 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHi-SAM: Marrying Segment Anything Model for Hierarchical Text Segmentation
Jan 31, 2024



The Segment Anything Model (SAM), a profound vision foundation model pre-trained on a large-scale dataset, breaks the boundaries of general segmentation and sparks various downstream applications. This paper introduces Hi-SAM, a unified model leveraging SAM for hierarchical text segmentation. Hi-SAM excels in text segmentation across four hierarchies, including stroke, word, text-line, and paragraph, while realizing layout analysis as well. Specifically, we first turn SAM into a high-quality text stroke segmentation (TSS) model through a parameter-efficient fine-tuning approach. We use this TSS model to iteratively generate the text stroke labels in a semi-automatical manner, unifying labels across the four text hierarchies in the HierText dataset. Subsequently, with these complete labels, we launch the end-to-end trainable Hi-SAM based on the TSS architecture with a customized hierarchical mask decoder. During inference, Hi-SAM offers both automatic mask generation (AMG) mode and promptable segmentation mode. In terms of the AMG mode, Hi-SAM segments text stroke foreground masks initially, then samples foreground points for hierarchical text mask generation and achieves layout analysis in passing. As for the promptable mode, Hi-SAM provides word, text-line, and paragraph masks with a single point click. Experimental results show the state-of-the-art performance of our TSS model: 84.86% fgIOU on Total-Text and 88.96% fgIOU on TextSeg for text stroke segmentation. Moreover, compared to the previous specialist for joint hierarchical detection and layout analysis on HierText, Hi-SAM achieves significant improvements: 4.73% PQ and 5.39% F1 on the text-line level, 5.49% PQ and 7.39% F1 on the paragraph level layout analysis, requiring 20x fewer training epochs. The code is available at https://github.com/ymy-k/Hi-SAM.
GoMatching: A Simple Baseline for Video Text Spotting via Long and Short Term Matching
Jan 13, 2024Beyond the text detection and recognition tasks in image text spotting, video text spotting presents an augmented challenge with the inclusion of tracking. While advanced end-to-end trainable methods have shown commendable performance, the pursuit of multi-task optimization may pose the risk of producing sub-optimal outcomes for individual tasks. In this paper, we highlight a main bottleneck in the state-of-the-art video text spotter: the limited recognition capability. In response to this issue, we propose to efficiently turn an off-the-shelf query-based image text spotter into a specialist on video and present a simple baseline termed GoMatching, which focuses the training efforts on tracking while maintaining strong recognition performance. To adapt the image text spotter to video datasets, we add a rescoring head to rescore each detected instance's confidence via efficient tuning, leading to a better tracking candidate pool. Additionally, we design a long-short term matching module, termed LST-Matcher, to enhance the spotter's tracking capability by integrating both long- and short-term matching results via Transformer. Based on the above simple designs, GoMatching achieves impressive performance on two public benchmarks, e.g., setting a new record on the ICDAR15-video dataset, and one novel test set with arbitrary-shaped text, while saving considerable training budgets. The code will be released at https://github.com/Hxyz-123/GoMatching.
DeepSolo++: Let Transformer Decoder with Explicit Points Solo for Text Spotting
May 31, 2023End-to-end text spotting aims to integrate scene text detection and recognition into a unified framework. Dealing with the relationship between the two sub-tasks plays a pivotal role in designing effective spotters. Although Transformer-based methods eliminate the heuristic post-processing, they still suffer from the synergy issue between the sub-tasks and low training efficiency. In this paper, we present DeepSolo, a simple DETR-like baseline that lets a single decoder with explicit points solo for text detection and recognition simultaneously and efficiently. Technically, for each text instance, we represent the character sequence as ordered points and model them with learnable explicit point queries. After passing a single decoder, the point queries have encoded requisite text semantics and locations. Furthermore, we show the surprisingly good extensibility of our method, in terms of character class, language type, and task. On the one hand, DeepSolo not only performs well in English scenes but also masters the Chinese transcription with complex font structure and a thousand-level character classes. On the other hand, based on the extensibility of DeepSolo, we launch DeepSolo++ for multilingual text spotting, making a further step to let Transformer decoder with explicit points solo for multilingual text detection, recognition, and script identification all at once. Extensive experiments on public benchmarks demonstrate that our simple approach achieves better training efficiency compared with Transformer-based models and outperforms the previous state-of-the-art. In addition, DeepSolo and DeepSolo++ are also compatible with line annotations, which require much less annotation cost than polygons. The code is available at \url{https://github.com/ViTAE-Transformer/DeepSolo}.
DeepSolo: Let Transformer Decoder with Explicit Points Solo for Text Spotting
Nov 23, 2022

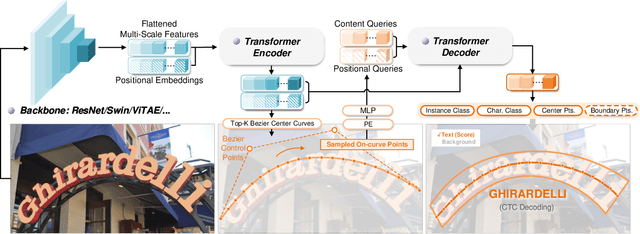

End-to-end text spotting aims to integrate scene text detection and recognition into a unified framework. Dealing with the relationship between the two sub-tasks plays a pivotal role in designing effective spotters. Although transformer-based methods eliminate the heuristic post-processing, they still suffer from the synergy issue between the sub-tasks and low training efficiency. In this paper, we present DeepSolo, a simple detection transformer baseline that lets a single Decoder with Explicit Points Solo for text detection and recognition simultaneously. Technically, for each text instance, we represent the character sequence as ordered points and model them with learnable explicit point queries. After passing a single decoder, the point queries have encoded requisite text semantics and locations and thus can be further decoded to the center line, boundary, script, and confidence of text via very simple prediction heads in parallel, solving the sub-tasks in text spotting in a unified framework. Besides, we also introduce a text-matching criterion to deliver more accurate supervisory signals, thus enabling more efficient training. Quantitative experiments on public benchmarks demonstrate that DeepSolo outperforms previous state-of-the-art methods and achieves better training efficiency. In addition, DeepSolo is also compatible with line annotations, which require much less annotation cost than polygons. The code will be released.
DPText-DETR: Towards Better Scene Text Detection with Dynamic Points in Transformer
Jul 10, 2022



Recently, Transformer-based methods, which predict polygon points or Bezier curve control points to localize texts, are quite popular in scene text detection. However, the used point label form implies the reading order of humans, which affects the robustness of Transformer model. As for the model architecture, the formulation of queries used in decoder has not been fully explored by previous methods. In this paper, we propose a concise dynamic point scene text detection Transformer network termed DPText-DETR, which directly uses point coordinates as queries and dynamically updates them between decoder layers. We point out a simple yet effective positional point label form to tackle the side effect of the original one. Moreover, an Enhanced Factorized Self-Attention module is designed to explicitly model the circular shape of polygon point sequences beyond non-local attention. Extensive experiments prove the training efficiency, robustness, and state-of-the-art performance on various arbitrary shape scene text benchmarks. Beyond detector, we observe that existing end-to-end spotters struggle to recognize inverse-like texts. To evaluate their performance objectively and facilitate future research, we propose an Inverse-Text test set containing 500 manually labeled images. The code and Inverse-Text test set will be available at https://github.com/ymy-k/DPText-DETR.