 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Beta or Not To Beta: Information Bottleneck for DigitaL Image Forensics
Aug 11, 2019
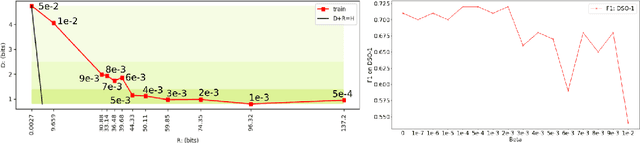

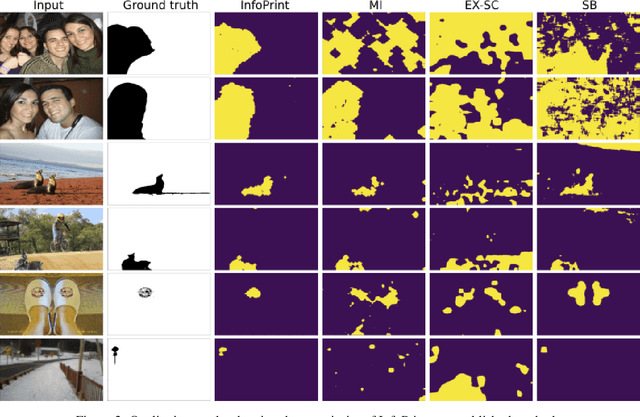
We consider an information theoretic approach to address the problem of identifying fake digital images. We propose an innovative method to formulate the issue of localizing manipulated regions in an image as a deep representation learning problem using the Information Bottleneck (IB), which has recently gained popularity as a framework for interpreting deep neural networks. Tampered images pose a serious predicament since digitized media is a ubiquitous part of our lives. These are facilitated by the easy availability of image editing software and aggravated by recent advances in deep generative models such as GANs. We propose InfoPrint, a computationally efficient solution to the IB formulation using approximate variational inference and compare it to a numerical solution that is computationally expensive. Testing on a number of standard datasets, we demonstrate that InfoPrint outperforms the state-of-the-art and the numerical solution. Additionally, it also has the ability to detect alterations made by inpainting GANs.
SpliceRadar: A Learned Method For Blind Image Forensics
Jun 27, 2019

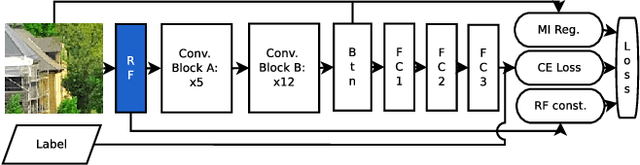
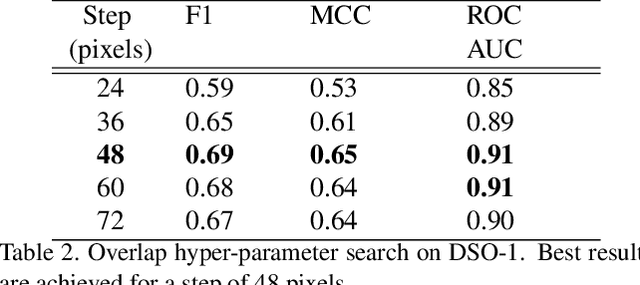
Detection and localization of image manipulations like splices are gaining in importance with the easy accessibility of image editing softwares. While detection generates a verdict for an image it provides no insight into the manipulation. Localization helps explain a positive detection by identifying the pixels of the image which have been tampered. We propose a deep learning based method for splice localization without prior knowledge of a test image's camera-model. It comprises a novel approach for learning rich filters and for suppressing image-edges. Additionally, we train our model on a surrogate task of camera model identification, which allows us to leverage large and widely available, unmanipulated, camera-tagged image databases. During inference, we assume that the spliced and host regions come from different camera-models and we segment these regions using a Gaussian-mixture model. Experiments on three test databases demonstrate results on par with and above the state-of-the-art and a good generalization ability to unknown datasets.