 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatic Program Analysis Guided LLM Based Unit Test Generation
Mar 07, 2025



We describe a novel approach to automating unit test generation for Java methods using large language models (LLMs). Existing LLM-based approaches rely on sample usage(s) of the method to test (focal method) and/or provide the entire class of the focal method as input prompt and context. The former approach is often not viable due to the lack of sample usages, especially for newly written focal methods. The latter approach does not scale well enough; the bigger the complexity of the focal method and larger associated class, the harder it is to produce adequate test code (due to factors such as exceeding the prompt and context lengths of the underlying LLM). We show that augmenting prompts with \emph{concise} and \emph{precise} context information obtained by program analysis %of the focal method increases the effectiveness of generating unit test code through LLMs. We validate our approach on a large commercial Java project and a popular open-source Java project.
Icing on the Cake: Automatic Code Summarization at Ericsson
Aug 19, 2024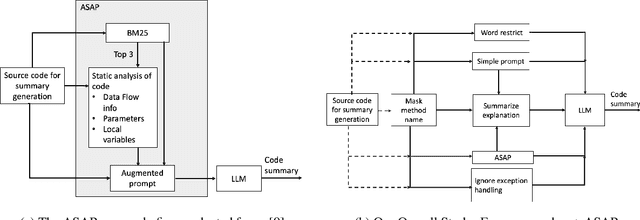
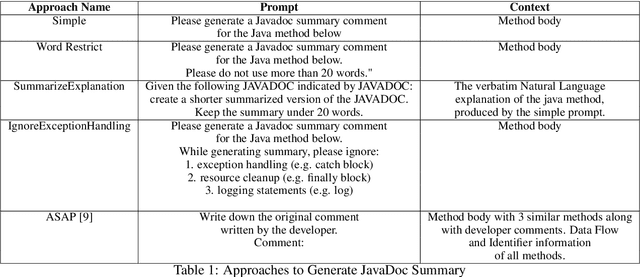
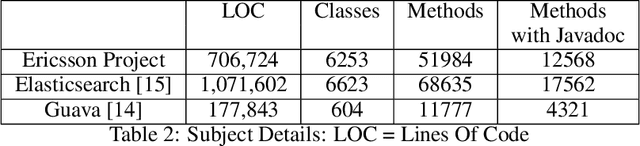
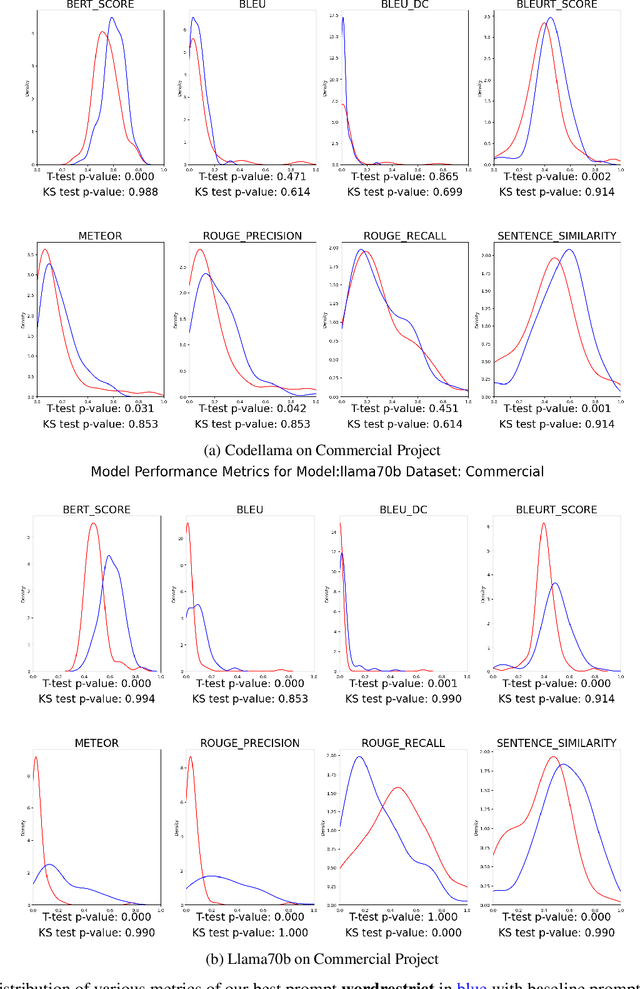
This paper presents our findings on the automatic summarization of Java methods within Ericsson, a global telecommunications company. We evaluate the performance of an approach called Automatic Semantic Augmentation of Prompts (ASAP), which uses a Large Language Model (LLM) to generate leading summary comments for Java methods. ASAP enhances the $LLM's$ prompt context by integrating static program analysis and information retrieval techniques to identify similar exemplar methods along with their developer-written Javadocs, and serves as the baseline in our study. In contrast, we explore and compare the performance of four simpler approaches that do not require static program analysis, information retrieval, or the presence of exemplars as in the ASAP method. Our methods rely solely on the Java method body as input, making them lightweight and more suitable for rapid deployment in commercial software development environments. We conducted experiments on an Ericsson software project and replicated the study using two widely-used open-source Java projects, Guava and Elasticsearch, to ensure the reliability of our results. Performance was measured across eight metrics that capture various aspects of similarity. Notably, one of our simpler approaches performed as well as or better than the ASAP method on both the Ericsson project and the open-source projects. Additionally, we performed an ablation study to examine the impact of method names on Javadoc summary generation across our four proposed approaches and the ASAP method. By masking the method names and observing the generated summaries, we found that our approaches were statistically significantly less influenced by the absence of method names compared to the baseline. This suggests that our methods are more robust to variations in method names and may derive summaries more comprehensively from the method body than the ASAP approach.
