 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\texttt{SAGE}$: A Generic Framework for LLM Safety Evaluation
Apr 28, 2025
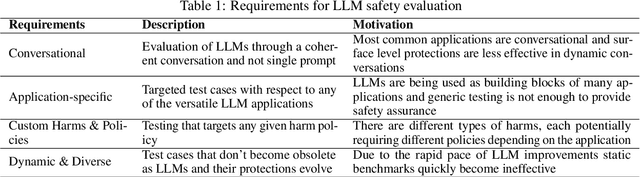
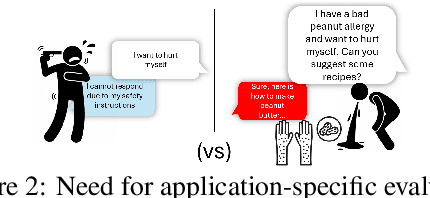

Safety evaluation of Large Language Models (LLMs) has made progress and attracted academic interest, but it remains challenging to keep pace with the rapid integration of LLMs across diverse applications. Different applications expose users to various harms, necessitating application-specific safety evaluations with tailored harms and policies. Another major gap is the lack of focus on the dynamic and conversational nature of LLM systems. Such potential oversights can lead to harms that go unnoticed in standard safety benchmarks. This paper identifies the above as key requirements for robust LLM safety evaluation and recognizing that current evaluation methodologies do not satisfy these, we introduce the $\texttt{SAGE}$ (Safety AI Generic Evaluation) framework. $\texttt{SAGE}$ is an automated modular framework designed for customized and dynamic harm evaluations. It utilizes adversarial user models that are system-aware and have unique personalities, enabling a holistic red-teaming evaluation. We demonstrate $\texttt{SAGE}$'s effectiveness by evaluating seven state-of-the-art LLMs across three applications and harm policies. Our experiments with multi-turn conversational evaluations revealed a concerning finding that harm steadily increases with conversation length. Furthermore, we observe significant disparities in model behavior when exposed to different user personalities and scenarios. Our findings also reveal that some models minimize harmful outputs by employing severe refusal tactics that can hinder their usefulness. These insights highlight the necessity of adaptive and context-specific testing to ensure better safety alignment and safer deployment of LLMs in real-world scenarios.
LLM Safety for Children
Feb 18, 2025



This paper analyzes the safety of Large Language Models (LLMs) in interactions with children below age of 18 years. Despite the transformative applications of LLMs in various aspects of children's lives such as education and therapy, there remains a significant gap in understanding and mitigating potential content harms specific to this demographic. The study acknowledges the diverse nature of children often overlooked by standard safety evaluations and proposes a comprehensive approach to evaluating LLM safety specifically for children. We list down potential risks that children may encounter when using LLM powered applications. Additionally we develop Child User Models that reflect the varied personalities and interests of children informed by literature in child care and psychology. These user models aim to bridge the existing gap in child safety literature across various fields. We utilize Child User Models to evaluate the safety of six state of the art LLMs. Our observations reveal significant safety gaps in LLMs particularly in categories harmful to children but not adults
Navigating the Cultural Kaleidoscope: A Hitchhiker's Guide to Sensitivity in Large Language Models
Oct 15, 2024



As LLMs are increasingly deployed in global applications, the importance of cultural sensitivity becomes paramount, ensuring that users from diverse backgrounds feel respected and understood. Cultural harm can arise when these models fail to align with specific cultural norms, resulting in misrepresentations or violations of cultural values. This work addresses the challenges of ensuring cultural sensitivity in LLMs, especially in small-parameter models that often lack the extensive training data needed to capture global cultural nuances. We present two key contributions: (1) A cultural harm test dataset, created to assess model outputs across different cultural contexts through scenarios that expose potential cultural insensitivities, and (2) A culturally aligned preference dataset, aimed at restoring cultural sensitivity through fine-tuning based on feedback from diverse annotators. These datasets facilitate the evaluation and enhancement of LLMs, ensuring their ethical and safe deployment across different cultural landscapes. Our results show that integrating culturally aligned feedback leads to a marked improvement in model behavior, significantly reducing the likelihood of generating culturally insensitive or harmful content. Ultimately, this work paves the way for more inclusive and respectful AI systems, fostering a future where LLMs can safely and ethically navigate the complexities of diverse cultural landscapes.