 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
Parameter-Inverted Image Pyramid Networks for Visual Perception and Multimodal Understanding
Jan 14, 2025Image pyramids are widely adopted in top-performing methods to obtain multi-scale features for precise visual perception and understanding. However, current image pyramids use the same large-scale model to process multiple resolutions of images, leading to significant computational cost. To address this challenge, we propose a novel network architecture, called Parameter-Inverted Image Pyramid Networks (PIIP). Specifically, PIIP uses pretrained models (ViTs or CNNs) as branches to process multi-scale images, where images of higher resolutions are processed by smaller network branches to balance computational cost and performance. To integrate information from different spatial scales, we further propose a novel cross-branch feature interaction mechanism. To validate PIIP, we apply it to various perception models and a representative multimodal large language model called LLaVA, and conduct extensive experiments on various tasks such as object detection, segmentation, image classification and multimodal understanding. PIIP achieves superior performance compared to single-branch and existing multi-resolution approaches with lower computational cost. When applied to InternViT-6B, a large-scale vision foundation model, PIIP can improve its performance by 1%-2% on detection and segmentation with only 40%-60% of the original computation, finally achieving 60.0 box AP on MS COCO and 59.7 mIoU on ADE20K. For multimodal understanding, our PIIP-LLaVA achieves 73.0% accuracy on TextVQA and 74.5% on MMBench with only 2.8M training data. Our code is released at https://github.com/OpenGVLab/PIIP.
SynerGen-VL: Towards Synergistic Image Understanding and Generation with Vision Experts and Token Folding
Dec 12, 2024



The remarkable success of Large Language Models (LLMs) has extended to the multimodal domain, achieving outstanding performance in image understanding and generation. Recent efforts to develop unified Multimodal Large Language Models (MLLMs) that integrate these capabilities have shown promising results. However, existing approaches often involve complex designs in model architecture or training pipeline, increasing the difficulty of model training and scaling. In this paper, we propose SynerGen-VL, a simple yet powerful encoder-free MLLM capable of both image understanding and generation. To address challenges identified in existing encoder-free unified MLLMs, we introduce the token folding mechanism and the vision-expert-based progressive alignment pretraining strategy, which effectively support high-resolution image understanding while reducing training complexity. After being trained on large-scale mixed image-text data with a unified next-token prediction objective, SynerGen-VL achieves or surpasses the performance of existing encoder-free unified MLLMs with comparable or smaller parameter sizes, and narrows the gap with task-specific state-of-the-art models, highlighting a promising path toward future unified MLLMs. Our code and models shall be released.
Mono-InternVL: Pushing the Boundaries of Monolithic Multimodal Large Language Models with Endogenous Visual Pre-training
Oct 10, 2024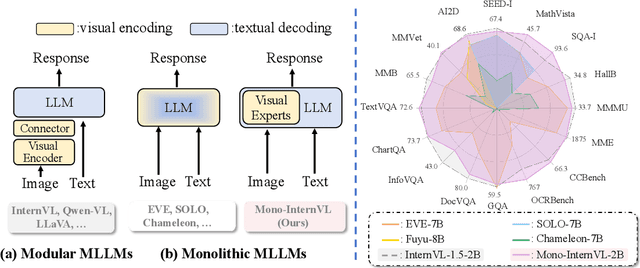
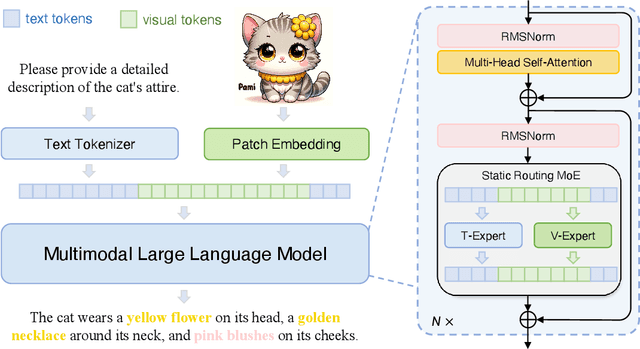
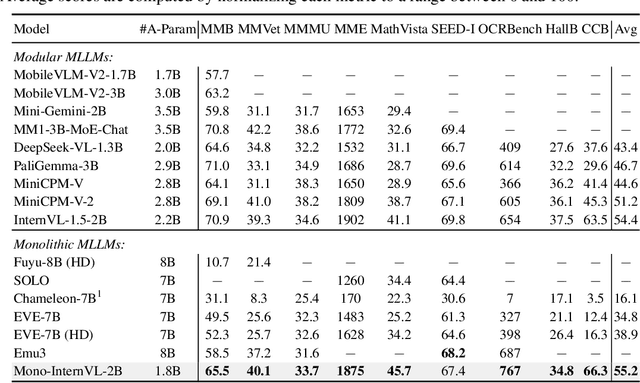
The rapid advancement of Large Language Models (LLMs) has led to an influx of efforts to extend their capabilities to multimodal tasks. Among them, growing attention has been focused on monolithic Multimodal Large Language Models (MLLMs) that integrate visual encoding and language decoding into a single LLM. Despite the structural simplicity and deployment-friendliness, training a monolithic MLLM with promising performance still remains challenging. In particular, the popular approaches adopt continuous pre-training to extend a pre-trained LLM to a monolithic MLLM, which suffers from catastrophic forgetting and leads to performance degeneration. In this paper, we aim to overcome this limitation from the perspective of delta tuning. Specifically, our core idea is to embed visual parameters into a pre-trained LLM, thereby incrementally learning visual knowledge from massive data via delta tuning, i.e., freezing the LLM when optimizing the visual parameters. Based on this principle, we present Mono-InternVL, a novel monolithic MLLM that seamlessly integrates a set of visual experts via a multimodal mixture-of-experts structure. Moreover, we propose an innovative pre-training strategy to maximize the visual capability of Mono-InternVL, namely Endogenous Visual Pre-training (EViP). In particular, EViP is designed as a progressive learning process for visual experts, which aims to fully exploit the visual knowledge from noisy data to high-quality data. To validate our approach, we conduct extensive experiments on 16 benchmarks. Experimental results not only validate the superior performance of Mono-InternVL compared to the state-of-the-art MLLM on 6 multimodal benchmarks, e.g., +113 points over InternVL-1.5 on OCRBench, but also confirm its better deployment efficiency, with first token latency reduced by up to 67%.
Parameter-Inverted Image Pyramid Networks
Jun 06, 2024



Image pyramids are commonly used in modern computer vision tasks to obtain multi-scale features for precise understanding of images. However, image pyramids process multiple resolutions of images using the same large-scale model, which requires significant computational cost. To overcome this issue, we propose a novel network architecture known as the Parameter-Inverted Image Pyramid Networks (PIIP). Our core idea is to use models with different parameter sizes to process different resolution levels of the image pyramid, thereby balancing computational efficiency and performance. Specifically, the input to PIIP is a set of multi-scale images, where higher resolution images are processed by smaller networks. We further propose a feature interaction mechanism to allow features of different resolutions to complement each other and effectively integrate information from different spatial scales. Extensive experiments demonstrate that the PIIP achieves superior performance in tasks such as object detection, segmentation, and image classification, compared to traditional image pyramid methods and single-branch networks, while reducing computational cost. Notably, when applying our method on a large-scale vision foundation model InternViT-6B, we improve its performance by 1%-2% on detection and segmentation with only 40%-60% of the original computation. These results validate the effectiveness of the PIIP approach and provide a new technical direction for future vision computing tasks. Our code and models are available at https://github.com/OpenGVLab/PIIP.