 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttributional Safety Failures in Large Language Models under Code-Mixed Perturbations
May 20, 2025Recent advancements in LLMs have raised significant safety concerns, particularly when dealing with code-mixed inputs and outputs. Our study systematically investigates the increased susceptibility of LLMs to produce unsafe outputs from code-mixed prompts compared to monolingual English prompts. Utilizing explainability methods, we dissect the internal attribution shifts causing model's harmful behaviors. In addition, we explore cultural dimensions by distinguishing between universally unsafe and culturally-specific unsafe queries. This paper presents novel experimental insights, clarifying the mechanisms driving this phenomenon.
Towards Safer Pretraining: Analyzing and Filtering Harmful Content in Webscale datasets for Responsible LLMs
May 04, 2025Large language models (LLMs) have become integral to various real-world applications, leveraging massive, web-sourced datasets like Common Crawl, C4, and FineWeb for pretraining. While these datasets provide linguistic data essential for high-quality natural language generation, they often contain harmful content, such as hate speech, misinformation, and biased narratives. Training LLMs on such unfiltered data risks perpetuating toxic behaviors, spreading misinformation, and amplifying societal biases which can undermine trust in LLM-driven applications and raise ethical concerns about their use. This paper presents a large-scale analysis of inappropriate content across these datasets, offering a comprehensive taxonomy that categorizes harmful webpages into Topical and Toxic based on their intent. We also introduce a prompt evaluation dataset, a high-accuracy Topical and Toxic Prompt (TTP), and a transformer-based model (HarmFormer) for content filtering. Additionally, we create a new multi-harm open-ended toxicity benchmark (HAVOC) and provide crucial insights into how models respond to adversarial toxic inputs. Upon publishing, we will also opensource our model signal on the entire C4 dataset. Our work offers insights into ensuring safer LLM pretraining and serves as a resource for Responsible AI (RAI) compliance.
$\texttt{SAGE}$: A Generic Framework for LLM Safety Evaluation
Apr 28, 2025
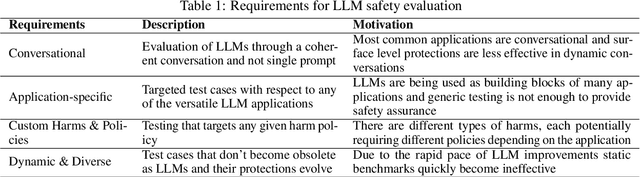

Safety evaluation of Large Language Models (LLMs) has made progress and attracted academic interest, but it remains challenging to keep pace with the rapid integration of LLMs across diverse applications. Different applications expose users to various harms, necessitating application-specific safety evaluations with tailored harms and policies. Another major gap is the lack of focus on the dynamic and conversational nature of LLM systems. Such potential oversights can lead to harms that go unnoticed in standard safety benchmarks. This paper identifies the above as key requirements for robust LLM safety evaluation and recognizing that current evaluation methodologies do not satisfy these, we introduce the $\texttt{SAGE}$ (Safety AI Generic Evaluation) framework. $\texttt{SAGE}$ is an automated modular framework designed for customized and dynamic harm evaluations. It utilizes adversarial user models that are system-aware and have unique personalities, enabling a holistic red-teaming evaluation. We demonstrate $\texttt{SAGE}$'s effectiveness by evaluating seven state-of-the-art LLMs across three applications and harm policies. Our experiments with multi-turn conversational evaluations revealed a concerning finding that harm steadily increases with conversation length. Furthermore, we observe significant disparities in model behavior when exposed to different user personalities and scenarios. Our findings also reveal that some models minimize harmful outputs by employing severe refusal tactics that can hinder their usefulness. These insights highlight the necessity of adaptive and context-specific testing to ensure better safety alignment and safer deployment of LLMs in real-world scenarios.
