 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCEvo: Path-Consistent Molecular Representation via Virtual Evolutionary
Jan 27, 2026Molecular representation learning aims to learn vector embeddings that capture molecular structure and geometry, thereby enabling property prediction and downstream scientific applications. In many AI for science tasks, labeled data are expensive to obtain and therefore limited in availability. Under the few-shot setting, models trained with scarce supervision often learn brittle structure-property relationships, resulting in substantially higher prediction errors and reduced generalization to unseen molecules. To address this limitation, we propose PCEvo, a path-consistent representation method that learns from virtual paths through dynamic structural evolution. PCEvo enumerates multiple chemically feasible edit paths between retrieved similar molecular pairs under topological dependency constraints. It transforms the labels of the two molecules into stepwise supervision along each virtual evolutionary path. It introduces a path-consistency objective that enforces prediction invariance across alternative paths connecting the same two molecules. Comprehensive experiments on the QM9 and MoleculeNet datasets demonstrate that PCEvo substantially improves the few-shot generalization performance of baseline methods. The code is available at https://anonymous.4open.science/r/PCEvo-4BF2.
Antibody Design and Optimization with Multi-scale Equivariant Graph Diffusion Models for Accurate Complex Antigen Binding
Jun 26, 2025Antibody design remains a critical challenge in therapeutic and diagnostic development, particularly for complex antigens with diverse binding interfaces. Current computational methods face two main limitations: (1) capturing geometric features while preserving symmetries, and (2) generalizing novel antigen interfaces. Despite recent advancements, these methods often fail to accurately capture molecular interactions and maintain structural integrity. To address these challenges, we propose \textbf{AbMEGD}, an end-to-end framework integrating \textbf{M}ulti-scale \textbf{E}quivariant \textbf{G}raph \textbf{D}iffusion for antibody sequence and structure co-design. Leveraging advanced geometric deep learning, AbMEGD combines atomic-level geometric features with residue-level embeddings, capturing local atomic details and global sequence-structure interactions. Its E(3)-equivariant diffusion method ensures geometric precision, computational efficiency, and robust generalizability for complex antigens. Furthermore, experiments using the SAbDab database demonstrate a 10.13\% increase in amino acid recovery, 3.32\% rise in improvement percentage, and a 0.062~\AA\ reduction in root mean square deviation within the critical CDR-H3 region compared to DiffAb, a leading antibody design model. These results highlight AbMEGD's ability to balance structural integrity with improved functionality, establishing a new benchmark for sequence-structure co-design and affinity optimization. The code is available at: https://github.com/Patrick221215/AbMEGD.
KaFT: Knowledge-aware Fine-tuning for Boosting LLMs' Domain-specific Question-Answering Performance
May 21, 2025Supervised fine-tuning (SFT) is a common approach to improve the domain-specific question-answering (QA) performance of large language models (LLMs). However, recent literature reveals that due to the conflicts between LLMs' internal knowledge and the context knowledge of training data, vanilla SFT using the full QA training set is usually suboptimal. In this paper, we first design a query diversification strategy for robust conflict detection and then conduct a series of experiments to analyze the impact of knowledge conflict. We find that 1) training samples with varied conflicts contribute differently, where SFT on the data with large conflicts leads to catastrophic performance drops; 2) compared to directly filtering out the conflict data, appropriately applying the conflict data would be more beneficial. Motivated by this, we propose a simple-yet-effective Knowledge-aware Fine-tuning (namely KaFT) approach to effectively boost LLMs' performance. The core of KaFT is to adapt the training weight by assigning different rewards for different training samples according to conflict level. Extensive experiments show that KaFT brings consistent and significant improvements across four LLMs. More analyses prove that KaFT effectively improves the model generalization and alleviates the hallucination.
Reasoning-OCR: Can Large Multimodal Models Solve Complex Logical Reasoning Problems from OCR Cues?