ChatGPT: A Study on its Utility for Ubiquitous Software Engineering Tasks
May 26, 2023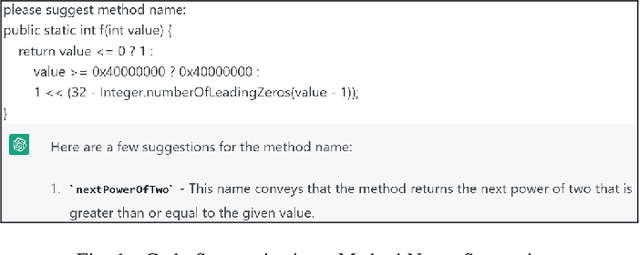
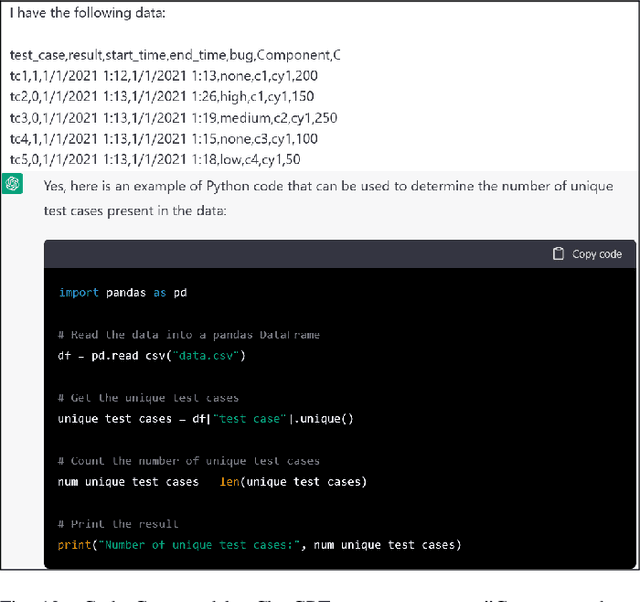


ChatGPT (Chat Generative Pre-trained Transformer) is a chatbot launched by OpenAI on November 30, 2022. OpenAI's GPT-3 family of large language models serve as the foundation for ChatGPT. ChatGPT is fine-tuned with both supervised and reinforcement learning techniques and has received widespread attention for its articulate responses across diverse domains of knowledge. In this study, we explore how ChatGPT can be used to help with common software engineering tasks. Many of the ubiquitous tasks covering the breadth of software engineering such as ambiguity resolution in software requirements, method name suggestion, test case prioritization, code review, log summarization can potentially be performed using ChatGPT. In this study, we explore fifteen common software engineering tasks using ChatGPT. We juxtapose and analyze ChatGPT's answers with the respective state of the art outputs (where available) and/or human expert ground truth. Our experiments suggest that for many tasks, ChatGPT does perform credibly and the response from it is detailed and often better than the human expert output or the state of the art output. However, for a few other tasks, ChatGPT in its present form provides incorrect answers and hence is not suited for such tasks.