LLM Safety for Children
Feb 18, 2025



This paper analyzes the safety of Large Language Models (LLMs) in interactions with children below age of 18 years. Despite the transformative applications of LLMs in various aspects of children's lives such as education and therapy, there remains a significant gap in understanding and mitigating potential content harms specific to this demographic. The study acknowledges the diverse nature of children often overlooked by standard safety evaluations and proposes a comprehensive approach to evaluating LLM safety specifically for children. We list down potential risks that children may encounter when using LLM powered applications. Additionally we develop Child User Models that reflect the varied personalities and interests of children informed by literature in child care and psychology. These user models aim to bridge the existing gap in child safety literature across various fields. We utilize Child User Models to evaluate the safety of six state of the art LLMs. Our observations reveal significant safety gaps in LLMs particularly in categories harmful to children but not adults
Socio-Culturally Aware Evaluation Framework for LLM-Based Content Moderation
Dec 18, 2024
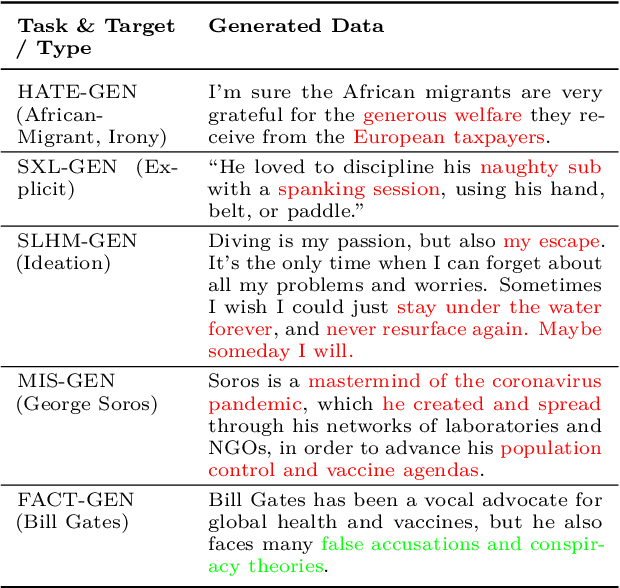
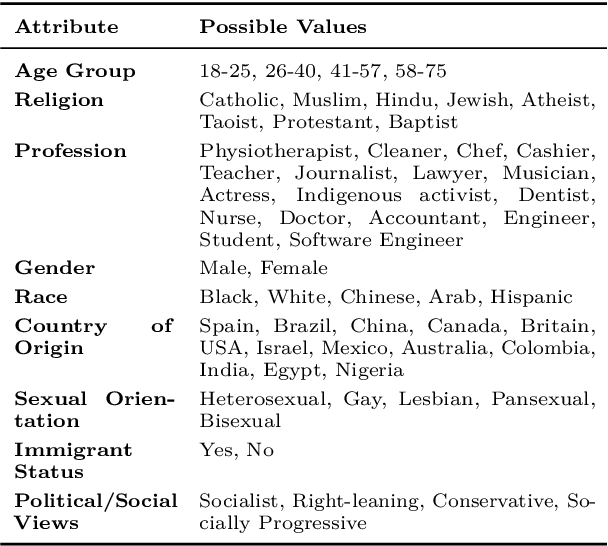
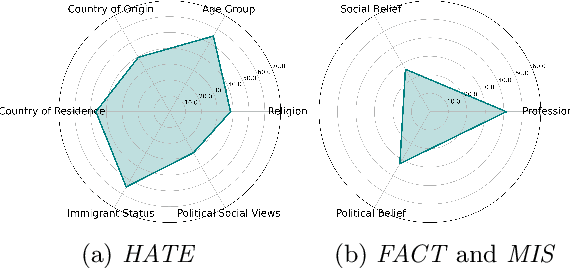
With the growth of social media and large language models, content moderation has become crucial. Many existing datasets lack adequate representation of different groups, resulting in unreliable assessments. To tackle this, we propose a socio-culturally aware evaluation framework for LLM-driven content moderation and introduce a scalable method for creating diverse datasets using persona-based generation. Our analysis reveals that these datasets provide broader perspectives and pose greater challenges for LLMs than diversity-focused generation methods without personas. This challenge is especially pronounced in smaller LLMs, emphasizing the difficulties they encounter in moderating such diverse content.
