 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapTrace: Scalable Data Generation for Route Tracing on Maps
Dec 22, 2025While Multimodal Large Language Models have achieved human-like performance on many visual and textual reasoning tasks, their proficiency in fine-grained spatial understanding, such as route tracing on maps remains limited. Unlike humans, who can quickly learn to parse and navigate maps, current models often fail to respect fundamental path constraints, in part due to the prohibitive cost and difficulty of collecting large-scale, pixel-accurate path annotations. To address this, we introduce a scalable synthetic data generation pipeline that leverages synthetic map images and pixel-level parsing to automatically produce precise annotations for this challenging task. Using this pipeline, we construct a fine-tuning dataset of 23k path samples across 4k maps, enabling models to acquire more human-like spatial capabilities. Using this dataset, we fine-tune both open-source and proprietary MLLMs. Results on MapBench show that finetuning substantially improves robustness, raising success rates by up to 6.4 points, while also reducing path-tracing error (NDTW). These gains highlight that fine-grained spatial reasoning, absent in pretrained models, can be explicitly taught with synthetic supervision.
ViUniT: Visual Unit Tests for More Robust Visual Programming
Dec 12, 2024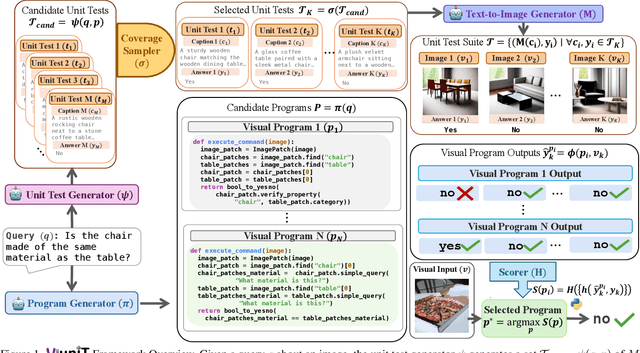
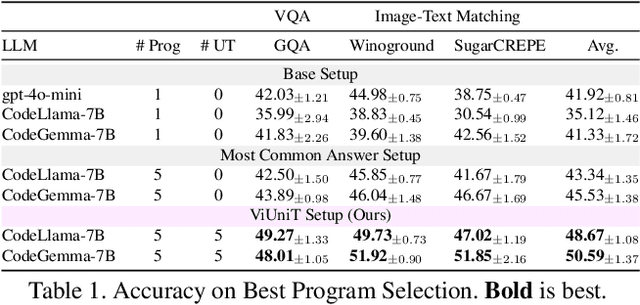
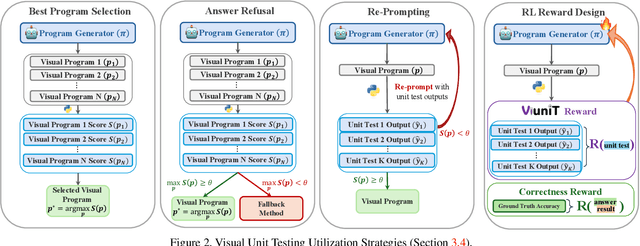
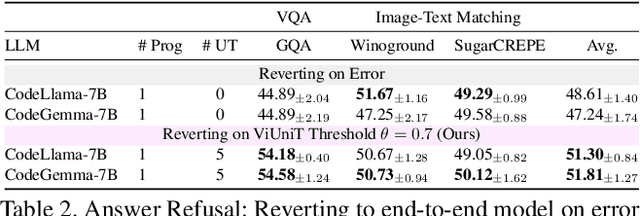
Programming based approaches to reasoning tasks have substantially expanded the types of questions models can answer about visual scenes. Yet on benchmark visual reasoning data, when models answer correctly, they produce incorrect programs 33% of the time. These models are often right for the wrong reasons and risk unexpected failures on new data. Unit tests play a foundational role in ensuring code correctness and could be used to repair such failures. We propose Visual Unit Testing (ViUniT), a framework to improve the reliability of visual programs by automatically generating unit tests. In our framework, a unit test is represented as a novel image and answer pair meant to verify the logical correctness of a program produced for a given query. Our method leverages a language model to create unit tests in the form of image descriptions and expected answers and image synthesis to produce corresponding images. We conduct a comprehensive analysis of what constitutes an effective visual unit test suite, exploring unit test generation, sampling strategies, image generation methods, and varying the number of programs and unit tests. Additionally, we introduce four applications of visual unit tests: best program selection, answer refusal, re-prompting, and unsupervised reward formulations for reinforcement learning. Experiments with two models across three datasets in visual question answering and image-text matching demonstrate that ViUniT improves model performance by 11.4%. Notably, it enables 7B open-source models to outperform gpt-4o-mini by an average of 7.7% and reduces the occurrence of programs that are correct for the wrong reasons by 40%.
Evaluating Vision-Language Models on Bistable Images
May 29, 2024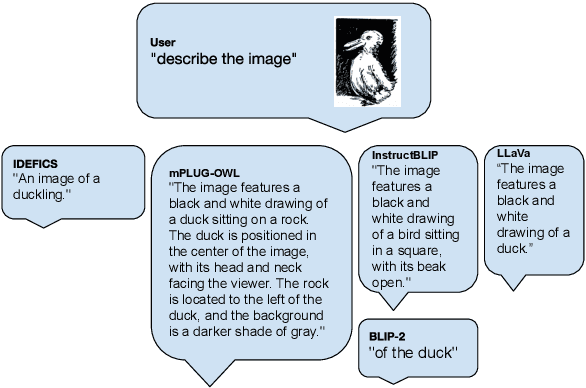

