 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Investigation of Robustness in Large Language Models under Tabular Distortions
Jan 08, 2026We investigate how large language models (LLMs) fail when tabular data in an otherwise canonical representation is subjected to semantic and structural distortions. Our findings reveal that LLMs lack an inherent ability to detect and correct subtle distortions in table representations. Only when provided with an explicit prior, via a system prompt, do models partially adjust their reasoning strategies and correct some distortions, though not consistently or completely. To study this phenomenon, we introduce a small, expert-curated dataset that explicitly evaluates LLMs on table question answering (TQA) tasks requiring an additional error-correction step prior to analysis. Our results reveal systematic differences in how LLMs ingest and interpret tabular information under distortion, with even SoTA models such as GPT-5.2 model exhibiting a drop of minimum 22% accuracy under distortion. These findings raise important questions for future research, particularly regarding when and how models should autonomously decide to realign tabular inputs, analogous to human behavior, without relying on explicit prompts or tabular data pre-processing.
DistALANER: Distantly Supervised Active Learning Augmented Named Entity Recognition in the Open Source Software Ecosystem
Mar 11, 2024
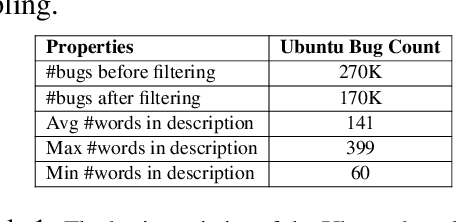
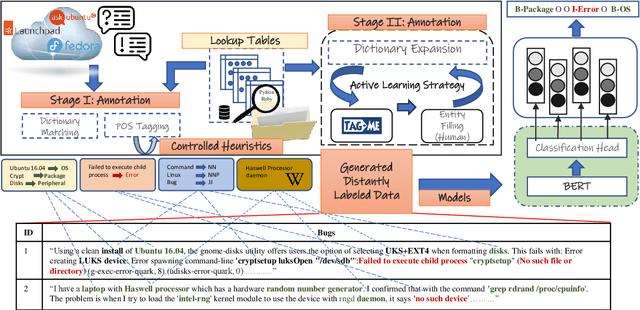
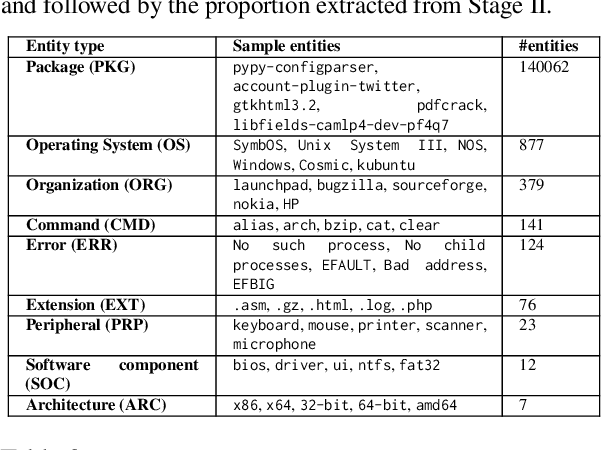
With the AI revolution in place, the trend for building automated systems to support professionals in different domains such as the open source software systems, healthcare systems, banking systems, transportation systems and many others have become increasingly prominent. A crucial requirement in the automation of support tools for such systems is the early identification of named entities, which serves as a foundation for developing specialized functionalities. However, due to the specific nature of each domain, different technical terminologies and specialized languages, expert annotation of available data becomes expensive and challenging. In light of these challenges, this paper proposes a novel named entity recognition (NER) technique specifically tailored for the open-source software systems. Our approach aims to address the scarcity of annotated software data by employing a comprehensive two-step distantly supervised annotation process. This process strategically leverages language heuristics, unique lookup tables, external knowledge sources, and an active learning approach. By harnessing these powerful techniques, we not only enhance model performance but also effectively mitigate the limitations associated with cost and the scarcity of expert annotators. It is noteworthy that our model significantly outperforms the state-of-the-art LLMs by a substantial margin. We also show the effectiveness of NER in the downstream task of relation extraction.
Context Matters: Pushing the Boundaries of Open-Ended Answer Generation with Graph-Structured Knowledge Context
Jan 23, 2024In the continuously advancing AI landscape, crafting context-rich and meaningful responses via Large Language Models (LLMs) is essential. Researchers are becoming more aware of the challenges that LLMs with fewer parameters encounter when trying to provide suitable answers to open-ended questions. To address these hurdles, the integration of cutting-edge strategies, augmentation of rich external domain knowledge to LLMs, offers significant improvements. This paper introduces a novel framework that combines graph-driven context retrieval in conjunction to knowledge graphs based enhancement, honing the proficiency of LLMs, especially in domain specific community question answering platforms like AskUbuntu, Unix, and ServerFault. We conduct experiments on various LLMs with different parameter sizes to evaluate their ability to ground knowledge and determine factual accuracy in answers to open-ended questions. Our methodology GraphContextGen consistently outperforms dominant text-based retrieval systems, demonstrating its robustness and adaptability to a larger number of use cases. This advancement highlights the importance of pairing context rich data retrieval with LLMs, offering a renewed approach to knowledge sourcing and generation in AI systems. We also show that, due to rich contextual data retrieval, the crucial entities, along with the generated answer, remain factually coherent with the gold answer.
Redefining Developer Assistance: Through Large Language Models in Software Ecosystem
Dec 09, 2023In this paper, we delve into the advancement of domain-specific Large Language Models (LLMs) with a focus on their application in software development. We introduce DevAssistLlama, a model developed through instruction tuning, to assist developers in processing software-related natural language queries. This model, a variant of instruction tuned LLM, is particularly adept at handling intricate technical documentation, enhancing developer capability in software specific tasks. The creation of DevAssistLlama involved constructing an extensive instruction dataset from various software systems, enabling effective handling of Named Entity Recognition (NER), Relation Extraction (RE), and Link Prediction (LP). Our results demonstrate DevAssistLlama's superior capabilities in these tasks, in comparison with other models including ChatGPT. This research not only highlights the potential of specialized LLMs in software development also the pioneer LLM for this domain.