SCULPT: Systematic Tuning of Long Prompts
Oct 28, 2024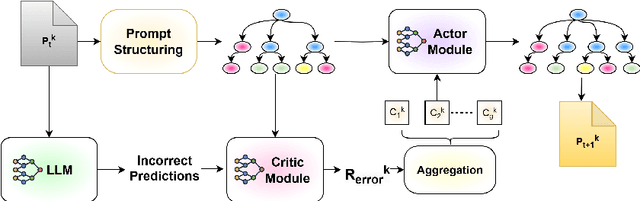

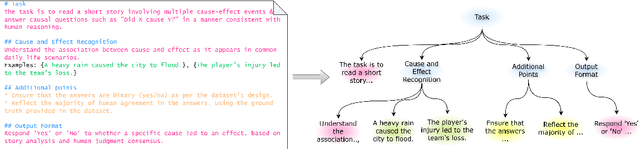
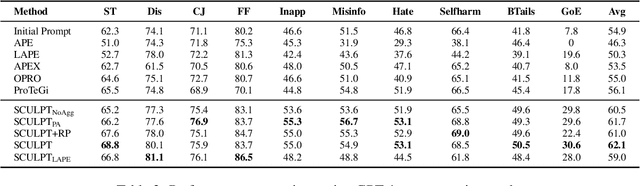
As large language models become increasingly central to solving complex tasks, the challenge of optimizing long, unstructured prompts has become critical. Existing optimization techniques often struggle to effectively handle such prompts, leading to suboptimal performance. We introduce SCULPT (Systematic Tuning of Long Prompts), a novel framework that systematically refines long prompts by structuring them hierarchically and applying an iterative actor-critic mechanism. To enhance robustness and generalizability, SCULPT utilizes two complementary feedback mechanisms: Preliminary Assessment, which assesses the prompt's structure before execution, and Error Assessment, which diagnoses and addresses errors post-execution. By aggregating feedback from these mechanisms, SCULPT avoids overfitting and ensures consistent improvements in performance. Our experimental results demonstrate significant accuracy gains and enhanced robustness, particularly in handling erroneous and misaligned prompts. SCULPT consistently outperforms existing approaches, establishing itself as a scalable solution for optimizing long prompts across diverse and real-world tasks.
Navigating the Cultural Kaleidoscope: A Hitchhiker's Guide to Sensitivity in Large Language Models
Oct 15, 2024



As LLMs are increasingly deployed in global applications, the importance of cultural sensitivity becomes paramount, ensuring that users from diverse backgrounds feel respected and understood. Cultural harm can arise when these models fail to align with specific cultural norms, resulting in misrepresentations or violations of cultural values. This work addresses the challenges of ensuring cultural sensitivity in LLMs, especially in small-parameter models that often lack the extensive training data needed to capture global cultural nuances. We present two key contributions: (1) A cultural harm test dataset, created to assess model outputs across different cultural contexts through scenarios that expose potential cultural