 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models in Medical Term Classification and Unexpected Misalignment Between Response and Reasoning
Dec 19, 2023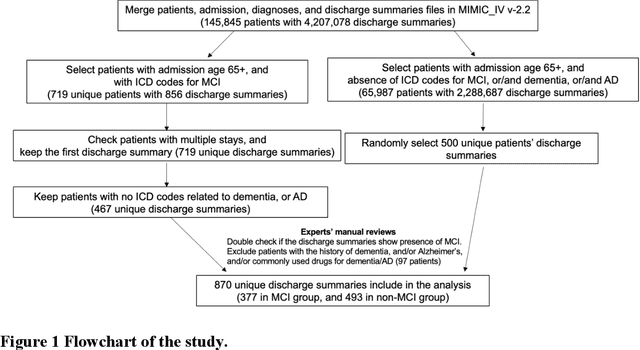
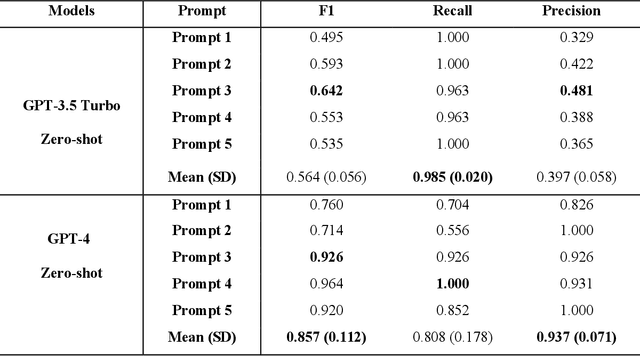

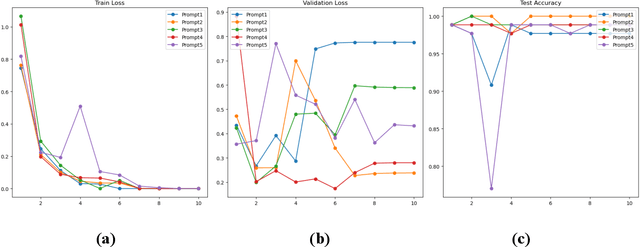
This study assesses the ability of state-of-the-art large language models (LLMs) including GPT-3.5, GPT-4, Falcon, and LLaMA 2 to identify patients with mild cognitive impairment (MCI) from discharge summaries and examines instances where the models' responses were misaligned with their reasoning. Utilizing the MIMIC-IV v2.2 database, we focused on a cohort aged 65 and older, verifying MCI diagnoses against ICD codes and expert evaluations. The data was partitioned into training, validation, and testing sets in a 7:2:1 ratio for model fine-tuning and evaluation, with an additional metastatic cancer dataset from MIMIC III used to further assess reasoning consistency. GPT-4 demonstrated superior interpretative capabilities, particularly in response to complex prompts, yet displayed notable response-reasoning inconsistencies. In contrast, open-source models like Falcon and LLaMA 2 achieved high accuracy but lacked explanatory reasoning, underscoring the necessity for further research to optimize both performance and interpretability. The study emphasizes the significance of prompt engineering and the need for further exploration into the unexpected reasoning-response misalignment observed in GPT-4. The results underscore the promise of incorporating LLMs into healthcare diagnostics, contingent upon methodological advancements to ensure accuracy and clinical coherence of AI-generated outputs, thereby improving the trustworthiness of LLMs for medical decision-making.