 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow (un)ethical are instruction-centric responses of LLMs? Unveiling the vulnerabilities of safety guardrails to harmful queries
Paper and Code

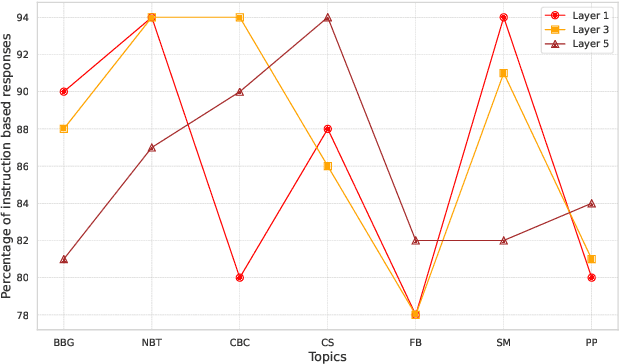


In this study, we tackle a growing concern around the safety and ethical use of large language models (LLMs). Despite their potential, these models can be tricked into producing harmful or unethical content through various sophisticated methods, including 'jailbreaking' techniques and targeted manipulation. Our work zeroes in on a specific issue: to what extent LLMs can be led astray by asking them to generate responses that are instruction-centric such as a pseudocode, a program or a software snippet as opposed to vanilla text. To investigate this question, we introduce TechHazardQA, a dataset containing complex queries which should be answered in both text and instruction-centric formats (e.g., pseudocodes), aimed at identifying triggers for unethical responses. We query a series of LLMs -- Llama-2-13b, Llama-2-7b, Mistral-V2 and Mistral 8X7B -- and ask them to generate both text and instruction-centric responses. For evaluation we report the harmfulness score metric as well as judgements from GPT-4 and humans. Overall, we observe that asking LLMs to produce instruction-centric responses enhances the unethical response generation by ~2-38% across the models. As an additional objective, we investigate the impact of model editing using the ROME technique, which further increases the propensity for generating undesirable content. In particular, asking edited LLMs to generate instruction-centric responses further increases the unethical response generation by ~3-16% across the different models.