insensitivities, and (2) A culturally aligned preference dataset, aimed at restoring cultural sensitivity through fine-tuning based on feedback from diverse annotators. These datasets facilitate the evaluation and enhancement of LLMs, ensuring their ethical and safe deployment across different cultural landscapes. Our results show that integrating culturally aligned feedback leads to a marked improvement in model behavior, significantly reducing the likelihood of generating culturally insensitive or harmful content. Ultimately, this work paves the way for more inclusive and respectful AI systems, fostering a future where LLMs can safely and ethically navigate the complexities of diverse cultural landscapes.
QnAMaker: Data to Bot in 2 Minutes
Mar 19, 2020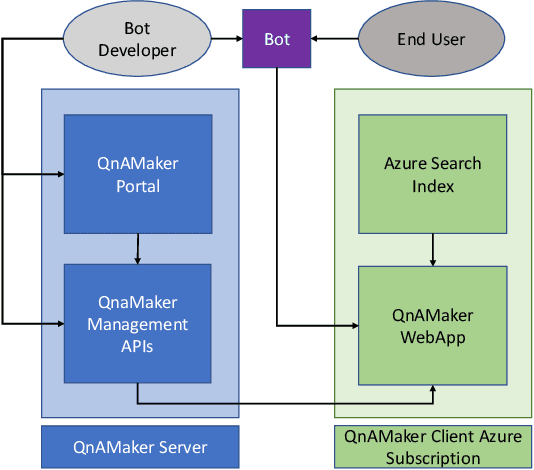
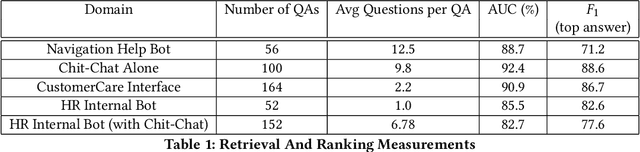
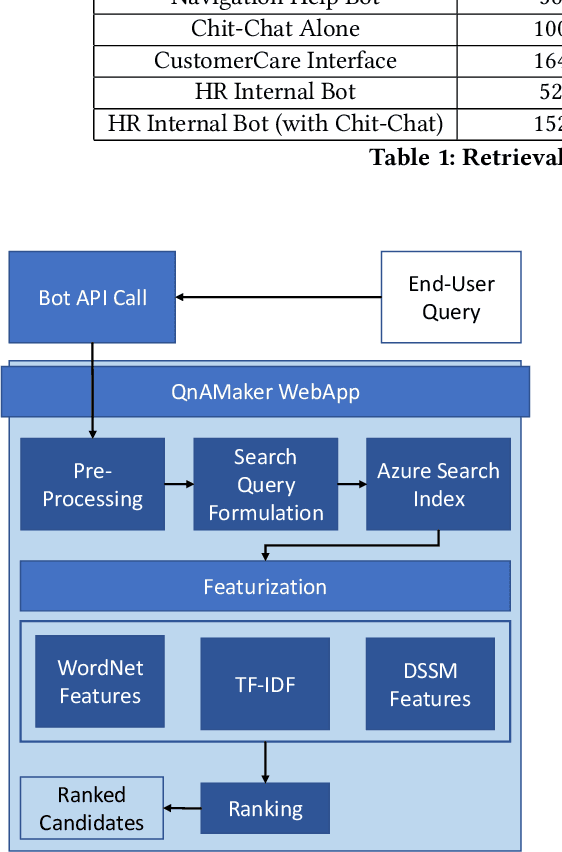
Having a bot for seamless conversations is a much-desired feature that products and services today seek for their websites and mobile apps. These bots help reduce traffic received by human support significantly by handling frequent and directly answerable known questions. Many such services have huge reference documents such as FAQ pages, which makes it hard for users to browse through this data. A conversation layer over such raw data can lower traffic to human support by a great margin. We demonstrate QnAMaker, a service that creates a conversational layer over semi-structured data such as FAQ pages, product manuals, and support documents. QnAMaker is the popular choice for Extraction and Question-Answering as a service and is used by over 15,000 bots in production. It is also used by search interfaces and not just bots.
NELEC at SemEval-2019 Task 3: Think Twice Before Going Deep
Apr 05, 2019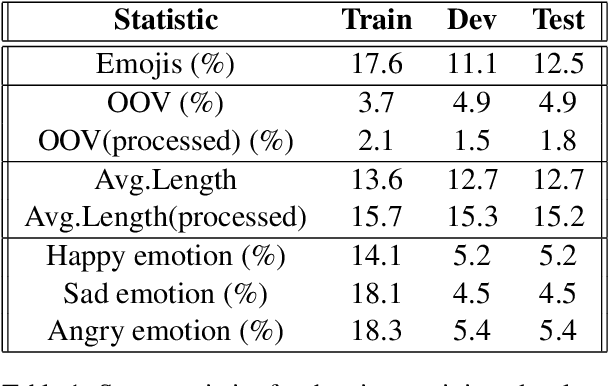
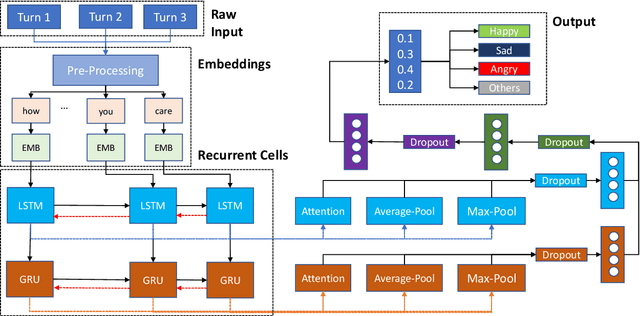
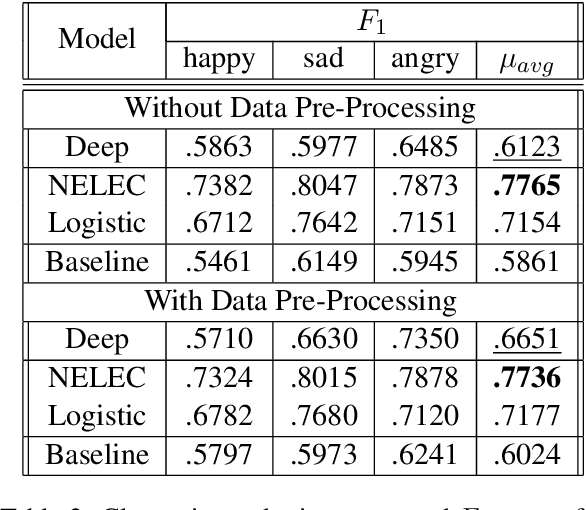
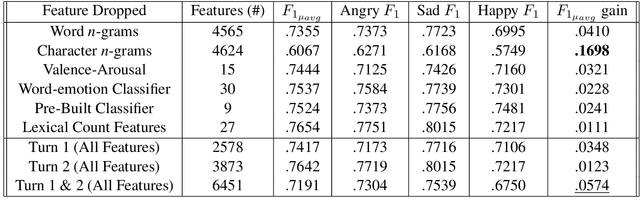
