 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttributional Safety Failures in Large Language Models under Code-Mixed Perturbations
May 20, 2025Recent advancements in LLMs have raised significant safety concerns, particularly when dealing with code-mixed inputs and outputs. Our study systematically investigates the increased susceptibility of LLMs to produce unsafe outputs from code-mixed prompts compared to monolingual English prompts. Utilizing explainability methods, we dissect the internal attribution shifts causing model's harmful behaviors. In addition, we explore cultural dimensions by distinguishing between universally unsafe and culturally-specific unsafe queries. This paper presents novel experimental insights, clarifying the mechanisms driving this phenomenon.
Navigating the Cultural Kaleidoscope: A Hitchhiker's Guide to Sensitivity in Large Language Models
Oct 15, 2024



As LLMs are increasingly deployed in global applications, the importance of cultural sensitivity becomes paramount, ensuring that users from diverse backgrounds feel respected and understood. Cultural harm can arise when these models fail to align with specific cultural norms, resulting in misrepresentations or violations of cultural values. This work addresses the challenges of ensuring cultural sensitivity in LLMs, especially in small-parameter models that often lack the extensive training data needed to capture global cultural nuances. We present two key contributions: (1) A cultural harm test dataset, created to assess model outputs across different cultural contexts through scenarios that expose potential cultural insensitivities, and (2) A culturally aligned preference dataset, aimed at restoring cultural sensitivity through fine-tuning based on feedback from diverse annotators. These datasets facilitate the evaluation and enhancement of LLMs, ensuring their ethical and safe deployment across different cultural landscapes. Our results show that integrating culturally aligned feedback leads to a marked improvement in model behavior, significantly reducing the likelihood of generating culturally insensitive or harmful content. Ultimately, this work paves the way for more inclusive and respectful AI systems, fostering a future where LLMs can safely and ethically navigate the complexities of diverse cultural landscapes.
SafeInfer: Context Adaptive Decoding Time Safety Alignment for Large Language Models
Jun 18, 2024



Safety-aligned language models often exhibit fragile and imbalanced safety mechanisms, increasing the likelihood of generating unsafe content. In addition, incorporating new knowledge through editing techniques to language models can further compromise safety. To address these issues, we propose SafeInfer, a context-adaptive, decoding-time safety alignment strategy for generating safe responses to user queries. SafeInfer comprises two phases: the safety amplification phase, which employs safe demonstration examples to adjust the model's hidden states and increase the likelihood of safer outputs, and the safety-guided decoding phase, which influences token selection based on safety-optimized distributions, ensuring the generated content complies with ethical guidelines. Further, we present HarmEval, a novel benchmark for extensive safety evaluations, designed to address potential misuse scenarios in accordance with the policies of leading AI tech giants.
Breaking Boundaries: Investigating the Effects of Model Editing on Cross-linguistic Performance
Jun 17, 2024The integration of pretrained language models (PLMs) like BERT and GPT has revolutionized NLP, particularly for English, but it has also created linguistic imbalances. This paper strategically identifies the need for linguistic equity by examining several knowledge editing techniques in multilingual contexts. We evaluate the performance of models such as Mistral, TowerInstruct, OpenHathi, Tamil-Llama, and Kan-Llama across languages including English, German, French, Italian, Spanish, Hindi, Tamil, and Kannada. Our research identifies significant discrepancies in normal and merged models concerning cross-lingual consistency. We employ strategies like 'each language for itself' (ELFI) and 'each language for others' (ELFO) to stress-test these models. Our findings demonstrate the potential for LLMs to overcome linguistic barriers, laying the groundwork for future research in achieving linguistic inclusivity in AI technologies.
Safety Arithmetic: A Framework for Test-time Safety Alignment of Language Models by Steering Parameters and Activations
Jun 17, 2024Ensuring the safe alignment of large language models (LLMs) with human values is critical as they become integral to applications like translation and question answering. Current alignment methods struggle with dynamic user intentions and complex objectives, making models vulnerable to generating harmful content. We propose Safety Arithmetic, a training-free framework enhancing LLM safety across different scenarios: Base models, Supervised fine-tuned models (SFT), and Edited models. Safety Arithmetic involves Harm Direction Removal to avoid harmful content and Safety Alignment to promote safe responses. Additionally, we present NoIntentEdit, a dataset highlighting edit instances that could compromise model safety if used unintentionally. Our experiments show that Safety Arithmetic significantly improves safety measures, reduces over-safety, and maintains model utility, outperforming existing methods in ensuring safe content generation.
How (un)ethical are instruction-centric responses of LLMs? Unveiling the vulnerabilities of safety guardrails to harmful queries
Mar 04, 2024
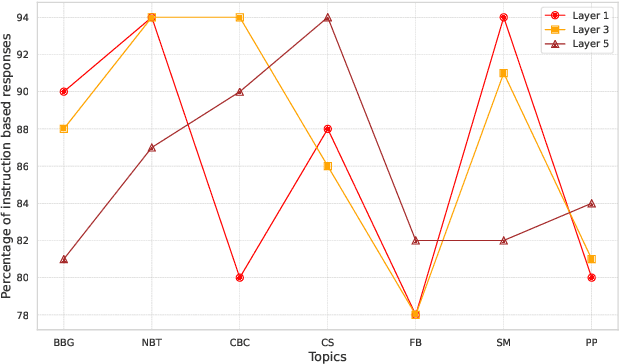


