 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Implicit Surface Point Prediction Networks
Jun 15, 2021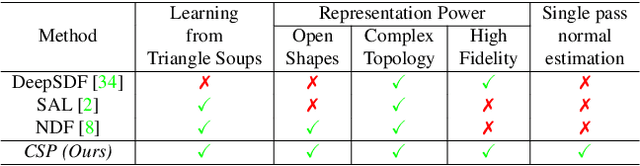
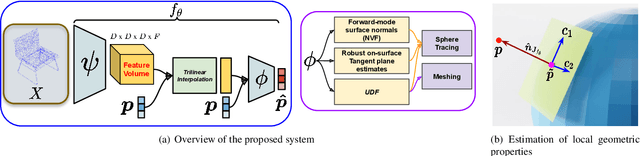
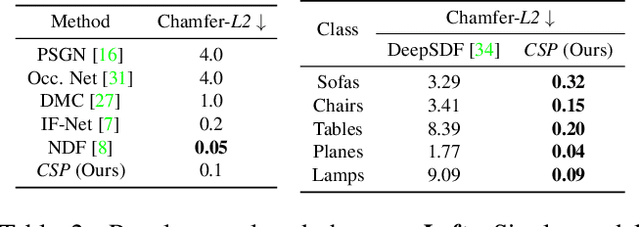
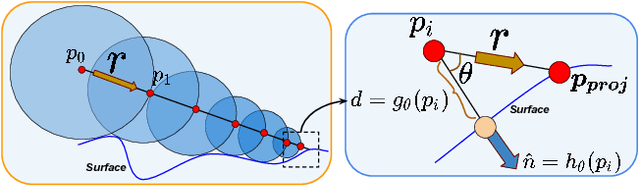
Deep neural representations of 3D shapes as implicit functions have been shown to produce high fidelity models surpassing the resolution-memory trade-off faced by the explicit representations using meshes and point clouds. However, most such approaches focus on representing closed shapes. Unsigned distance function (UDF) based approaches have been proposed recently as a promising alternative to represent both open and closed shapes. However, since the gradients of UDFs vanish on the surface, it is challenging to estimate local (differential) geometric properties like the normals and tangent planes which are needed for many downstream applications in vision and graphics. There are additional challenges in computing these properties efficiently with a low-memory footprint. This paper presents a novel approach that models such surfaces using a new class of implicit representations called the closest surface-point (CSP) representation. We show that CSP allows us to represent complex surfaces of any topology (open or closed) with high fidelity. It also allows for accurate and efficient computation of local geometric properties. We further demonstrate that it leads to efficient implementation of downstream algorithms like sphere-tracing for rendering the 3D surface as well as to create explicit mesh-based representations. Extensive experimental evaluation on the ShapeNet dataset validate the above contributions with results surpassing the state-of-the-art.
DUDE: Deep Unsigned Distance Embeddings for Hi-Fidelity Representation of Complex 3D Surfaces
Nov 04, 2020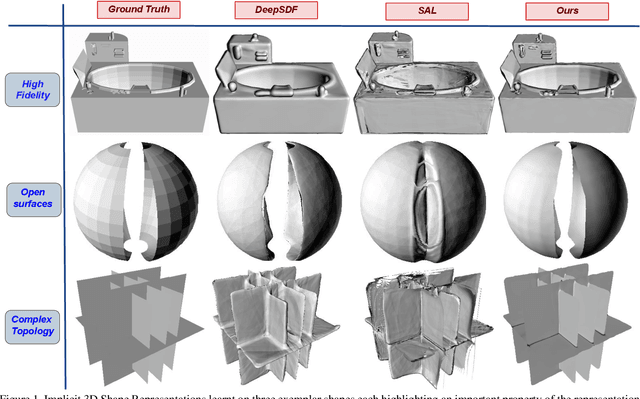
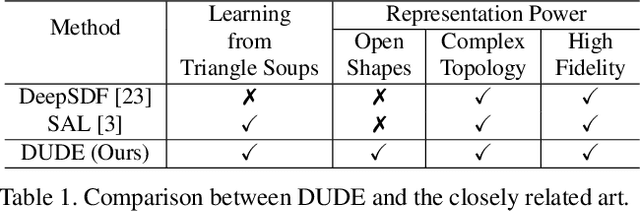
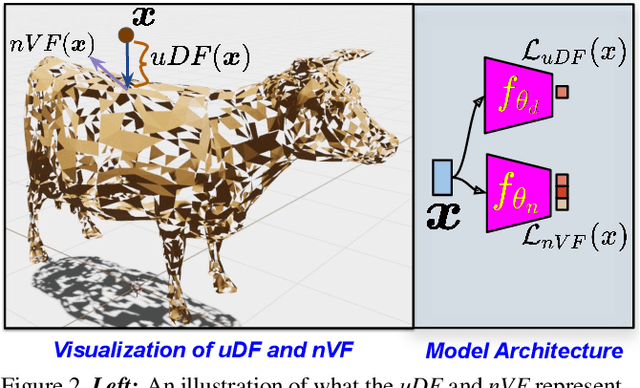
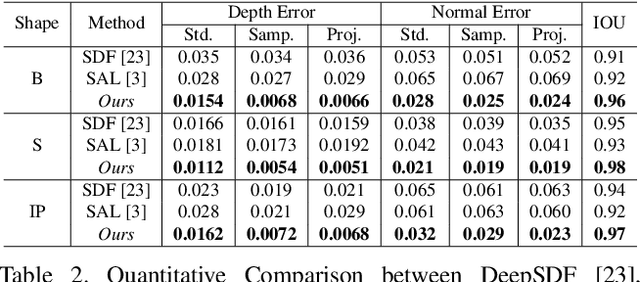
High fidelity representation of shapes with arbitrary topology is an important problem for a variety of vision and graphics applications. Owing to their limited resolution, classical discrete shape representations using point clouds, voxels and meshes produce low quality results when used in these applications. Several implicit 3D shape representation approaches using deep neural networks have