 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Siamese Network to Detect If Two Iris Images Are Monozygotic
Mar 12, 2025In Daugman-style iris recognition, the textures of the left and right irises of the same person are traditionally considered as being as different as the irises of two unrelated persons. However, previous research indicates that humans can detect that two iris images are from different eyes of the same person, or eyes of monozygotic twins, with an accuracy of about 80%. In this work, we employ a Siamese network architecture and contrastive learning to categorize a pair of iris images as coming from monozygotic or non-monozygotic irises. This could potentially be applied, for example, as a fast, noninvasive test to determine if twins are monozygotic or non-monozygotic. We construct a dataset comprising both synthetic monozygotic pairs (images of different irises of the same individual) and natural monozygotic pairs (images of different images from persons who are identical twins), in addition to non-monozygotic pairs from unrelated individuals, ensuring a comprehensive evaluation of the model's capabilities. To gain deeper insights into the learned representations, we train and analyze three variants of the model using (1) the original input images, (2) iris-only images, and (3) non-iris-only images. This comparison reveals the critical importance of iris-specific textural details and contextual ocular cues in identifying monozygotic iris patterns. The results demonstrate that models leveraging full eye-region information outperform those trained solely on iris-only data, emphasizing the nuanced interplay between iris and ocular characteristics. Our approach achieves accuracy levels using the full iris image that exceed those previously reported for human classification of monozygotic iris pairs. This study presents the first classifier designed to determine whether a pair of iris images originates from monozygotic individuals.
Protecting Privacy in Multimodal Large Language Models with MLLMU-Bench
Oct 29, 2024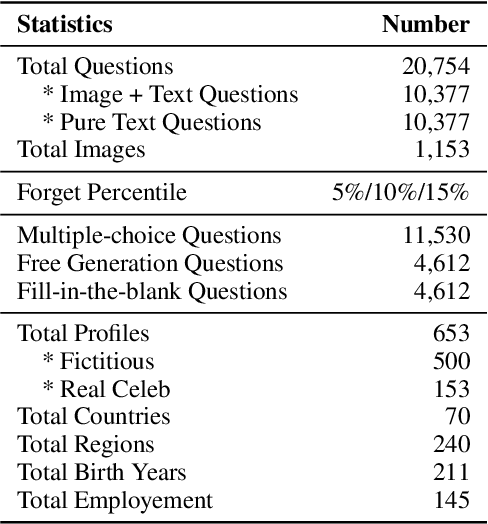
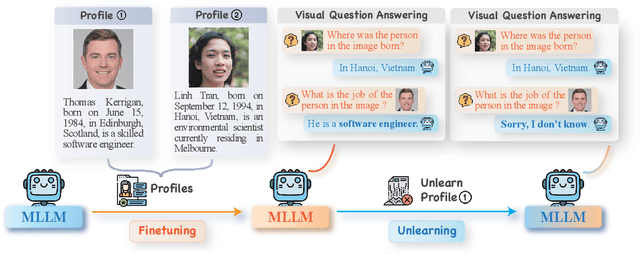

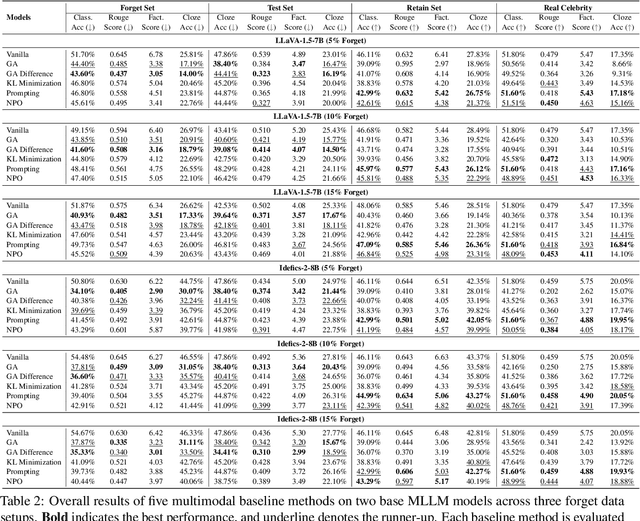
Generative models such as Large Language Models (LLM) and Multimodal Large Language models (MLLMs) trained on massive web corpora can memorize and disclose individuals' confidential and private data, raising legal and ethical concerns. While many previous works have addressed this issue in LLM via machine unlearning, it remains largely unexplored for MLLMs. To tackle this challenge, we introduce Multimodal Large Language Model Unlearning Benchmark (MLLMU-Bench), a novel benchmark aimed at advancing the understanding of multimodal machine unlearning. MLLMU-Bench consists of 500 fictitious profiles and 153 profiles for public celebrities, each profile feature over 14 customized question-answer pairs, evaluated from both multimodal (image+text) and unimodal (text) perspectives. The benchmark is divided into four sets to assess unlearning algorithms in terms of efficacy, generalizability, and model utility. Finally, we provide baseline results using existing generative model unlearning algorithms. Surprisingly, our experiments show that unimodal unlearning algorithms excel in generation and cloze tasks, while multimodal unlearning approaches perform better in classification tasks with multimodal inputs.