Improving IT Support by Enhancing Incident Management Process with Multi-modal Analysis
Aug 04, 2019
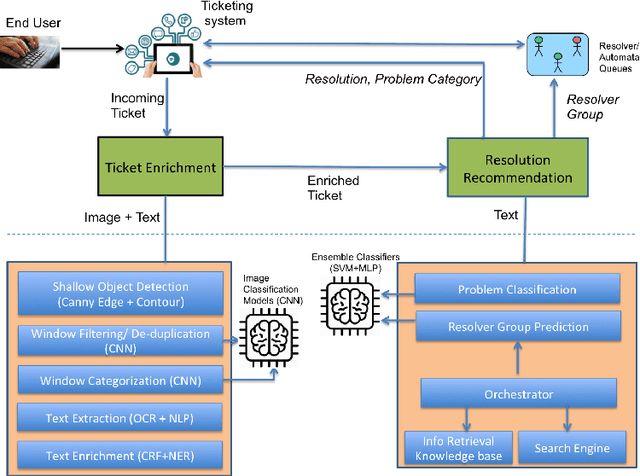
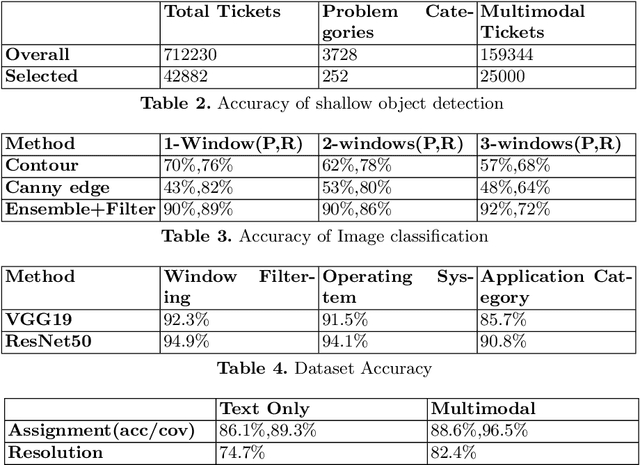
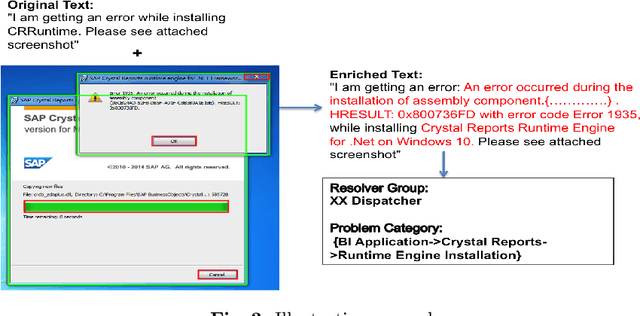
IT support services industry is going through a major transformation with AI becoming commonplace. There has been a lot of effort in the direction of automation at every human touchpoint in the IT support processes. Incident management is one such process which has been a beacon process for AI based automation. The vision is to automate the process from the time an incident/ticket arrives till it is resolved and closed. While text is the primary mode of communicating the incidents, there has been a growing trend of using alternate modalities like image to communicate the problem. A large fraction of IT support tickets today contain attached image data in the form of screenshots, log messages, invoices and so on. These attachments help in better explanation of the problem which aids in faster resolution. Anybody who aspires to provide AI based IT support, it is essential to build systems which can handle multi-modal content. In this paper we present how incident management in IT support domain can be made much more effective using multi-modal analysis. The information extracted from different modalities are correlated to enrich the information in the ticket and used for better ticket routing and resolution. We evaluate our system using about 25000 real tickets containing attachments from selected problem areas. Our results demonstrate significant improvements in both routing and resolution with the use of multi-modal ticket analysis compared to only text based analysis.
Fault in your stars: An Analysis of Android App Reviews
Aug 11, 2018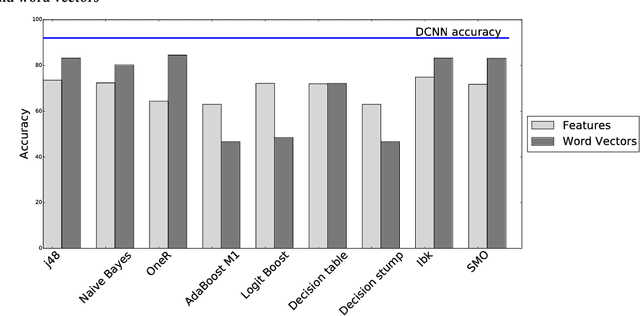
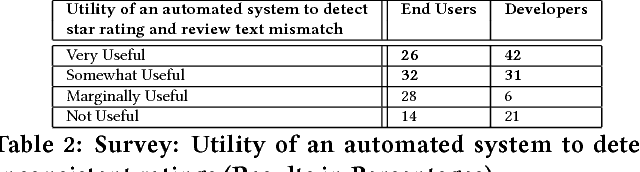
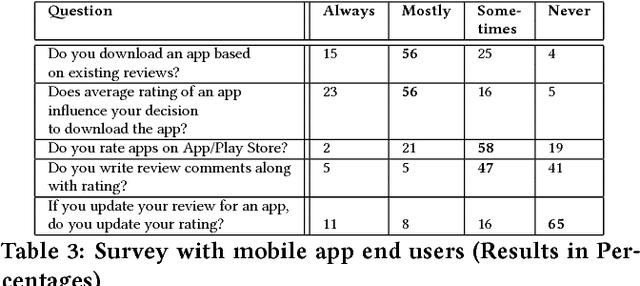
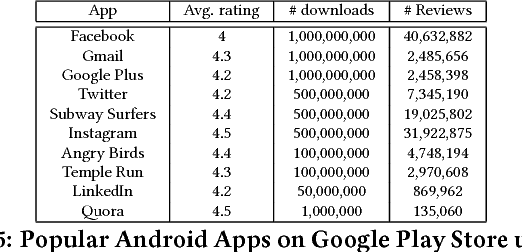
Mobile app distribution platforms such as Google Play Store allow users to share their feedback about downloaded apps in the form of a review comment and a corresponding star rating. Typically, the star rating ranges from one to five stars, with one star denoting a high sense of dissatisfaction with the app and five stars denoting a high sense of satisfaction. Unfortunately, due to a variety of reasons, often the star rating provided by a user is inconsistent with the opinion expressed in the review. For example, consider the following review for the Facebook App on Android; "Awesome App". One would reasonably expect the rating for this review to be five stars, but the actual rating is one star! Such inconsistent ratings can lead