 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressed Models Decompress Race Biases: What Quantized Models Forget for Fair Face Recognition
Paper and Code
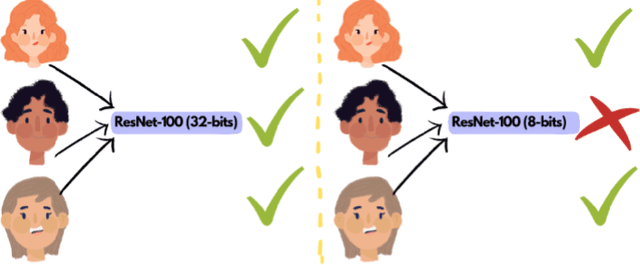
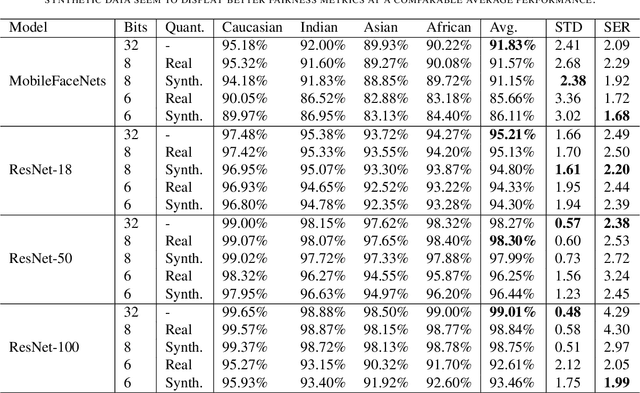
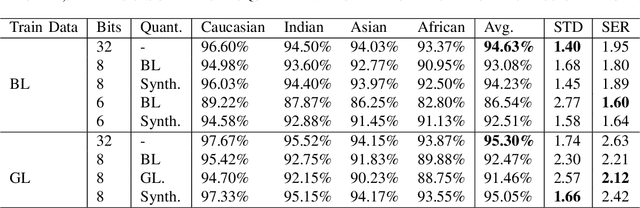
With the ever-growing complexity of deep learning models for face recognition, it becomes hard to deploy these systems in real life. Researchers have two options: 1) use smaller models; 2) compress their current models. Since the usage of smaller models might lead to concerning biases, compression gains relevance. However, compressing might be also responsible for an increase in the bias of the final model. We investigate the overall performance, the performance on each ethnicity subgroup and the racial bias of a State-of-the-Art quantization approach when used with synthetic and real data. This analysis provides a few more details on potential benefits of performing quantization with synthetic data, for instance, the reduction of biases on the majority of test scenarios. We tested five distinct architectures and three different training datasets. The models were evaluated on a fourth dataset which was collected to infer and compare the performance of face recognition models on different ethnicity.