 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurveillance Video Parsing with Single Frame Supervision
Nov 29, 2016

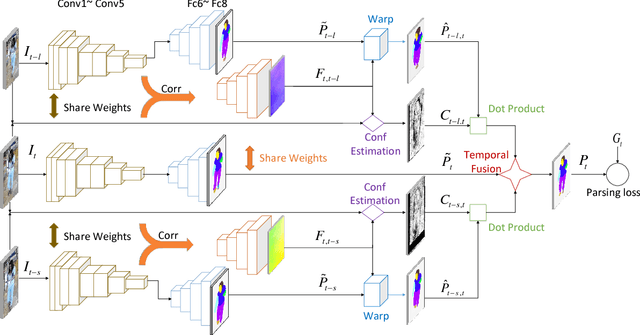

Surveillance video parsing, which segments the video frames into several labels, e.g., face, pants, left-leg, has wide applications. However,pixel-wisely annotating all frames is tedious and inefficient. In this paper, we develop a Single frame Video Parsing (SVP) method which requires only one labeled frame per video in training stage. To parse one particular frame, the video segment preceding the frame is jointly considered. SVP (1) roughly parses the frames within the video segment, (2) estimates the optical flow between frames and (3) fuses the rough parsing results warped by optical flow to produce the refined parsing result. The three components of SVP, namely frame parsing, optical flow estimation and temporal fusion are integrated in an end-to-end manner. Experimental results on two surveillance video datasets show the superiority of SVP over state-of-the-arts.
Makeup like a superstar: Deep Localized Makeup Transfer Network
Apr 25, 2016



In this paper, we propose a novel Deep Localized Makeup Transfer Network to automatically recommend the most suitable makeup for a female and synthesis the makeup on her face. Given a before-makeup face, her most suitable makeup is determined automatically. Then, both the beforemakeup and the reference faces are fed into the proposed Deep Transfer Network to generate the after-makeup face. Our end-to-end makeup transfer network have several nice properties including: (1) with complete functions: including foundation, lip gloss, and eye shadow transfer; (2) cosmetic specific: different cosmetics are transferred in different manners; (3) localized: different cosmetics are applied on different facial regions; (4) producing naturally looking results without obvious artifacts; (5) controllable makeup lightness: various results from light makeup to heavy makeup can be generated. Qualitative and quantitative experiments show that our network performs much better than the methods of [Guo and Sim, 2009] and two variants of NerualStyle [Gatys et al., 2015a].