 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-domain Human Parsing via Adversarial Feature and Label Adaptation
Paper and Code
Jan 08, 2018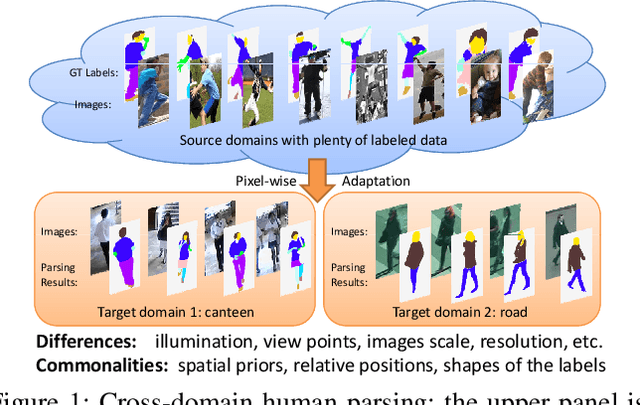
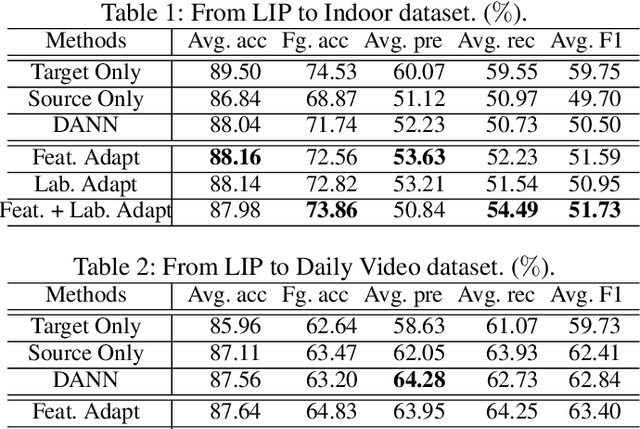


Human parsing has been extensively studied recently due to its wide applications in many important scenarios. Mainstream fashion parsing models focus on parsing the high-resolution and clean images. However, directly applying the parsers trained on benchmarks to a particular application scenario in the wild, e.g., a canteen, airport or workplace, often gives non-satisfactory performance due to domain shift. In this paper, we explore a new and challenging cross-domain human parsing problem: taking the benchmark dataset with extensive pixel-wise labeling as the source domain, how to obtain a satisfactory parser on a new target domain without requiring any additional manual labeling? To this end, we propose a novel and efficient cross-domain human parsing model to bridge the cross-domain differences in terms of visual appearance and environment conditions and fully exploit commonalities across domains. Our proposed model explicitly learns a feature compensation network, which is specialized for mitigating the cross-domain differences. A discriminative feature adversarial network is introduced to supervise the feature compensation to effectively reduce the discrepancy between feature distributions of two domains. Besides, our model also introduces a structured label adversarial network to guide the parsing results of the target domain to follow the high-order relationships of the structured labels shared across domains. The proposed framework is end-to-end trainable, practical and scalable in real applications. Extensive experiments are conducted where LIP dataset is the source domain and 4 different datasets including surveillance videos, movies and runway shows are evaluated as target domains. The results consistently confirm data efficiency and performance advantages of the proposed method for the cross-domain human parsing problem.