been proposed leading to significant improvements in both quality of representations as well as the impact on downstream applications. However, these methods can only be used to represent topologically closed shapes which greatly limits the class of shapes that they can represent. As a consequence, they also often require clean, watertight meshes for training. In this work, we propose DUDE - a Deep Unsigned Distance Embedding method which alleviates both of these shortcomings. DUDE is a disentangled shape representation that utilizes an unsigned distance field (uDF) to represent proximity to a surface, and a normal vector field (nVF) to represent surface orientation. We show that a combination of these two (uDF+nVF) can be used to learn high fidelity representations for arbitrary open/closed shapes. As opposed to prior work such as DeepSDF, our shape representations can be directly learnt from noisy triangle soups, and do not need watertight meshes. Additionally, we propose novel algorithms for extracting and rendering iso-surfaces from the learnt representations. We validate DUDE on benchmark 3D datasets and demonstrate that it produces significant improvements over the state of the art.
To Beta or Not To Beta: Information Bottleneck for DigitaL Image Forensics
Aug 11, 2019
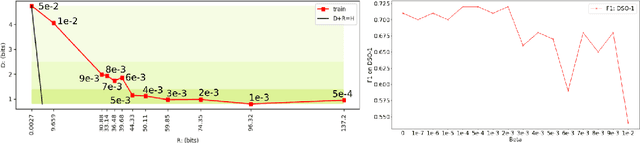

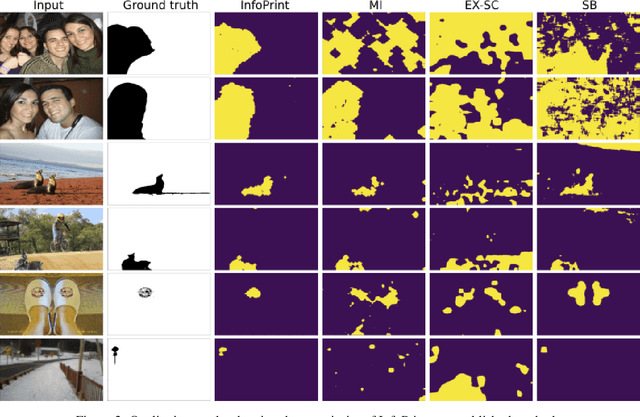
We consider an information theoretic approach to address the problem of identifying fake digital images. We propose an innovative method to formulate the issue of localizing manipulated regions in an image as a deep representation learning problem using the Information Bottleneck (IB), which has recently gained popularity as a framework for interpreting deep neural networks. Tampered images pose a serious predicament since digitized media is a ubiquitous part of our lives. These are facilitated by the easy availability of image editing software and aggravated by recent advances in deep generative models such as GANs. We propose InfoPrint, a computationally efficient solution to the IB formulation using approximate variational inference and compare it to a numerical solution that is computationally expensive. Testing on a number of standard datasets, we demonstrate that InfoPrint outperforms the state-of-the-art and the numerical solution. Additionally, it also has the ability to detect alterations made by inpainting GANs.