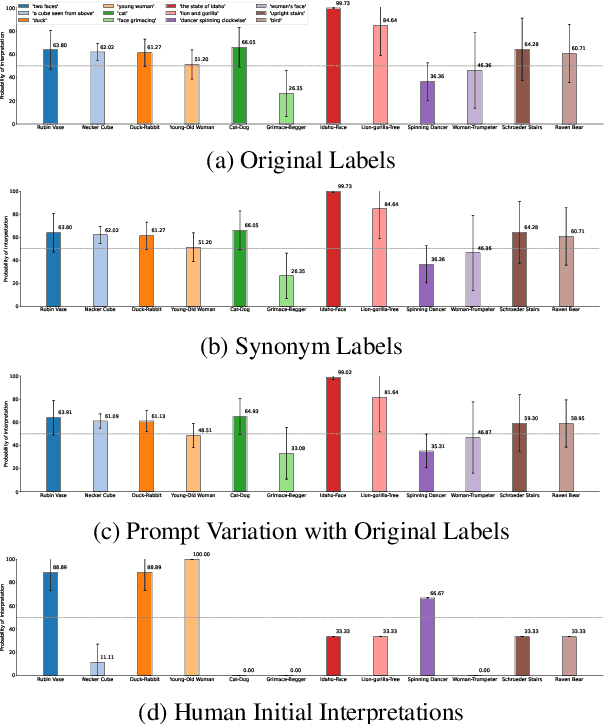

Bistable images, also known as ambiguous or reversible images, present visual stimuli that can be seen in two distinct interpretations, though not simultaneously by the observer. In this study, we conduct the most extensive examination of vision-language models using bistable images to date. We manually gathered a dataset of 29 bistable images, along with their associated labels, and subjected them to 116 different manipulations in brightness, tint, and rotation. We evaluated twelve different models in both classification and generative tasks across six model architectures. Our findings reveal that, with the exception of models from the Idefics family and LLaVA1.5-13b, there is a pronounced preference for one interpretation over another among the models, and minimal variance under image manipulations, with few exceptions on image rotations. Additionally, we compared the model preferences with humans, noting that the models do not exhibit the same continuity biases as humans and often diverge from human initial interpretations. We also investigated the influence of variations in prompts and the use of synonymous labels, discovering that these factors significantly affect model interpretations more than image manipulations showing a higher influence of the language priors on bistable image interpretations compared to image-text training data. All code and data is open sourced.
X-InstructBLIP: A Framework for aligning X-Modal instruction-aware representations to LLMs and Emergent Cross-modal Reasoning
Nov 30, 2023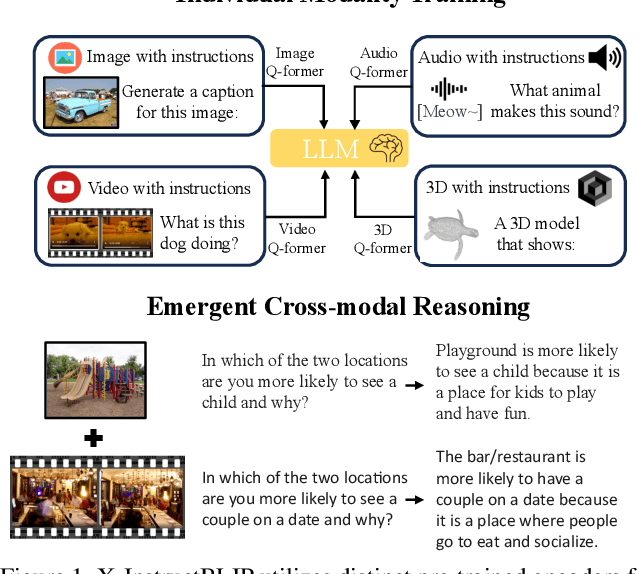


