 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIPatient: Simulating Patients with EHRs and LLM Powered Agentic Workflow
Sep 27, 2024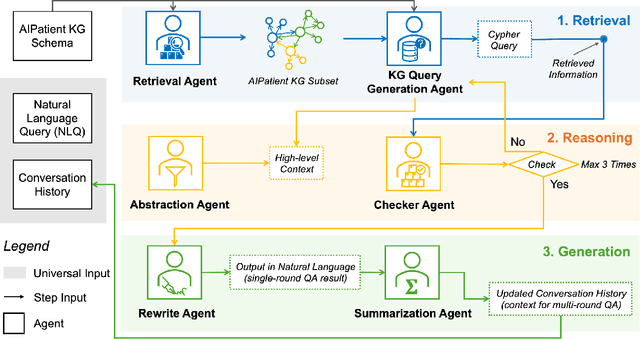
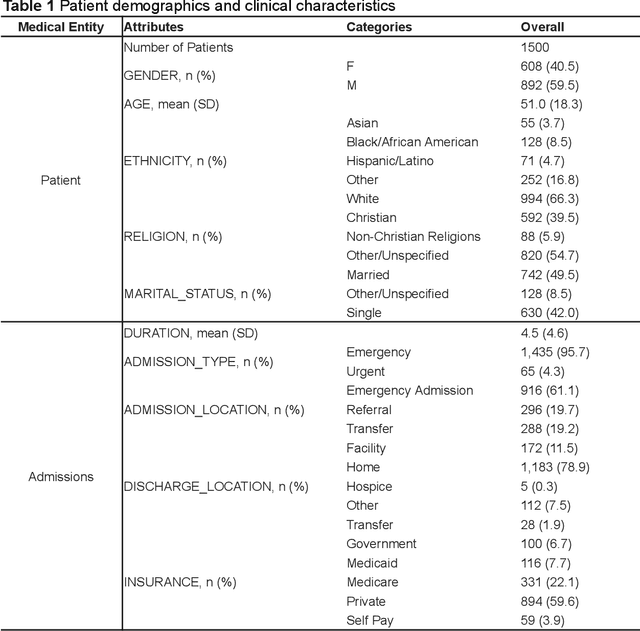
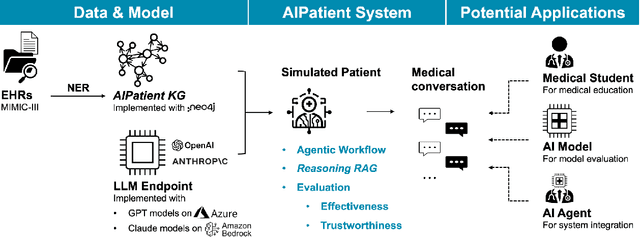
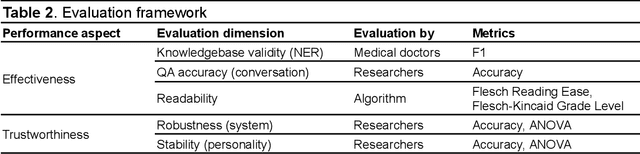
Simulated patient systems play a crucial role in modern medical education and research, providing safe, integrative learning environments and enabling clinical decision-making simulations. Large Language Models (LLM) could advance simulated patient systems by replicating medical conditions and patient-doctor interactions with high fidelity and low cost. However, ensuring the effectiveness and trustworthiness of these systems remains a challenge, as they require a large, diverse, and precise patient knowledgebase, along with a robust and stable knowledge diffusion to users. Here, we developed AIPatient, an advanced simulated patient system with AIPatient Knowledge Graph (AIPatient KG) as the input and the Reasoning Retrieval-Augmented Generation (Reasoning RAG) agentic workflow as the generation backbone. AIPatient KG samples data from Electronic Health Records (EHRs) in the Medical Information Mart for Intensive Care (MIMIC)-III database, producing a clinically diverse and relevant cohort of 1,495 patients with high knowledgebase validity (F1 0.89). Reasoning RAG leverages six LLM powered agents spanning tasks including retrieval, KG query generation, abstraction, checker, rewrite, and summarization. This agentic framework reaches an overall accuracy of 94.15% in EHR-based medical Question Answering (QA), outperforming benchmarks that use either no agent or only partial agent integration. Our system also presents high readability (median Flesch Reading Ease 77.23; median Flesch Kincaid Grade 5.6), robustness (ANOVA F-value 0.6126, p<0.1), and stability (ANOVA F-value 0.782, p<0.1). The promising performance of the AIPatient system highlights its potential to support a wide range of applications, including medical education, model evaluation, and system integration.
Large Language Models in Biomedical and Health Informatics: A Bibliometric Review
Mar 26, 2024Large Language Models (LLMs) have rapidly become important tools in Biomedical and Health Informatics (BHI), enabling new ways to analyze data, treat patients, and conduct research. This bibliometric review aims to provide a panoramic view of how LLMs have been used in BHI by examining research articles and collaboration networks from 2022 to 2023. It further explores how LLMs can improve Natural Language Processing (NLP) applications in various BHI areas like medical diagnosis, patient engagement, electronic health record management, and personalized medicine. To do this, our bibliometric review identifies key trends, maps out research networks, and highlights major developments in this fast-moving field. Lastly, it discusses the ethical concerns and practical challenges of using LLMs in BHI, such as data privacy and reliable medical recommendations. Looking ahead, we consider how LLMs could further transform biomedical research as well as healthcare delivery and patient outcomes. This bibliometric review serves as a resource for stakeholders in healthcare, including researchers, clinicians, and policymakers, to understand the current state and future potential of LLMs in BHI.