Uncertainty Quantification in Deep Learning for Safer Neuroimage Enhancement
Jul 31, 2019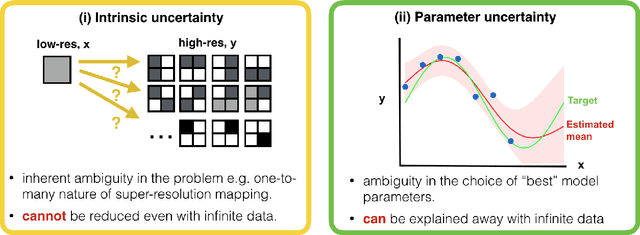

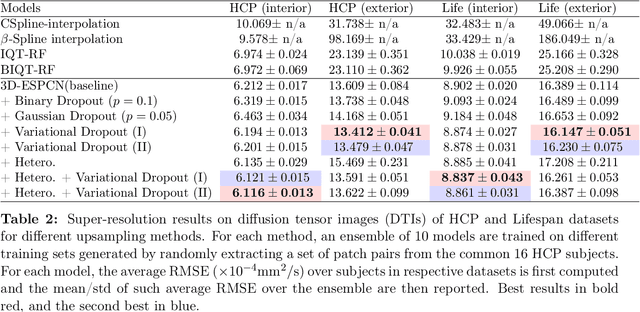
Deep learning (DL) has shown great potential in medical image enhancement problems, such as super-resolution or image synthesis. However, to date, little consideration has been given to uncertainty quantification over the output image. Here we introduce methods to characterise different components of uncertainty in such problems and demonstrate the ideas using diffusion MRI super-resolution. Specifically, we propose to account for $intrinsic$ uncertainty through a heteroscedastic noise model and for $parameter$ uncertainty through approximate Bayesian inference, and integrate the two to quantify $predictive$ uncertainty over the output image. Moreover, we introduce a method to propagate the predictive uncertainty on a multi-channelled image to derived scalar parameters, and separately quantify the effects of intrinsic and parameter uncertainty therein. The methods are evaluated for super-resolution of two different signal representations of diffusion MR images---DTIs and Mean Apparent Propagator MRI---and their derived quantities such as MD and FA, on multiple datasets of both healthy and pathological human brains. Results highlight three key benefits of uncertainty modelling for improving the safety of DL-based image enhancement systems. Firstly, incorporating uncertainty improves the predictive performance even when test data departs from training data. Secondly, the predictive uncertainty highly correlates with errors, and is therefore capable of detecting predictive "failures". Results demonstrate that such an uncertainty measure enables subject-specific and voxel-wise risk assessment of the output images. Thirdly, we show that the method for decomposing predictive uncertainty into its independent sources provides high-level "explanations" for the performance by quantifying how much uncertainty arises from the inherent difficulty of the task or the limited training examples.
