 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation or Recitation? Calibrating Evaluation Scores for Machine Translation of Extremely Low-Resource Languages
Mar 26, 2026The landscape of extremely low-resource machine translation (MT) is characterized by perplexing variability in reported performance, often making results across different language pairs difficult to contextualize. For researchers focused on specific language groups -- such as ancient languages -- it is nearly impossible to determine if breakthroughs reported in other contexts (e.g., native African or American languages) result from superior methodologies or are merely artifacts of benchmark collection. To address this problem, we introduce the FRED Difficulty Metrics, which include the Fertility Ratio (F), Retrieval Proxy (R), Pre-training Exposure (E), and Corpus Diversity (D) and serve as dataset-intrinsic metrics to contextualize reported scores. These metrics reveal that a significant portion of result variability is explained by train-test overlap and pre-training exposure rather than model capability. Additionally, we identify that some languages -- particularly extinct and non-Latin indigenous languages -- suffer from poor tokenization coverage (high token fertility), highlighting a fundamental limitation of transferring models from high-resource languages that lack a shared vocabulary. By providing these indices alongside performance scores, we enable more transparent evaluation of cross-lingual transfer and provide a more reliable foundation for the XLR MT community.
USO: Unified Style and Subject-Driven Generation via Disentangled and Reward Learning
Aug 26, 2025Existing literature typically treats style-driven and subject-driven generation as two disjoint tasks: the former prioritizes stylistic similarity, whereas the latter insists on subject consistency, resulting in an apparent antagonism. We argue that both objectives can be unified under a single framework because they ultimately concern the disentanglement and re-composition of content and style, a long-standing theme in style-driven research. To this end, we present USO, a Unified Style-Subject Optimized customization model. First, we construct a large-scale triplet dataset consisting of content images, style images, and their corresponding stylized content images. Second, we introduce a disentangled learning scheme that simultaneously aligns style features and disentangles content from style through two complementary objectives, style-alignment training and content-style disentanglement training. Third, we incorporate a style reward-learning paradigm denoted as SRL to further enhance the model's performance. Finally, we release USO-Bench, the first benchmark that jointly evaluates style similarity and subject fidelity across multiple metrics. Extensive experiments demonstrate that USO achieves state-of-the-art performance among open-source models along both dimensions of subject consistency and style similarity. Code and model: https://github.com/bytedance/USO
Align Beyond Prompts: Evaluating World Knowledge Alignment in Text-to-Image Generation
May 24, 2025Recent text-to-image (T2I) generation models have advanced significantly, enabling the creation of high-fidelity images from textual prompts. However, existing evaluation benchmarks primarily focus on the explicit alignment between generated images and prompts, neglecting the alignment with real-world knowledge beyond prompts. To address this gap, we introduce Align Beyond Prompts (ABP), a comprehensive benchmark designed to measure the alignment of generated images with real-world knowledge that extends beyond the explicit user prompts. ABP comprises over 2,000 meticulously crafted prompts, covering real-world knowledge across six distinct scenarios. We further introduce ABPScore, a metric that utilizes existing Multimodal Large Language Models (MLLMs) to assess the alignment between generated images and world knowledge beyond prompts, which demonstrates strong correlations with human judgments. Through a comprehensive evaluation of 8 popular T2I models using ABP, we find that even state-of-the-art models, such as GPT-4o, face limitations in integrating simple real-world knowledge into generated images. To mitigate this issue, we introduce a training-free strategy within ABP, named Inference-Time Knowledge Injection (ITKI). By applying this strategy to optimize 200 challenging samples, we achieved an improvement of approximately 43% in ABPScore. The dataset and code are available in https://github.com/smile365317/ABP.
Learning to Discover Forgery Cues for Face Forgery Detection
Sep 02, 2024



Locating manipulation maps, i.e., pixel-level annotation of forgery cues, is crucial for providing interpretable detection results in face forgery detection. Related learning objects have also been widely adopted as auxiliary tasks to improve the classification performance of detectors whereas they require comparisons between paired real and forged faces to obtain manipulation maps as supervision. This requirement restricts their applicability to unpaired faces and contradicts real-world scenarios. Moreover, the used comparison methods annotate all changed pixels, including noise introduced by compression and upsampling. Using such maps as supervision hinders the learning of exploitable cues and makes models prone to overfitting. To address these issues, we introduce a weakly supervised model in this paper, named Forgery Cue Discovery (FoCus), to locate forgery cues in unpaired faces. Unlike some detectors that claim to locate forged regions in attention maps, FoCus is designed to sidestep their shortcomings of capturing partial and inaccurate forgery cues. Specifically, we propose a classification attentive regions proposal module to locate forgery cues during classification and a complementary learning module to facilitate the learning of richer cues. The produced manipulation maps can serve as better supervision to enhance face forgery detectors. Visualization of the manipulation maps of the proposed FoCus exhibits superior interpretability and robustness compared to existing methods. Experiments on five datasets and four multi-task models demonstrate the effectiveness of FoCus in both in-dataset and cross-dataset evaluations.
Explicit Correlation Learning for Generalizable Cross-Modal Deepfake Detection
Apr 30, 2024



With the rising prevalence of deepfakes, there is a growing interest in developing generalizable detection methods for various types of deepfakes. While effective in their specific modalities, traditional detection methods fall short in addressing the generalizability of detection across diverse cross-modal deepfakes. This paper aims to explicitly learn potential cross-modal correlation to enhance deepfake detection towards various generation scenarios. Our approach introduces a correlation distillation task, which models the inherent cross-modal correlation based on content information. This strategy helps to prevent the model from overfitting merely to audio-visual synchronization. Additionally, we present the Cross-Modal Deepfake Dataset (CMDFD), a comprehensive dataset with four generation methods to evaluate the detection of diverse cross-modal deepfakes. The experimental results on CMDFD and FakeAVCeleb datasets demonstrate the superior generalizability of our method over existing state-of-the-art methods. Our code and data can be found at \url{https://github.com/ljj898/CMDFD-Dataset-and-Deepfake-Detection}.