A Bibliometric Review of Large Language Models Research from 2017 to 2023
Apr 03, 2023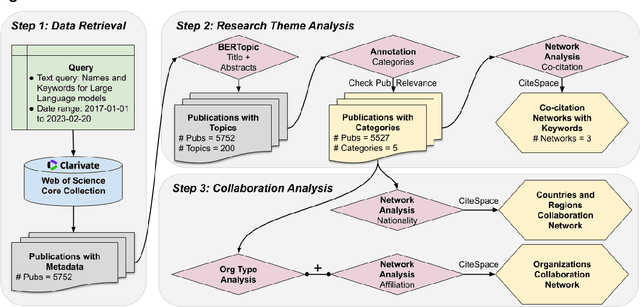

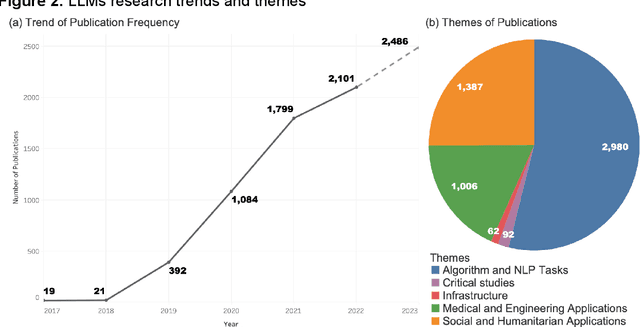
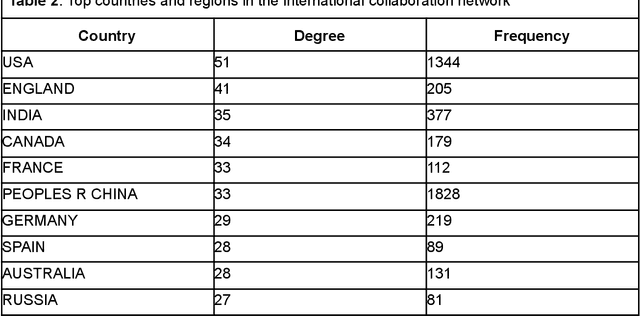
Large language models (LLMs) are a class of language models that have demonstrated outstanding performance across a range of natural language processing (NLP) tasks and have become a highly sought-after research area, because of their ability to generate human-like language and their potential to revolutionize science and technology. In this study, we conduct bibliometric and discourse analyses of scholarly literature on LLMs. Synthesizing over 5,000 publications, this paper serves as a roadmap for researchers, practitioners, and policymakers to navigate the current landscape of LLMs research. We present the research trends from 2017 to early 2023, identifying patterns in research paradigms and collaborations. We start with analyzing the core algorithm developments and NLP tasks that are fundamental in LLMs research. We then investigate the applications of LLMs in various fields and domains including medicine, engineering, social science, and humanities. Our review also reveals the dynamic, fast-paced evolution of LLMs research. Overall, this paper offers valuable insights into the current state, impact, and potential of LLMs research and its applications.
Learning from Sparse Datasets: Predicting Concrete's Strength by Machine Learning
Apr 29, 2020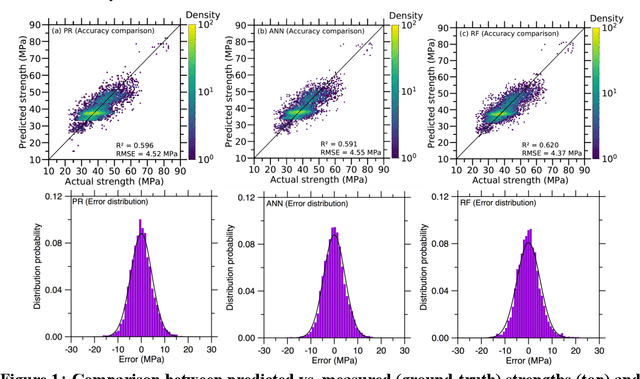
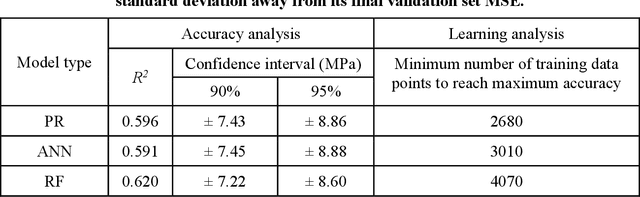
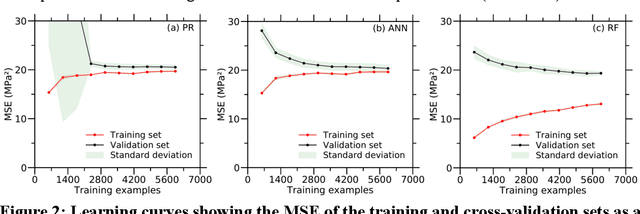
Despite enormous efforts over the last decades to establish the relationship between concrete proportioning and strength, a robust knowledge-based model for accurate concrete strength predictions is still lacking. As an alternative to physical or chemical-based models, data-driven machine learning (ML) methods offer a new solution to this problem. Although this approach is promising for handling the complex, non-linear, non-additive relationship between concrete mixture proportions and strength, a major limitation of ML lies in the fact that large datasets are needed for model training. This is a concern as reliable, consistent strength data is rather limited, especially for realistic industrial concretes. Here, based on the analysis of a large dataset (>10,000 observations) of measured compressive strengths from industrially-produced concretes, we compare the ability of select ML algorithms to "learn" how to reliably predict concrete strength as a function of the size of the dataset. Based on these results, we discuss the competition between how accurate a given model can eventually be (when trained on a large dataset) and how much data is actually required to train this model.