SpliceRadar: A Learned Method For Blind Image Forensics
Jun 27, 2019

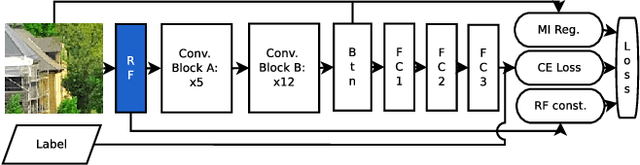
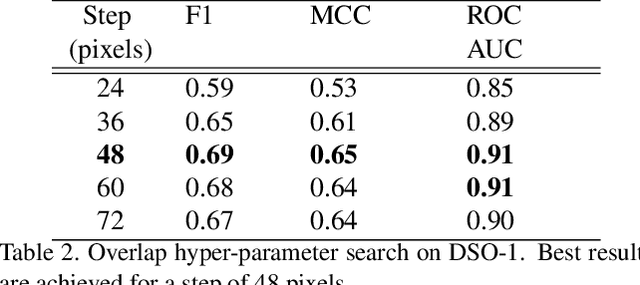
Detection and localization of image manipulations like splices are gaining in importance with the easy accessibility of image editing softwares. While detection generates a verdict for an image it provides no insight into the manipulation. Localization helps explain a positive detection by identifying the pixels of the image which have been tampered. We propose a deep learning based method for splice localization without prior knowledge of a test image's camera-model. It comprises a novel approach for learning rich filters and for suppressing image-edges. Additionally, we train our model on a surrogate task of camera model identification, which allows us to leverage large and widely available, unmanipulated, camera-tagged image databases. During inference, we assume that the spliced and host regions come from different camera-models and we segment these regions using a Gaussian-mixture model. Experiments on three test databases demonstrate results on par with and above the state-of-the-art and a good generalization ability to unknown datasets.
Bayesian Image Quality Transfer with CNNs: Exploring Uncertainty in dMRI Super-Resolution
May 30, 2017
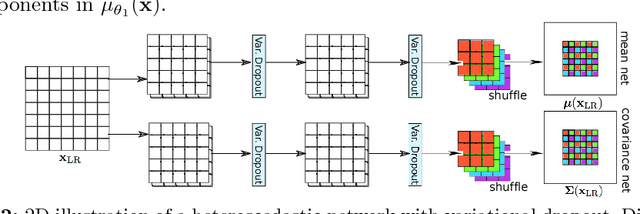
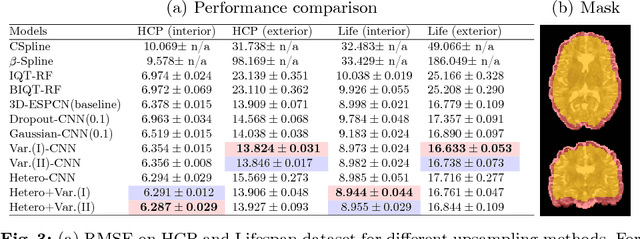
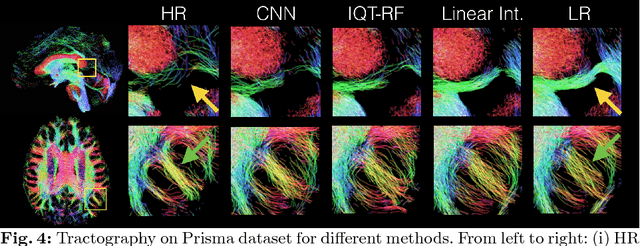
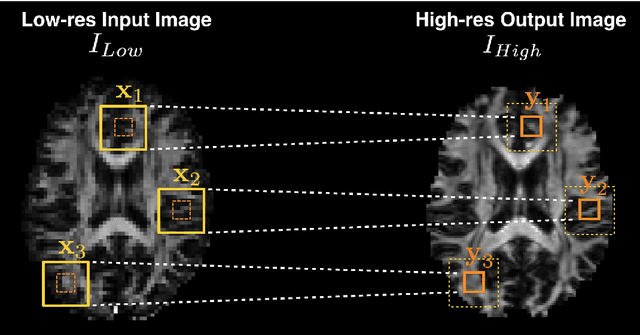
In this work, we investigate the value of uncertainty modeling in 3D super-resolution with convolutional neural networks (CNNs). Deep learning has shown success in a plethora of medical image transformation problems, such as super-resolution (SR) and image synthesis. However, the highly ill-posed nature of such problems results in inevitable ambiguity in the learning of networks. We propose to account for intrinsic uncertainty through a per-patch heteroscedastic noise model and for parameter uncertainty through approximate Bayesian inference in the form of variational dropout. We show that the combined benefits of both lead to the state-of-the-art performance SR of diffusion MR brain images in terms of errors compared to ground truth. We further show that the reduced error scores produce tangible benefits in downstream tractography. In addition, the probabilistic nature of the methods naturally confers a mechanism to quantify uncertainty over the super-resolved output. We demonstrate through experiments on both healthy and pathological brains the potential utility of such an uncertainty measure in the risk assessment of the super-resolved images for subsequent clinical use.