Modality-Agnostic Audio-Visual Deepfake Detection
Jul 26, 2023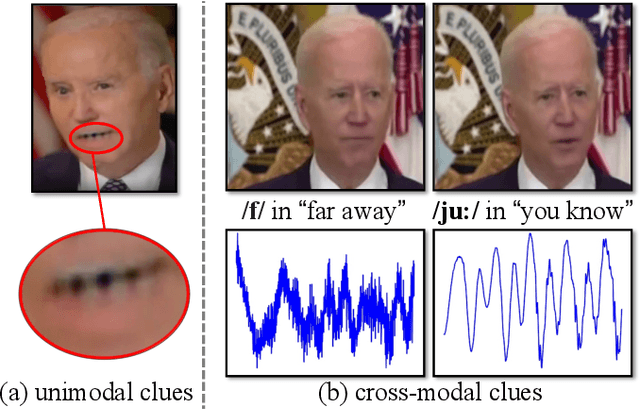
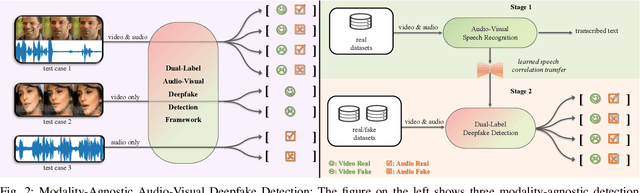
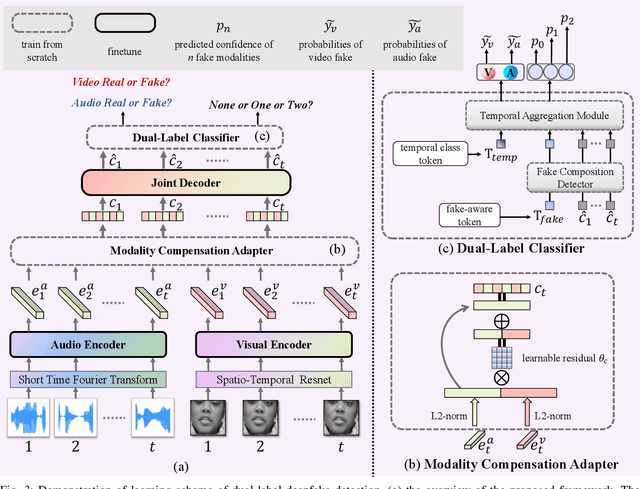
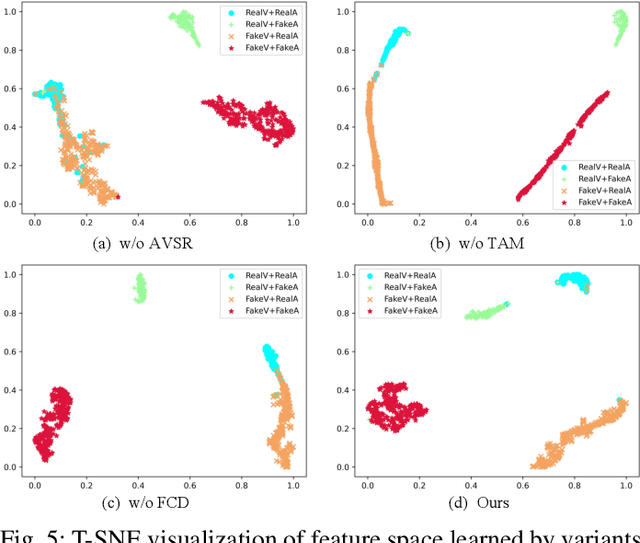
As AI-generated content (AIGC) thrives, Deepfakes have expanded from single-modality falsification to cross-modal fake content creation, where either audio or visual components can be manipulated. While using two unimodal detectors can detect audio-visual deepfakes, cross-modal forgery clues could be overlooked. Existing multimodal deepfake detection methods typically establish correspondence between the audio and visual modalities for binary real/fake classification, and require the co-occurrence of both modalities. However, in real-world multi-modal applications, missing modality scenarios may occur where either modality is unavailable. In such cases, audio-visual detection methods are less practical than two independent unimodal methods. Consequently, the detector can not always obtain the number or type of manipulated modalities beforehand, necessitating a fake-modality-agnostic audio-visual detector. In this work, we propose a unified fake-modality-agnostic scenarios framework that enables the detection of multimodal deepfakes and handles missing modalities cases, no matter the manipulation hidden in audio, video, or even cross-modal forms. To enhance the modeling of cross-modal forgery clues, we choose audio-visual speech recognition (AVSR) as a preceding task, which effectively extracts speech correlation across modalities, which is difficult for deepfakes to reproduce. Additionally, we propose a dual-label detection approach that follows the structure of AVSR to support the independent detection of each modality. Extensive experiments show that our scheme not only outperforms other state-of-the-art binary detection methods across all three audio-visual datasets but also achieves satisfying performance on detection modality-agnostic audio/video fakes. Moreover, it even surpasses the joint use of two unimodal methods in the presence of missing modality cases.