 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoStream: Toward Precise Camera Controlled Streaming Video Generation
Jun 13, 2026Accurate interactive camera control is essential for video-based world models, but most existing approaches learn camera motion implicitly, leading to inaccurate control under out-of-distribution trajectories. Explicit geometric conditioning improves controllability, but existing methods are non-autoregressive and rely on a static 3D cache built from an initial frame, which becomes ineffective once the viewpoint moves beyond the original frustum. We propose GeoStream, a framework that enables precise metric-scale camera control in autoregressive streaming video generation. Our method maintains a self-refreshing 3D cache that is periodically updated online from the model's own outputs: we estimate depth from the most recently generated frame, unproject to 3D, and reproject into the target view to produce point reprojections as geometric conditioning for subsequent synthesis. By the same principle, the conditioning seen during training is also rendered from the student's own generated frames, yielding a fully on-policy distillation that naturally aligns the train and inference conditioning distributions. Unlike prior work that uses off-policy condition noising, our approach trains the model against the exact error distribution it encounters at inference, mitigating both standard autoregressive drift and the second-order geometric feedback loop that arises when the cache itself is derived from generated outputs. Quantitative and qualitative results show that our approach substantially improves camera controllability.
High Fidelity 3D Reconstructions with Limited Physical Views
Oct 22, 2021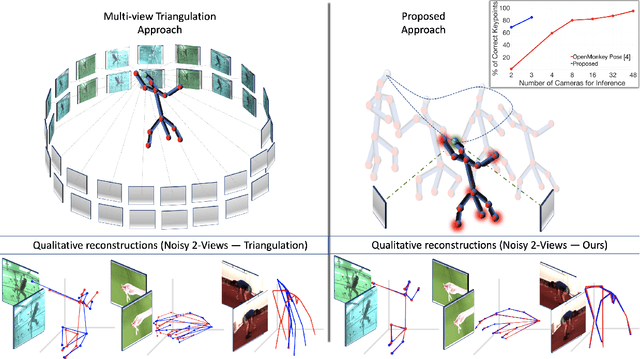

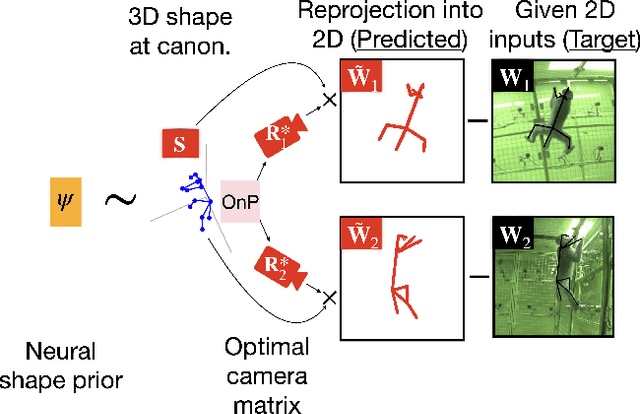

Multi-view triangulation is the gold standard for 3D reconstruction from 2D correspondences given known calibration and sufficient views. However in practice, expensive multi-view setups -- involving tens sometimes hundreds of cameras -- are required in order to obtain the high fidelity 3D reconstructions necessary for many modern applications. In this paper we present a novel approach that leverages recent advances in 2D-3D lifting using neural shape priors while also enforcing multi-view equivariance. We show how our method can achieve comparable fidelity to expensive calibrated multi-view rigs using a limited (2-3) number of uncalibrated camera views.
