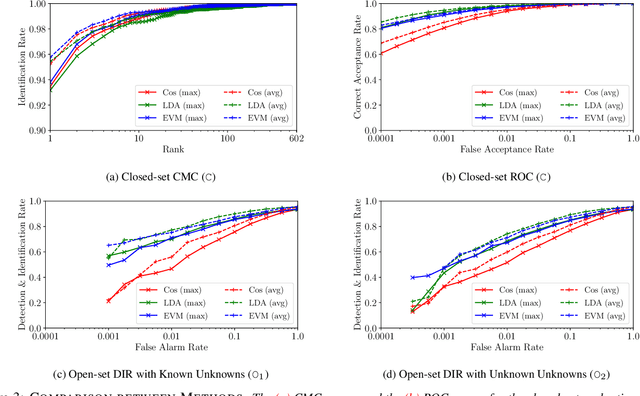
Much research has been conducted on both face identification and face verification, with greater focus on the latter. Research on face identification has mostly focused on using closed-set protocols, which assume that all probe images used in evaluation contain identities of subjects that are enrolled in the gallery. Real systems, however, where only a fraction of probe sample identities are enrolled in the gallery, cannot make this closed-set assumption. Instead, they must assume an open set of probe samples and be able to reject/ignore those that correspond to unknown identities. In this paper, we address the widespread misconception that thresholding verification-like scores is a good way to solve the open-set face identification problem, by formulating an open-set face identification protocol and evaluating different strategies for assessing similarity. Our open-set identification protocol is based on the canonical labeled faces in the wild (LFW) dataset. Additionally to the known identities, we introduce the concepts of known unknowns (known, but uninteresting persons) and unknown unknowns (people never seen before) to the biometric community. We compare three algorithms for assessing similarity in a deep feature space under an open-set protocol: thresholded verification-like scores, linear discriminant analysis (LDA) scores, and an extreme value machine (EVM) probabilities. Our findings suggest that thresholding EVM probabilities, which are open-set by design, outperforms thresholding verification-like scores.