 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse designing metamaterials with programmable nonlinear functional responses in graph space
Aug 12, 2024



Material responses to static and dynamic stimuli, represented as nonlinear curves, are design targets for engineering functionalities like structural support, impact protection, and acoustic and photonic bandgaps. Three-dimensional metamaterials offer significant tunability due to their internal structure, yet existing methods struggle to capture their complex behavior-to-structure relationships. We present GraphMetaMat, a graph-based framework capable of designing three-dimensional metamaterials with programmable responses and arbitrary manufacturing constraints. Integrating graph networks, physics biases, reinforcement learning, and tree search, GraphMetaMat can target stress-strain curves spanning four orders of magnitude and complex behaviors, as well as viscoelastic transmission responses with varying attenuation gaps. GraphMetaMat can create cushioning materials for protective equipment and vibration-damping panels for electric vehicles, outperforming commercial materials, and enabling the automatic design of materials with on-demand functionalities.
Learning from Sparse Datasets: Predicting Concrete's Strength by Machine Learning
Apr 29, 2020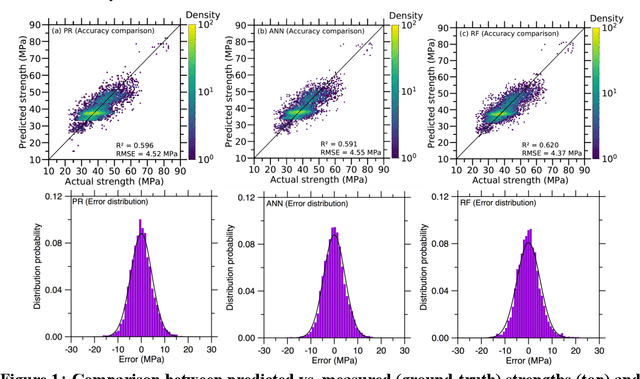
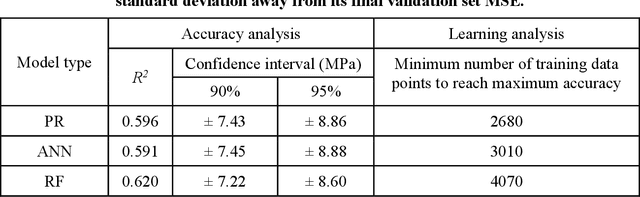
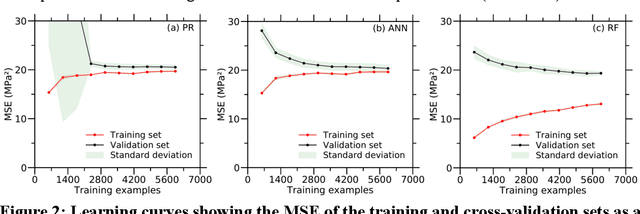
Despite enormous efforts over the last decades to establish the relationship between concrete proportioning and strength, a robust knowledge-based model for accurate concrete strength predictions is still lacking. As an alternative to physical or chemical-based models, data-driven machine learning (ML) methods offer a new solution to this problem. Although this approach is promising for handling the complex, non-linear, non-additive relationship between concrete mixture proportions and strength, a major limitation of ML lies in the fact that large datasets are needed for model training. This is a concern as reliable, consistent strength data is rather limited, especially for realistic industrial concretes. Here, based on the analysis of a large dataset (>10,000 observations) of measured compressive strengths from industrially-produced concretes, we compare the ability of select ML algorithms to "learn" how to reliably predict concrete strength as a function of the size of the dataset. Based on these results, we discuss the competition between how accurate a given model can eventually be (when trained on a large dataset) and how much data is actually required to train this model.