DUDE: Deep Unsigned Distance Embeddings for Hi-Fidelity Representation of Complex 3D Surfaces
Nov 04, 2020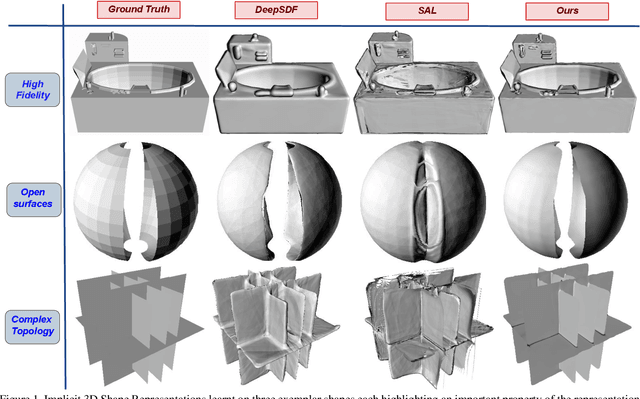
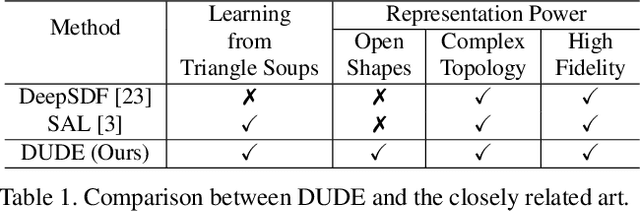
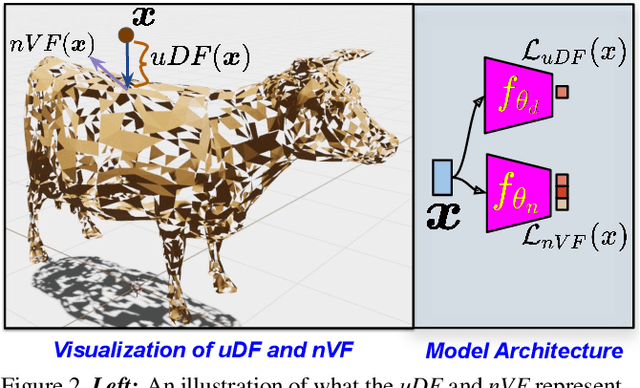
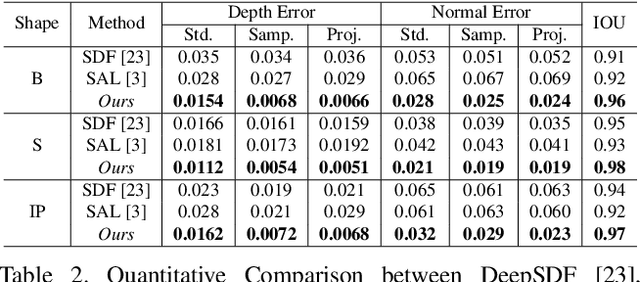
High fidelity representation of shapes with arbitrary topology is an important problem for a variety of vision and graphics applications. Owing to their limited resolution, classical discrete shape representations using point clouds, voxels and meshes produce low quality results when used in these applications. Several implicit 3D shape representation approaches using deep neural networks have been proposed leading to significant improvements in both quality of representations as well as the impact on downstream applications. However, these methods can only be used to represent topologically closed shapes which greatly limits the class of shapes that they can represent. As a consequence, they also often require clean, watertight meshes for training. In this work, we propose DUDE - a Deep Unsigned Distance Embedding method which alleviates both of these shortcomings. DUDE is a disentangled shape representation that utilizes an unsigned distance field (uDF) to represent proximity to a surface, and a normal vector field (nVF) to represent surface orientation. We show that a combination of these two (uDF+nVF) can be used to learn high fidelity representations for arbitrary open/closed shapes. As opposed to prior work such as DeepSDF, our shape representations can be directly learnt from noisy triangle soups, and do not need watertight meshes. Additionally, we propose novel algorithms for extracting and rendering iso-surfaces from the learnt representations. We validate DUDE on benchmark 3D datasets and demonstrate that it produces significant improvements over the state of the art.
