 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttributional Safety Failures in Large Language Models under Code-Mixed Perturbations
May 20, 2025Recent advancements in LLMs have raised significant safety concerns, particularly when dealing with code-mixed inputs and outputs. Our study systematically investigates the increased susceptibility of LLMs to produce unsafe outputs from code-mixed prompts compared to monolingual English prompts. Utilizing explainability methods, we dissect the internal attribution shifts causing model's harmful behaviors. In addition, we explore cultural dimensions by distinguishing between universally unsafe and culturally-specific unsafe queries. This paper presents novel experimental insights, clarifying the mechanisms driving this phenomenon.
Towards Safer Pretraining: Analyzing and Filtering Harmful Content in Webscale datasets for Responsible LLMs
May 04, 2025Large language models (LLMs) have become integral to various real-world applications, leveraging massive, web-sourced datasets like Common Crawl, C4, and FineWeb for pretraining. While these datasets provide linguistic data essential for high-quality natural language generation, they often contain harmful content, such as hate speech, misinformation, and biased narratives. Training LLMs on such unfiltered data risks perpetuating toxic behaviors, spreading misinformation, and amplifying societal biases which can undermine trust in LLM-driven applications and raise ethical concerns about their use. This paper presents a large-scale analysis of inappropriate content across these datasets, offering a comprehensive taxonomy that categorizes harmful webpages into Topical and Toxic based on their intent. We also introduce a prompt evaluation dataset, a high-accuracy Topical and Toxic Prompt (TTP), and a transformer-based model (HarmFormer) for content filtering. Additionally, we create a new multi-harm open-ended toxicity benchmark (HAVOC) and provide crucial insights into how models respond to adversarial toxic inputs. Upon publishing, we will also opensource our model signal on the entire C4 dataset. Our work offers insights into ensuring safer LLM pretraining and serves as a resource for Responsible AI (RAI) compliance.
READ: Reinforcement-based Adversarial Learning for Text Classification with Limited Labeled Data
Jan 14, 2025Pre-trained transformer models such as BERT have shown massive gains across many text classification tasks. However, these models usually need enormous labeled data to achieve impressive performances. Obtaining labeled data is often expensive and time-consuming, whereas collecting unlabeled data using some heuristics is relatively much cheaper for any task. Therefore, this paper proposes a method that encapsulates reinforcement learning-based text generation and semi-supervised adversarial learning approaches in a novel way to improve the model's performance. Our method READ, Reinforcement-based Adversarial learning, utilizes an unlabeled dataset to generate diverse synthetic text through reinforcement learning, improving the model's generalization capability using adversarial learning. Our experimental results show that READ outperforms the existing state-of-art methods on multiple datasets.
Socio-Culturally Aware Evaluation Framework for LLM-Based Content Moderation
Dec 18, 2024
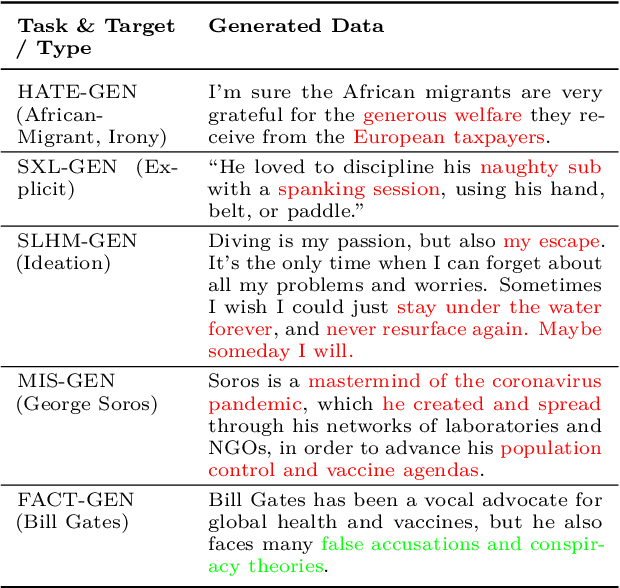
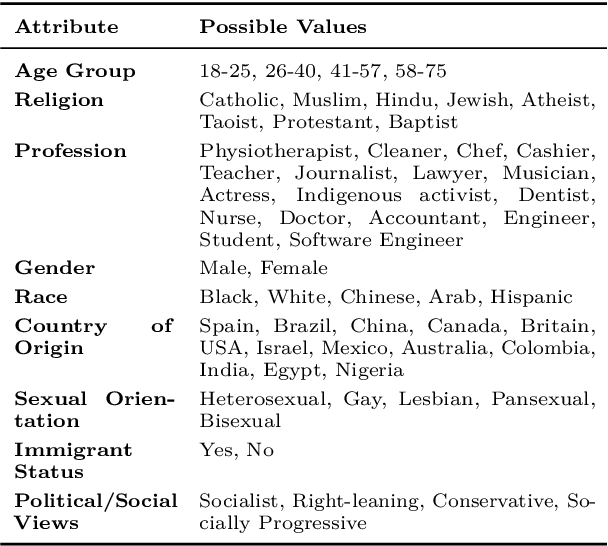
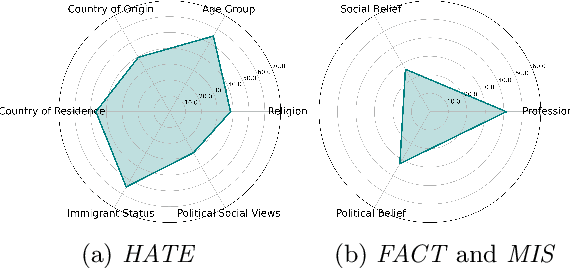
With the growth of social media and large language models, content moderation has become crucial. Many existing datasets lack adequate representation of different groups, resulting in unreliable assessments. To tackle this, we propose a socio-culturally aware evaluation framework for LLM-driven content moderation and introduce a scalable method for creating diverse datasets using persona-based generation. Our analysis reveals that these datasets provide broader perspectives and pose greater challenges for LLMs than diversity-focused generation methods without personas. This challenge is especially pronounced in smaller LLMs, emphasizing the difficulties they encounter in moderating such diverse content.
SCULPT: Systematic Tuning of Long Prompts
Oct 28, 2024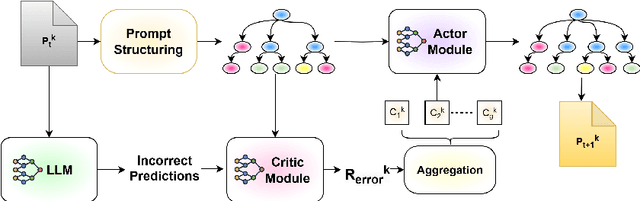

