 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViUniT: Visual Unit Tests for More Robust Visual Programming
Paper and Code
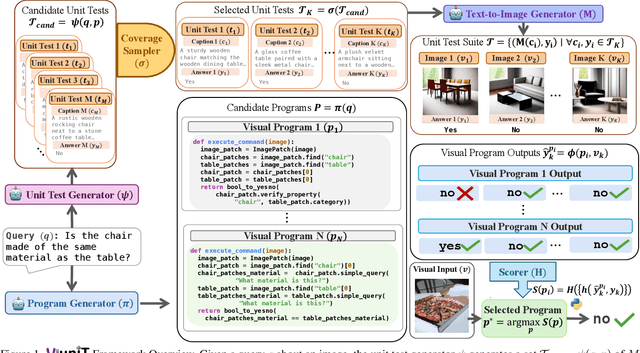
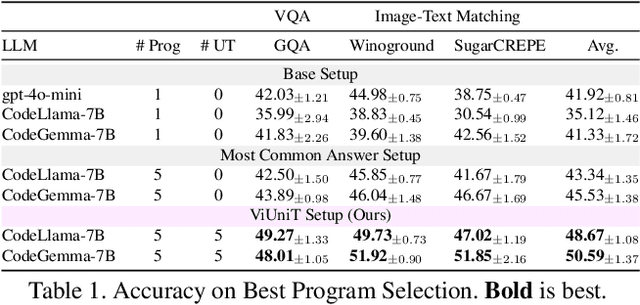
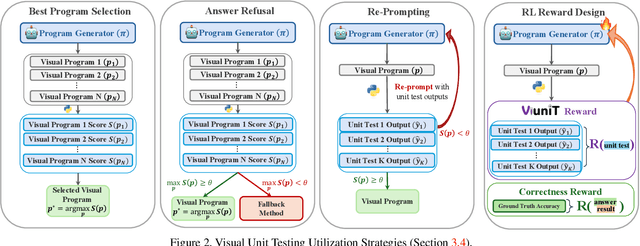
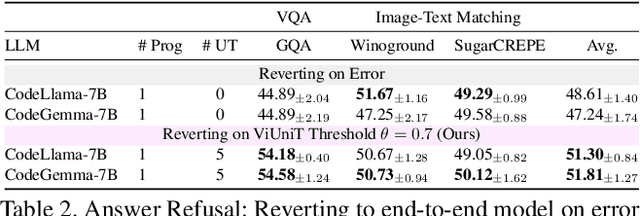
Programming based approaches to reasoning tasks have substantially expanded the types of questions models can answer about visual scenes. Yet on benchmark visual reasoning data, when models answer correctly, they produce incorrect programs 33% of the time. These models are often right for the wrong reasons and risk unexpected failures on new data. Unit tests play a foundational role in ensuring code correctness and could be used to repair such failures. We propose Visual Unit Testing (ViUniT), a framework to improve the reliability of visual programs by automatically generating unit tests. In our framework, a unit test is represented as a novel image and answer pair meant to verify the logical correctness of a program produced for a given query. Our method leverages a language model to create unit tests in the form of image descriptions and expected answers and image synthesis to produce corresponding images. We conduct a comprehensive analysis of what constitutes an effective visual unit test suite, exploring unit test generation, sampling strategies, image generation methods, and varying the number of programs and unit tests. Additionally, we introduce four applications of visual unit tests: best program selection, answer refusal, re-prompting, and unsupervised reward formulations for reinforcement learning. Experiments with two models across three datasets in visual question answering and image-text matching demonstrate that ViUniT improves model performance by 11.4%. Notably, it enables 7B open-source models to outperform gpt-4o-mini by an average of 7.7% and reduces the occurrence of programs that are correct for the wrong reasons by 40%.