May 19, 2025Large Multimodal Models (LMMs) have become increasingly versatile, accompanied by impressive Optical Character Recognition (OCR) related capabilities. Existing OCR-related benchmarks emphasize evaluating LMMs' abilities of relatively simple visual question answering, visual-text parsing, etc. However, the extent to which LMMs can deal with complex logical reasoning problems based on OCR cues is relatively unexplored. To this end, we introduce the Reasoning-OCR benchmark, which challenges LMMs to solve complex reasoning problems based on the cues that can be extracted from rich visual-text. Reasoning-OCR covers six visual scenarios and encompasses 150 meticulously designed questions categorized into six reasoning challenges. Additionally, Reasoning-OCR minimizes the impact of field-specialized knowledge. Our evaluation offers some insights for proprietary and open-source LMMs in different reasoning challenges, underscoring the urgent to improve the reasoning performance. We hope Reasoning-OCR can inspire and facilitate future research on enhancing complex reasoning ability based on OCR cues. Reasoning-OCR is publicly available at https://github.com/Hxyz-123/ReasoningOCR.
3D Human Interaction Generation: A Survey
Mar 17, 20253D human interaction generation has emerged as a key research area, focusing on producing dynamic and contextually relevant interactions between humans and various interactive entities. Recent rapid advancements in 3D model representation methods, motion capture technologies, and generative models have laid a solid foundation for the growing interest in this domain. Existing research in this field can be broadly categorized into three areas: human-scene interaction, human-object interaction, and human-human interaction. Despite the rapid advancements in this area, challenges remain due to the need for naturalness in human motion generation and the accurate interaction between humans and interactive entities. In this survey, we present a comprehensive literature review of human interaction generation, which, to the best of our knowledge, is the first of its kind. We begin by introducing the foundational technologies, including model representations, motion capture methods, and generative models. Subsequently, we introduce the approaches proposed for the three sub-tasks, along with their corresponding datasets and evaluation metrics. Finally, we discuss potential future research directions in this area and conclude the survey. Through this survey, we aim to offer a comprehensive overview of the current advancements in the field, highlight key challenges, and inspire future research works.
ELBA-Bench: An Efficient Learning Backdoor Attacks Benchmark for Large Language Models
Feb 22, 2025



Generative large language models are crucial in natural language processing, but they are vulnerable to backdoor attacks, where subtle triggers compromise their behavior. Although backdoor attacks against LLMs are constantly emerging, existing benchmarks remain limited in terms of sufficient coverage of attack, metric system integrity, backdoor attack alignment. And existing pre-trained backdoor attacks are idealized in practice due to resource access constraints. Therefore we establish $\textit{ELBA-Bench}$, a comprehensive and unified framework that allows attackers to inject backdoor through parameter efficient fine-tuning ($\textit{e.g.,}$ LoRA) or without fine-tuning techniques ($\textit{e.g.,}$ In-context-learning). $\textit{ELBA-Bench}$ provides over 1300 experiments encompassing the implementations of 12 attack methods, 18 datasets, and 12 LLMs. Extensive experiments provide new invaluable findings into the strengths and limitations of various attack strategies. For instance, PEFT attack consistently outperform without fine-tuning approaches in classification tasks while showing strong cross-dataset generalization with optimized triggers boosting robustness; Task-relevant backdoor optimization techniques or attack prompts along with clean and adversarial demonstrations can enhance backdoor attack success while preserving model performance on clean samples. Additionally, we introduce a universal toolbox designed for standardized backdoor attack research, with the goal of propelling further progress in this vital area.
Small Molecule Drug Discovery Through Deep Learning:Progress, Challenges, and Opportunities
Feb 13, 2025Due to their excellent drug-like and pharmacokinetic properties, small molecule drugs are widely used to treat various diseases, making them a critical component of drug discovery. In recent years, with the rapid development of deep learning (DL) techniques, DL-based small molecule drug discovery methods have achieved excellent performance in prediction accuracy, speed, and complex molecular relationship modeling compared to traditional machine learning approaches. These advancements enhance drug screening efficiency and optimization, and they provide more precise and effective solutions for various drug discovery tasks. Contributing to this field's development, this paper aims to systematically summarize and generalize the recent key tasks and representative techniques in DL-based small molecule drug discovery in recent years. Specifically, we provide an overview of the major tasks in small molecule drug discovery and their interrelationships. Next, we analyze the six core tasks, summarizing the related methods, commonly used datasets, and technological development trends. Finally, we discuss key challenges, such as interpretability and out-of-distribution generalization, and offer our insights into future research directions for DL-assisted small molecule drug discovery.
Can Molecular Evolution Mechanism Enhance Molecular Representation?