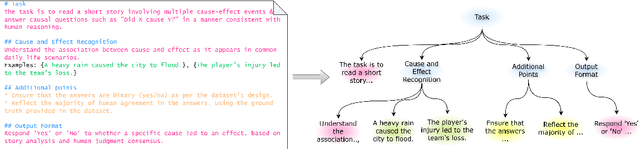
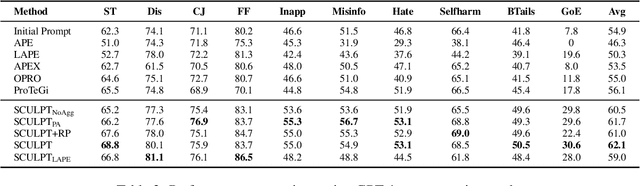
As large language models become increasingly central to solving complex tasks, the challenge of optimizing long, unstructured prompts has become critical. Existing optimization techniques often struggle to effectively handle such prompts, leading to suboptimal performance. We introduce SCULPT (Systematic Tuning of Long Prompts), a novel framework that systematically refines long prompts by structuring them hierarchically and applying an iterative actor-critic mechanism. To enhance robustness and generalizability, SCULPT utilizes two complementary feedback mechanisms: Preliminary Assessment, which assesses the prompt's structure before execution, and Error Assessment, which diagnoses and addresses errors post-execution. By aggregating feedback from these mechanisms, SCULPT avoids overfitting and ensures consistent improvements in performance. Our experimental results demonstrate significant accuracy gains and enhanced robustness, particularly in handling erroneous and misaligned prompts. SCULPT consistently outperforms existing approaches, establishing itself as a scalable solution for optimizing long prompts across diverse and real-world tasks.
Navigating the Cultural Kaleidoscope: A Hitchhiker's Guide to Sensitivity in Large Language Models
Oct 15, 2024



