 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-Agnostic Audio-Visual Deepfake Detection
Paper and Code
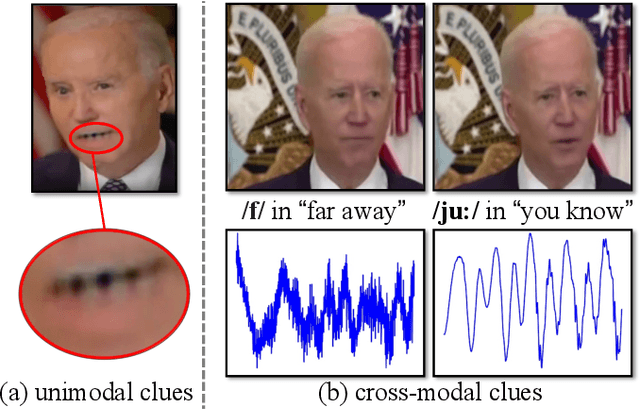
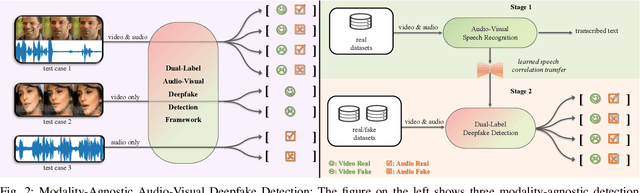
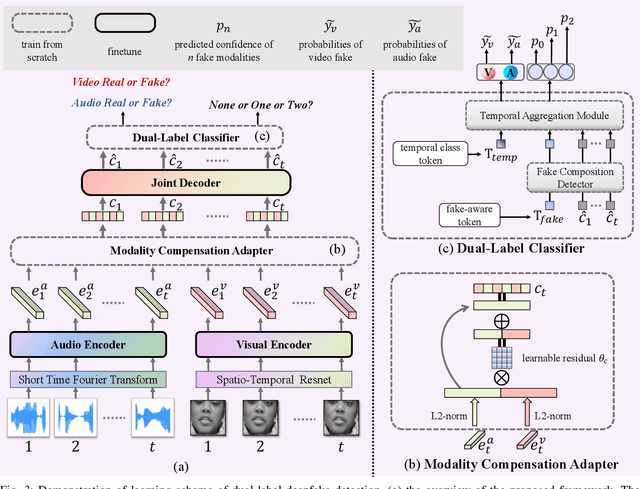
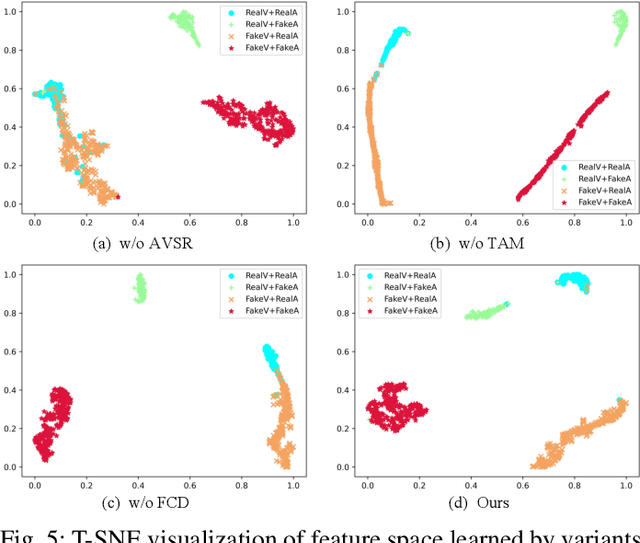
As AI-generated content (AIGC) thrives, Deepfakes have expanded from single-modality falsification to cross-modal fake content creation, where either audio or visual components can be manipulated. While using two unimodal detectors can detect audio-visual deepfakes, cross-modal forgery clues could be overlooked. Existing multimodal deepfake detection methods typically establish correspondence between the audio and visual modalities for binary real/fake classification, and require the co-occurrence of both modalities. However, in real-world multi-modal applications, missing modality scenarios may occur where either modality is unavailable. In such cases, audio-visual detection methods are less practical than two independent unimodal methods. Consequently, the detector can not always obtain the number or type of manipulated modalities beforehand, necessitating a fake-modality-agnostic audio-visual detector. In this work, we propose a unified fake-modality-agnostic scenarios framework that enables the detection of multimodal deepfakes and handles missing modalities cases, no matter the manipulation hidden in audio, video, or even cross-modal forms. To enhance the modeling of cross-modal forgery clues, we choose audio-visual speech recognition (AVSR) as a preceding task, which effectively extracts speech correlation across modalities, which is difficult for deepfakes to reproduce. Additionally, we propose a dual-label detection approach that follows the structure of AVSR to support the independent detection of each modality. Extensive experiments show that our scheme not only outperforms other state-of-the-art binary detection methods across all three audio-visual datasets but also achieves satisfying performance on detection modality-agnostic audio/video fakes. Moreover, it even surpasses the joint use of two unimodal methods in the presence of missing modality cases.