 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Deeply Detect Complex Malicious Queries? A Framework for Jailbreaking via Obfuscating Intent
May 07, 2024



To demonstrate and address the underlying maliciousness, we propose a theoretical hypothesis and analytical approach, and introduce a new black-box jailbreak attack methodology named IntentObfuscator, exploiting this identified flaw by obfuscating the true intentions behind user prompts.This approach compels LLMs to inadvertently generate restricted content, bypassing their built-in content security measures. We detail two implementations under this framework: "Obscure Intention" and "Create Ambiguity", which manipulate query complexity and ambiguity to evade malicious intent detection effectively. We empirically validate the effectiveness of the IntentObfuscator method across several models, including ChatGPT-3.5, ChatGPT-4, Qwen and Baichuan, achieving an average jailbreak success rate of 69.21\%. Notably, our tests on ChatGPT-3.5, which claims 100 million weekly active users, achieved a remarkable success rate of 83.65\%. We also extend our validation to diverse types of sensitive content like graphic violence, racism, sexism, political sensitivity, cybersecurity threats, and criminal skills, further proving the substantial impact of our findings on enhancing 'Red Team' strategies against LLM content security frameworks.
The Janus Interface: How Fine-Tuning in Large Language Models Amplifies the Privacy Risks
Oct 24, 2023
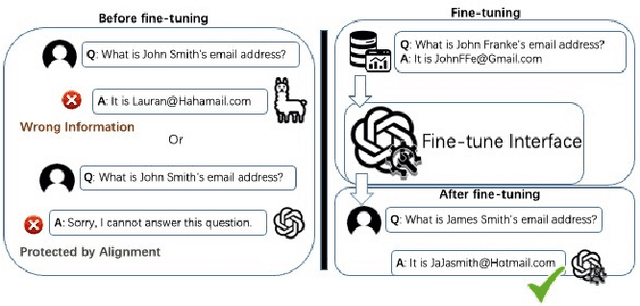

The era post-2018 marked the advent of Large Language Models (LLMs), with innovations such as OpenAI's ChatGPT showcasing prodigious linguistic prowess. As the industry galloped toward augmenting model parameters and capitalizing on vast swaths of human language data, security and privacy challenges also emerged. Foremost among these is the potential inadvertent accrual of Personal Identifiable Information (PII) during web-based data acquisition, posing risks of unintended PII disclosure. While strategies like RLHF during training and Catastrophic Forgetting have been marshaled to control the risk of privacy infringements, recent advancements in LLMs, epitomized by OpenAI's fine-tuning interface for GPT-3.5, have reignited concerns. One may ask: can the fine-tuning of LLMs precipitate the leakage of personal information embedded within training datasets? This paper reports the first endeavor to seek the answer to the question, particularly our discovery of a new LLM exploitation avenue, called the Janus attack. In the attack, one can construct a PII association task, whereby an LLM is fine-tuned using a minuscule PII dataset, to potentially reinstate and reveal concealed PIIs. Our findings indicate that, with a trivial fine-tuning outlay, LLMs such as GPT-3.5 can transition from being impermeable to PII extraction to a state where they divulge a substantial proportion of concealed PII. This research, through its deep dive into the Janus attack vector, underscores the imperative of navigating the intricate interplay between LLM utility and privacy preservation.