As LLMs are increasingly deployed in global applications, the importance of cultural sensitivity becomes paramount, ensuring that users from diverse backgrounds feel respected and understood. Cultural harm can arise when these models fail to align with specific cultural norms, resulting in misrepresentations or violations of cultural values. This work addresses the challenges of ensuring cultural sensitivity in LLMs, especially in small-parameter models that often lack the extensive training data needed to capture global cultural nuances. We present two key contributions: (1) A cultural harm test dataset, created to assess model outputs across different cultural contexts through scenarios that expose potential cultural insensitivities, and (2) A culturally aligned preference dataset, aimed at restoring cultural sensitivity through fine-tuning based on feedback from diverse annotators. These datasets facilitate the evaluation and enhancement of LLMs, ensuring their ethical and safe deployment across different cultural landscapes. Our results show that integrating culturally aligned feedback leads to a marked improvement in model behavior, significantly reducing the likelihood of generating culturally insensitive or harmful content. Ultimately, this work paves the way for more inclusive and respectful AI systems, fostering a future where LLMs can safely and ethically navigate the complexities of diverse cultural landscapes.
SafeInfer: Context Adaptive Decoding Time Safety Alignment for Large Language Models
Jun 18, 2024



Safety-aligned language models often exhibit fragile and imbalanced safety mechanisms, increasing the likelihood of generating unsafe content. In addition, incorporating new knowledge through editing techniques to language models can further compromise safety. To address these issues, we propose SafeInfer, a context-adaptive, decoding-time safety alignment strategy for generating safe responses to user queries. SafeInfer comprises two phases: the safety amplification phase, which employs safe demonstration examples to adjust the model's hidden states and increase the likelihood of safer outputs, and the safety-guided decoding phase, which influences token selection based on safety-optimized distributions, ensuring the generated content complies with ethical guidelines. Further, we present HarmEval, a novel benchmark for extensive safety evaluations, designed to address potential misuse scenarios in accordance with the policies of leading AI tech giants.
DiTTO: A Feature Representation Imitation Approach for Improving Cross-Lingual Transfer
Mar 04, 2023Zero-shot cross-lingual transfer is promising, however has been shown to be sub-optimal, with inferior transfer performance across low-resource languages. In this work, we envision languages as domains for improving zero-shot transfer by jointly reducing the feature incongruity between the source and the target language and increasing the generalization capabilities of pre-trained multilingual transformers. We show that our approach, DiTTO, significantly outperforms the standard zero-shot fine-tuning method on multiple datasets across all languages using solely unlabeled instances in the target language. Empirical results show that jointly reducing feature incongruity for multiple target languages is vital for successful cross-lingual transfer. Moreover, our model enables better cross-lingual transfer than standard fine-tuning methods, even in the few-shot setting.
"Diversity and Uncertainty in Moderation" are the Key to Data Selection for Multilingual Few-shot Transfer
Jun 30, 2022



Few-shot transfer often shows substantial gain over zero-shot transfer~\cite{lauscher2020zero}, which is a practically useful trade-off between fully supervised and unsupervised learning approaches for multilingual pretrained model-based systems. This paper explores various strategies for selecting data for annotation that can result in a better few-shot transfer. The proposed approaches rely on multiple measures such as data entropy using $n$-gram language model, predictive entropy, and gradient embedding. We propose a loss embedding method for sequence labeling tasks, which induces diversity and uncertainty sampling similar to gradient embedding. The proposed data selection strategies are evaluated and compared for POS tagging, NER, and NLI tasks for up to 20 languages. Our experiments show that the gradient and loss embedding-based strategies consistently outperform random data selection baselines, with gains varying with the initial performance of the zero-shot transfer. Furthermore, the proposed method shows similar trends in improvement even when the model is fine-tuned using a lower proportion of the original task-specific labeled training data for zero-shot transfer.
Multi Task Learning For Zero Shot Performance Prediction of Multilingual Models
May 12, 2022


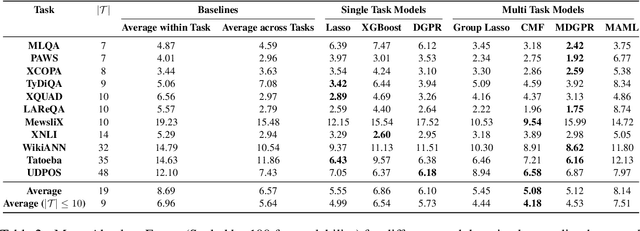
Massively Multilingual Transformer based Language Models have been observed to be surprisingly effective on zero-shot transfer across languages, though the performance varies from language to language depending on the pivot language(s) used for fine-tuning. In this work, we build upon some of the existing techniques for predicting the zero-shot performance on a task, by modeling it as a multi-task learning problem. We jointly train predictive models for different tasks which helps us build more accurate predictors for tasks where we have test data in very few languages to measure the actual performance of the model. Our approach also lends us the ability to perform a much more robust feature selection and identify a common set of features that influence zero-shot performance across a variety of tasks.