 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrute-Force Facial Landmark Analysis With A 140,000-Way Classifier
Paper and Code
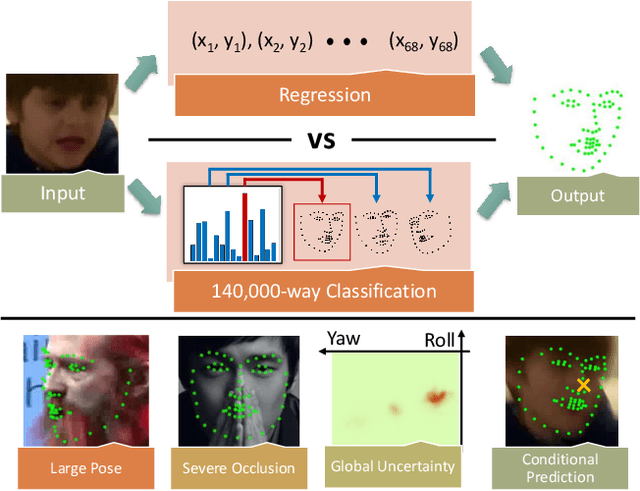



We propose a simple approach to visual alignment, focusing on the illustrative task of facial landmark estimation. While most prior work treats this as a regression problem, we instead formulate it as a discrete $K$-way classification task, where a classifier is trained to return one of $K$ discrete alignments. One crucial benefit of a classifier is the ability to report back a (softmax) distribution over putative alignments. We demonstrate that this distribution is a rich representation that can be marginalized (to generate uncertainty estimates over groups of landmarks) and conditioned on (to incorporate top-down context, provided by temporal constraints in a video stream or an interactive human user). Such capabilities are difficult to integrate into classic regression-based approaches. We study performance as a function of the number of classes $K$, including the extreme "exemplar class" setting where $K$ is equal to the number of training examples (140K in our setting). Perhaps surprisingly, we show that classifiers can still be learned in this setting. When compared to prior work in classification, our $K$ is unprecedentedly large, including many "fine-grained" classes that are very similar. We address these issues by using a multi-label loss function that allows for training examples to be non-uniformly shared across discrete classes. We perform a comprehensive experimental analysis of our method on standard benchmarks, demonstrating state-of-the-art results for facial alignment in videos.