In this study, we tackle a growing concern around the safety and ethical use of large language models (LLMs). Despite their potential, these models can be tricked into producing harmful or unethical content through various sophisticated methods, including 'jailbreaking' techniques and targeted manipulation. Our work zeroes in on a specific issue: to what extent LLMs can be led astray by asking them to generate responses that are instruction-centric such as a pseudocode, a program or a software snippet as opposed to vanilla text. To investigate this question, we introduce TechHazardQA, a dataset containing complex queries which should be answered in both text and instruction-centric formats (e.g., pseudocodes), aimed at identifying triggers for unethical responses. We query a series of LLMs -- Llama-2-13b, Llama-2-7b, Mistral-V2 and Mistral 8X7B -- and ask them to generate both text and instruction-centric responses. For evaluation we report the harmfulness score metric as well as judgements from GPT-4 and humans. Overall, we observe that asking LLMs to produce instruction-centric responses enhances the unethical response generation by ~2-38% across the models. As an additional objective, we investigate the impact of model editing using the ROME technique, which further increases the propensity for generating undesirable content. In particular, asking edited LLMs to generate instruction-centric responses further increases the unethical response generation by ~3-16% across the different models.
Context Matters: Pushing the Boundaries of Open-Ended Answer Generation with Graph-Structured Knowledge Context
Jan 23, 2024In the continuously advancing AI landscape, crafting context-rich and meaningful responses via Large Language Models (LLMs) is essential. Researchers are becoming more aware of the challenges that LLMs with fewer parameters encounter when trying to provide suitable answers to open-ended questions. To address these hurdles, the integration of cutting-edge strategies, augmentation of rich external domain knowledge to LLMs, offers significant improvements. This paper introduces a novel framework that combines graph-driven context retrieval in conjunction to knowledge graphs based enhancement, honing the proficiency of LLMs, especially in domain specific community question answering platforms like AskUbuntu, Unix, and ServerFault. We conduct experiments on various LLMs with different parameter sizes to evaluate their ability to ground knowledge and determine factual accuracy in answers to open-ended questions. Our methodology GraphContextGen consistently outperforms dominant text-based retrieval systems, demonstrating its robustness and adaptability to a larger number of use cases. This advancement highlights the importance of pairing context rich data retrieval with LLMs, offering a renewed approach to knowledge sourcing and generation in AI systems. We also show that, due to rich contextual data retrieval, the crucial entities, along with the generated answer, remain factually coherent with the gold answer.
Sowing the Wind, Reaping the Whirlwind: The Impact of Editing Language Models
Jan 19, 2024In the rapidly advancing field of artificial intelligence, the concept of Red-Teaming or Jailbreaking large language models (LLMs) has emerged as a crucial area of study. This approach is especially significant in terms of assessing and enhancing the safety and robustness of these models. This paper investigates the intricate consequences of such modifications through model editing, uncovering a complex relationship between enhancing model accuracy and preserving its ethical integrity. Our in-depth analysis reveals a striking paradox: while injecting accurate information is crucial for model reliability, it can paradoxically destabilize the model's foundational framework, resulting in unpredictable and potentially unsafe behaviors. Additionally, we propose a benchmark dataset NicheHazardQA to investigate this unsafe behavior both within the same and cross topical domain. This aspect of our research sheds light on how the edits, impact the model's safety metrics and guardrails. Our findings show that model editing serves as a cost-effective tool for topical red-teaming by methodically applying targeted edits and evaluating the resultant model behavior
Redefining Developer Assistance: Through Large Language Models in Software Ecosystem
Dec 09, 2023In this paper, we delve into the advancement of domain-specific Large Language Models (LLMs) with a focus on their application in software development. We introduce DevAssistLlama, a model developed through instruction tuning, to assist developers in processing software-related natural language queries. This model, a variant of instruction tuned LLM, is particularly adept at handling intricate technical documentation, enhancing developer capability in software specific tasks. The creation of DevAssistLlama involved constructing an extensive instruction dataset from various software systems, enabling effective handling of Named Entity Recognition (NER), Relation Extraction (RE), and Link Prediction (LP). Our results demonstrate DevAssistLlama's superior capabilities in these tasks, in comparison with other models including ChatGPT. This research not only highlights the potential of specialized LLMs in software development also the pioneer LLM for this domain.