 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning from Monolingual ASR to Transcription-free Cross-lingual Voice Conversion
Paper and Code
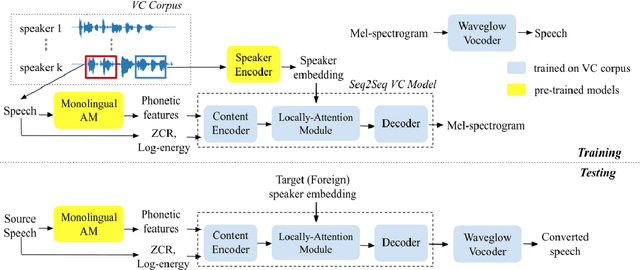
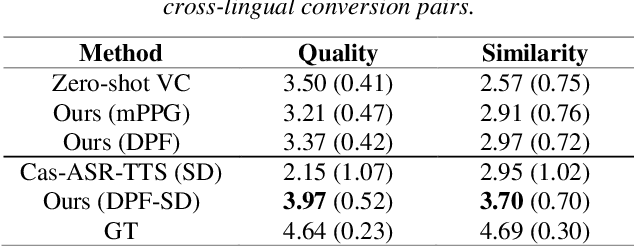

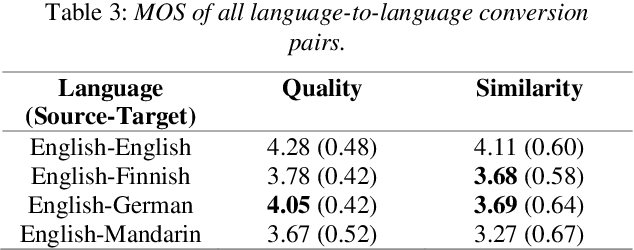
Cross-lingual voice conversion (VC) is a task that aims to synthesize target voices with the same content while source and target speakers speak in different languages. Its challenge lies in the fact that the source and target data are naturally non-parallel, and it is even difficult to bridge the gaps between languages with no transcriptions provided. In this paper, we focus on knowledge transfer from monolin-gual ASR to cross-lingual VC, in order to address the con-tent mismatch problem. To achieve this, we first train a monolingual acoustic model for the source language, use it to extract phonetic features for all the speech in the VC dataset, and then train a Seq2Seq conversion model to pre-dict the mel-spectrograms. We successfully address cross-lingual VC without any transcription or language-specific knowledge for foreign speech. We experiment this on Voice Conversion Challenge 2020 datasets and show that our speaker-dependent conversion model outperforms the zero-shot baseline, achieving MOS of 3.83 and 3.54 in speech quality and speaker similarity for cross-lingual conversion. When compared to Cascade ASR-TTS method, our proposed one significantly reduces the MOS drop be-tween intra- and cross-lingual conversion.