Brute-Force Facial Landmark Analysis With A 140,000-Way Classifier
Feb 14, 2018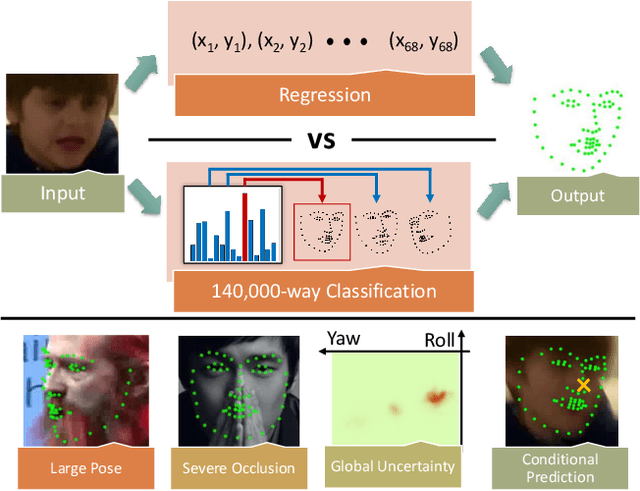



We propose a simple approach to visual alignment, focusing on the illustrative task of facial landmark estimation. While most prior work treats this as a regression problem, we instead formulate it as a discrete $K$-way classification task, where a classifier is trained to return one of $K$ discrete alignments. One crucial benefit of a classifier is the ability to report back a (softmax) distribution over putative alignments. We demonstrate that this distribution is a rich representation that can be marginalized (to generate uncertainty estimates over groups of landmarks) and conditioned on (to incorporate top-down context, provided by temporal constraints in a video stream or an interactive human user). Such capabilities are difficult to integrate into classic regression-based approaches. We study performance as a function of the number of classes $K$, including the extreme "exemplar class" setting where $K$ is equal to the number of training examples (140K in our setting). Perhaps surprisingly, we show that classifiers can still be learned in this setting. When compared to prior work in classification, our $K$ is unprecedentedly large, including many "fine-grained" classes that are very similar. We address these issues by using a multi-label loss function that allows for training examples to be non-uniformly shared across discrete classes. We perform a comprehensive experimental analysis of our method on standard benchmarks, demonstrating state-of-the-art results for facial alignment in videos.
Emotional Expression Classification using Time-Series Kernels
Jun 08, 2013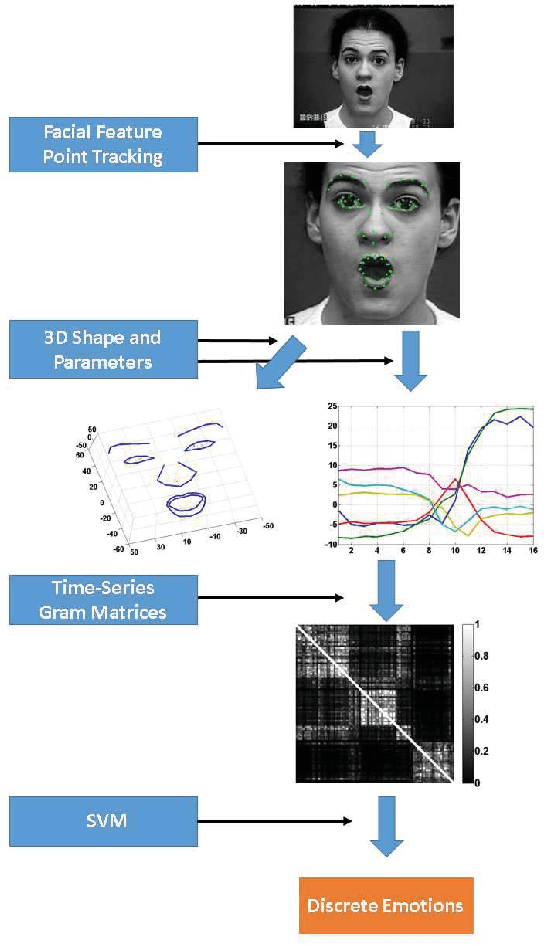

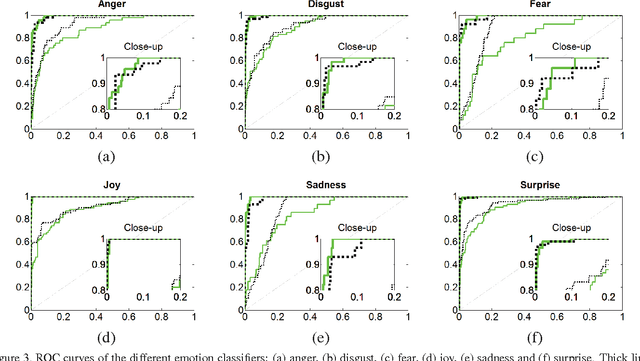
Estimation of facial expressions, as spatio-temporal processes, can take advantage of kernel methods if one considers facial landmark positions and their motion in 3D space. We applied support vector classification with kernels derived from dynamic time-warping similarity measures. We achieved over 99% accuracy - measured by area under ROC curve - using only the 'motion pattern' of the PCA compressed representation of the marker point vector, the so-called shape parameters. Beyond the classification of full motion patterns, several expressions were recognized with over 90% accuracy in as few as 5-6 frames from their onset, about 200 milliseconds.