Jan 27, 2025Molecular evolution is the process of simulating the natural evolution of molecules in chemical space to explore potential molecular structures and properties. The relationships between similar molecules are often described through transformations such as adding, deleting, and modifying atoms and chemical bonds, reflecting specific evolutionary paths. Existing molecular representation methods mainly focus on mining data, such as atomic-level structures and chemical bonds directly from the molecules, often overlooking their evolutionary history. Consequently, we aim to explore the possibility of enhancing molecular representations by simulating the evolutionary process. We extract and analyze the changes in the evolutionary pathway and explore combining it with existing molecular representations. Therefore, this paper proposes the molecular evolutionary network (MEvoN) for molecular representations. First, we construct the MEvoN using molecules with a small number of atoms and generate evolutionary paths utilizing similarity calculations. Then, by modeling the atomic-level changes, MEvoN reveals their impact on molecular properties. Experimental results show that the MEvoN-based molecular property prediction method significantly improves the performance of traditional end-to-end algorithms on several molecular datasets. The code is available at https://anonymous.4open.science/r/MEvoN-7416/.
Fragment-Masked Molecular Optimization
Aug 17, 2024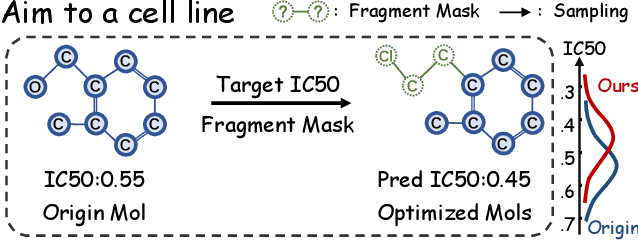



Molecular optimization is a crucial aspect of drug discovery, aimed at refining molecular structures to enhance drug efficacy and minimize side effects, ultimately accelerating the overall drug development process. Many target-based molecular optimization methods have been proposed, significantly advancing drug discovery. These methods primarily on understanding the specific drug target structures or their hypothesized roles in combating diseases. However, challenges such as a limited number of available targets and a difficulty capturing clear structures hinder innovative drug development. In contrast, phenotypic drug discovery (PDD) does not depend on clear target structures and can identify hits with novel and unbiased polypharmacology signatures. As a result, PDD-based molecular optimization can reduce potential safety risks while optimizing phenotypic activity, thereby increasing the likelihood of clinical success. Therefore, we propose a fragment-masked molecular optimization method based on PDD (FMOP). FMOP employs a regression-free diffusion model to conditionally optimize the molecular masked regions without training, effectively generating new molecules with similar scaffolds. On the large-scale drug response dataset GDSCv2, we optimize the potential molecules across all 945 cell lines. The overall experiments demonstrate that the in-silico optimization success rate reaches 94.4%, with an average efficacy increase of 5.3%. Additionally, we conduct extensive ablation and visualization experiments, confirming that FMOP is an effective and robust molecular optimization method. The code is available at:https://anonymous.4open.science/r/FMOP-98C2.
TextIM: Part-aware Interactive Motion Synthesis from Text
Aug 06, 2024In this work, we propose TextIM, a novel framework for synthesizing TEXT-driven human Interactive Motions, with a focus on the precise alignment of part-level semantics. Existing methods often overlook the critical roles of interactive body parts and fail to adequately capture and align part-level semantics, resulting in inaccuracies and even erroneous movement outcomes. To address these issues, TextIM utilizes a decoupled conditional diffusion framework to enhance the detailed alignment between interactive movements and corresponding semantic intents from textual descriptions. Our approach leverages large language models, functioning as a human brain, to identify interacting human body parts and to comprehend interaction semantics to generate complicated and subtle interactive motion. Guided by the refined movements of the interacting parts, TextIM further extends these movements into a coherent whole-body motion. We design a spatial coherence module to complement the entire body movements while maintaining consistency and harmony across body parts using a part graph convolutional network. For training and evaluation, we carefully selected and re-labeled interactive motions from HUMANML3D to develop a specialized dataset. Experimental results demonstrate that TextIM produces semantically accurate human interactive motions, significantly enhancing the realism and applicability of synthesized interactive motions in diverse scenarios, even including interactions with deformable and dynamically changing objects.