 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodiedBrain: Expanding Performance Boundaries of Task Planning for Embodied Intelligence
Oct 23, 2025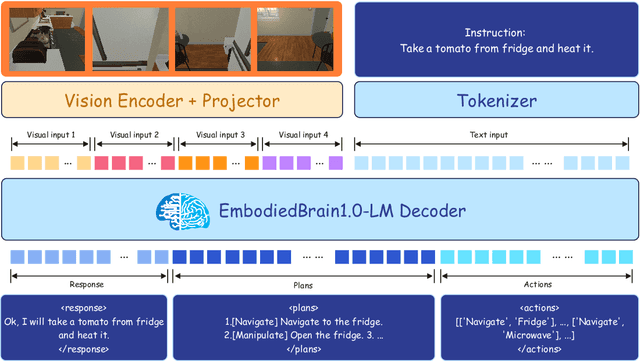
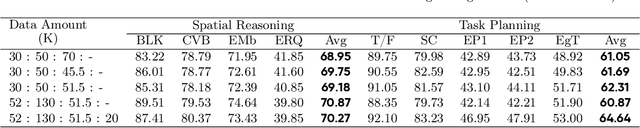

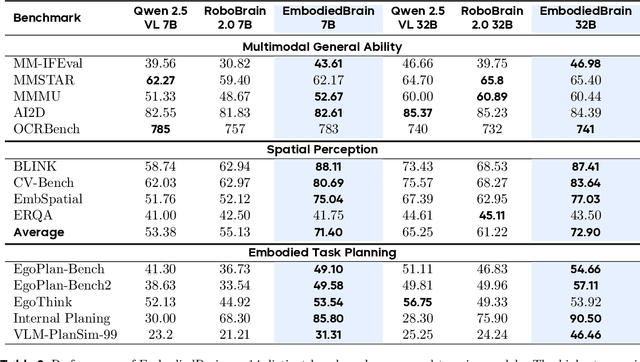
The realization of Artificial General Intelligence (AGI) necessitates Embodied AI agents capable of robust spatial perception, effective task planning, and adaptive execution in physical environments. However, current large language models (LLMs) and multimodal LLMs (MLLMs) for embodied tasks suffer from key limitations, including a significant gap between model design and agent requirements, an unavoidable trade-off between real-time latency and performance, and the use of unauthentic, offline evaluation metrics. To address these challenges, we propose EmbodiedBrain, a novel vision-language foundation model available in both 7B and 32B parameter sizes. Our framework features an agent-aligned data structure and employs a powerful training methodology that integrates large-scale Supervised Fine-Tuning (SFT) with Step-Augumented Group Relative Policy Optimization (Step-GRPO), which boosts long-horizon task success by integrating preceding steps as Guided Precursors. Furthermore, we incorporate a comprehensive reward system, including a Generative Reward Model (GRM) accelerated at the infrastructure level, to improve training efficiency. For enable thorough validation, we establish a three-part evaluation system encompassing General, Planning, and End-to-End Simulation Benchmarks, highlighted by the proposal and open-sourcing of a novel, challenging simulation environment. Experimental results demonstrate that EmbodiedBrain achieves superior performance across all metrics, establishing a new state-of-the-art for embodied foundation models. Towards paving the way for the next generation of generalist embodied agents, we open-source all of our data, model weight, and evaluating methods, which are available at https://zterobot.github.io/EmbodiedBrain.github.io.
3D Human Interaction Generation: A Survey
Mar 17, 20253D human interaction generation has emerged as a key research area, focusing on producing dynamic and contextually relevant interactions between humans and various interactive entities. Recent rapid advancements in 3D model representation methods, motion capture technologies, and generative models have laid a solid foundation for the growing interest in this domain. Existing research in this field can be broadly categorized into three areas: human-scene interaction, human-object interaction, and human-human interaction. Despite the rapid advancements in this area, challenges remain due to the need for naturalness in human motion generation and the accurate interaction between humans and interactive entities. In this survey, we present a comprehensive literature review of human interaction generation, which, to the best of our knowledge, is the first of its kind. We begin by introducing the foundational technologies, including model representations, motion capture methods, and generative models. Subsequently, we introduce the approaches proposed for the three sub-tasks, along with their corresponding datasets and evaluation metrics. Finally, we discuss potential future research directions in this area and conclude the survey. Through this survey, we aim to offer a comprehensive overview of the current advancements in the field, highlight key challenges, and inspire future research works.
TextIM: Part-aware Interactive Motion Synthesis from Text
Aug 06, 2024In this work, we propose TextIM, a novel framework for synthesizing TEXT-driven human Interactive Motions, with a focus on the precise alignment of part-level semantics. Existing methods often overlook the critical roles of interactive body parts and fail to adequately capture and align part-level semantics, resulting in inaccuracies and even erroneous movement outcomes. To address these issues, TextIM utilizes a decoupled conditional diffusion framework to enhance the detailed alignment between interactive movements and corresponding semantic intents from textual descriptions. Our approach leverages large language models, functioning as a human brain, to identify interacting human body parts and to comprehend interaction semantics to generate complicated and subtle interactive motion. Guided by the refined movements of the interacting parts, TextIM further extends these movements into a coherent whole-body motion. We design a spatial coherence module to complement the entire body movements while maintaining consistency and harmony across body parts using a part graph convolutional network. For training and evaluation, we carefully selected and re-labeled interactive motions from HUMANML3D to develop a specialized dataset. Experimental results demonstrate that TextIM produces semantically accurate human interactive motions, significantly enhancing the realism and applicability of synthesized interactive motions in diverse scenarios, even including interactions with deformable and dynamically changing objects.