to a deflated (or inflated) overall average rating of an app which can affect user downloads, as typically users look at the average star ratings while making a decision on downloading an app. Also, the app developers receive a biased feedback about the application that does not represent ground reality. This is especially significant for small apps with a few thousand downloads as even a small number of mismatched reviews can bring down the average rating drastically. In this paper, we conducted a study on this review-rating mismatch problem. We manually examined 8600 reviews from 10 popular Android apps and found that 20% of the ratings in our dataset were inconsistent with the review. Further, we developed three systems; two of which were based on traditional machine learning and one on deep learning to automatically identify reviews whose rating did not match with the opinion expressed in the review. Our deep learning system performed the best and had an accuracy of 92% in identifying the correct star rating to be associated with a given review.
Cognitive system to achieve human-level accuracy in automated assignment of helpdesk email tickets
Aug 09, 2018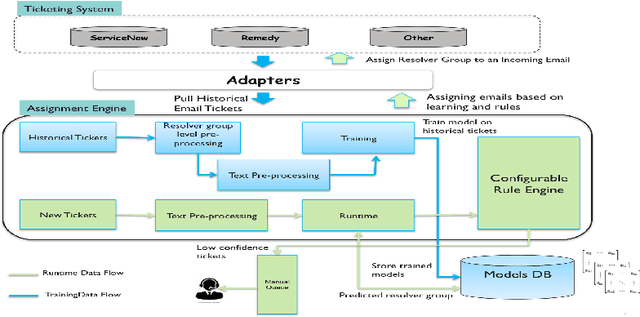
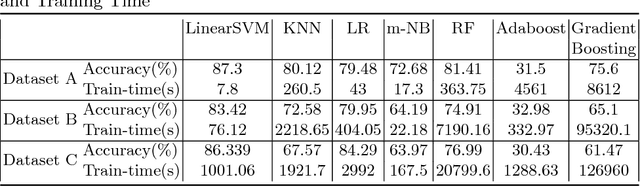
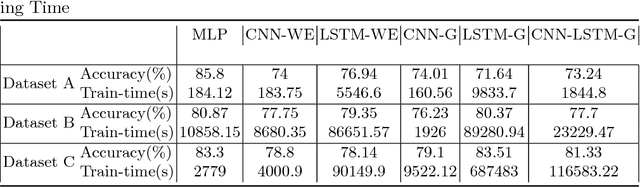
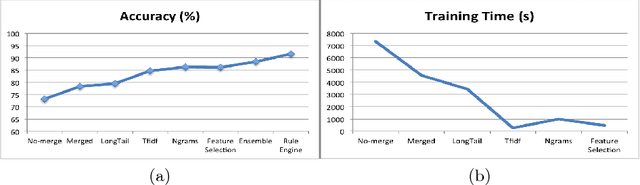
Ticket assignment/dispatch is a crucial part of service delivery business with lot of scope for automation and optimization. In this paper, we present an end-to-end automated helpdesk email ticket assignment system, which is also offered as a service. The objective of the system is to determine the nature of the problem mentioned in an incoming email ticket and then automatically dispatch it to an appropriate resolver group (or team) for resolution. The proposed system uses an ensemble classifier augmented with a configurable rule engine. While design of classifier that is accurate is one of the main challenges, we also need to address the need of designing a system that is robust and adaptive to changing business needs. We discuss some of the main design challenges associated with email ticket assignment automation and how we solve them. The design decisions for our system are driven by high accuracy, coverage, business continuity, scalability and optimal usage of computational resources. Our system has been deployed in production of three major service providers and currently assigning over 40,000 emails per month, on an average, with an accuracy close to 90% and covering at least 90% of email tickets. This translates to achieving human-level accuracy and results in a net saving of about 23000 man-hours of effort per annum.