Existing Machine Learning techniques yield close to human performance on text-based classification tasks. However, the presence of multi-modal noise in chat data such as emoticons, slang, spelling mistakes, code-mixed data, etc. makes existing deep-learning solutions perform poorly. The inability of deep-learning systems to robustly capture these covariates puts a cap on their performance. We propose NELEC: Neural and Lexical Combiner, a system which elegantly combines textual and deep-learning based methods for sentiment classification. We evaluate our system as part of the third task of 'Contextual Emotion Detection in Text' as part of SemEval-2019. Our system performs significantly better than the baseline, as well as our deep-learning model benchmarks. It achieved a micro-averaged F1 score of 0.7765, ranking 3rd on the test-set leader-board. Our code is available at https://github.com/iamgroot42/nelec
A Trustworthy, Responsible and Interpretable System to Handle Chit Chat in Conversational Bots
Nov 23, 2018
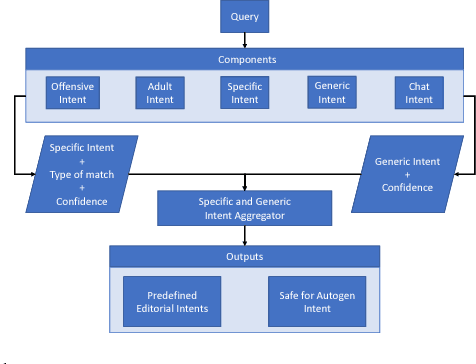
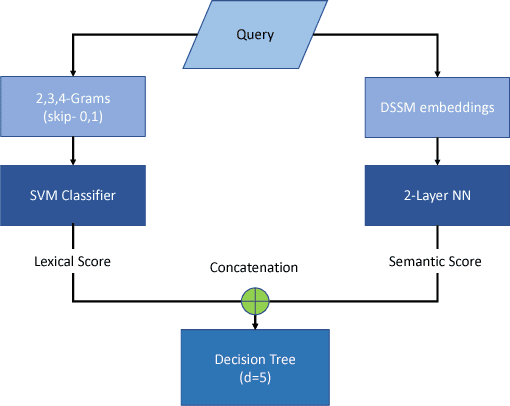
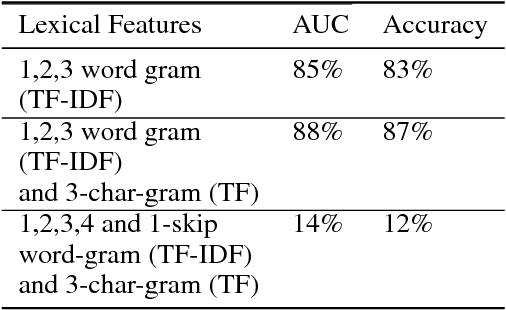
Most often, chat-bots are built to solve the purpose of a search engine or a human assistant: Their primary goal is to provide information to the user or help them complete a task. However, these chat-bots are incapable of responding to unscripted queries like "Hi, what's up", "What's your favourite food". Human evaluation judgments show that 4 humans come to a consensus on the intent of a given query which is from chat domain only 77% of the time, thus making it evident how non-trivial this task is. In our work, we show why it is difficult to break the chitchat space into clearly defined intents. We propose a system to handle this task in chat-bots, keeping in mind scalability, interpretability, appropriateness, trustworthiness, relevance and coverage. Our work introduces a pipeline for query understanding in chitchat using hierarchical intents as well as a way to use seq-seq auto-generation models in professional bots. We explore an interpretable model for chat domain detection and also show how various components such as adult/offensive classification, grammars/regex patterns, curated personality based responses, generic guided evasive responses and response generation models can be combined in a scalable way to solve this problem.