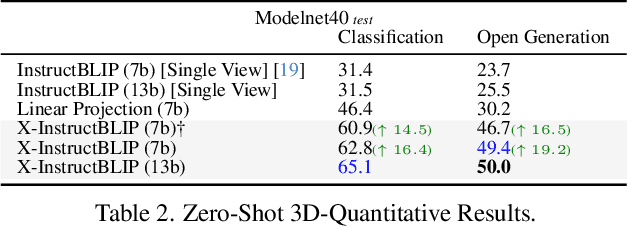
Vision-language pre-training and instruction tuning have demonstrated general-purpose capabilities in 2D visual reasoning tasks by aligning visual encoders with state-of-the-art large language models (LLMs). In this paper, we introduce a simple, yet effective, cross-modality framework built atop frozen LLMs that allows the integration of various modalities without extensive modality-specific customization. To facilitate instruction-modality fine-tuning, we collect high-quality instruction tuning data in an automatic and scalable manner, composed of 24K QA samples for audio and 250K QA samples for 3D. Leveraging instruction-aware representations, our model performs comparably with leading-edge counterparts without the need of extensive modality-specific pre-training or customization. Furthermore, our approach demonstrates cross-modal reasoning abilities across two or more input modalities, despite each modality projection being trained individually. To study the model's cross-modal abilities, we contribute a novel Discriminative Cross-modal Reasoning (DisCRn) evaluation task, comprising 9K audio-video QA samples and 28K image-3D QA samples that require the model to reason discriminatively across disparate input modalities.
I Spy a Metaphor: Large Language Models and Diffusion Models Co-Create Visual Metaphors
May 24, 2023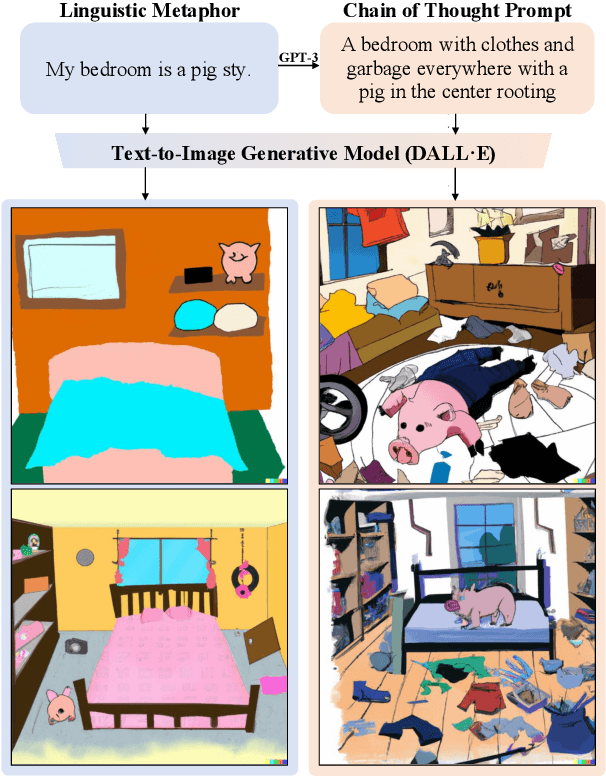

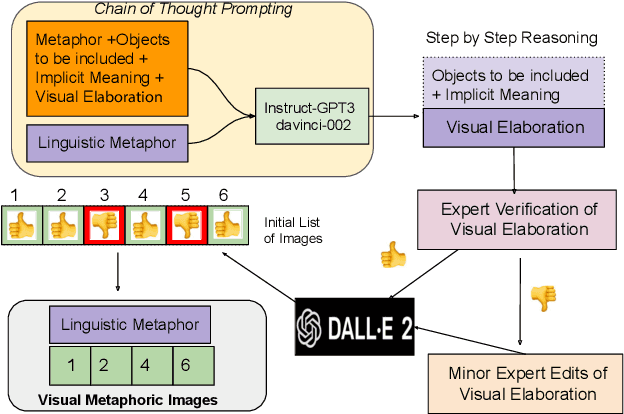

Visual metaphors are powerful rhetorical devices used to persuade or communicate creative ideas through images. Similar to linguistic metaphors, they convey meaning implicitly through symbolism and juxtaposition of the symbols. We propose a new task of generating visual metaphors from linguistic metaphors. This is a challenging task for diffusion-based text-to-image models, such as DALL$\cdot$E 2, since it requires the ability to model implicit meaning and compositionality. We propose to solve the task through the collaboration between Large Language Models (LLMs) and Diffusion Models: Instruct GPT-3 (davinci-002) with Chain-of-Thought prompting generates text that represents a visual elaboration of the linguistic metaphor containing the implicit meaning and relevant objects, which is then used as input to the diffusion-based text-to-image models.Using a human-AI collaboration framework, where humans interact both with the LLM and the top-performing diffusion model, we create a high-quality dataset containing 6,476 visual metaphors for 1,540 linguistic metaphors and their associated visual elaborations. Evaluation by professional illustrators shows the promise of LLM-Diffusion Model collaboration for this task.To evaluate the utility of our Human-AI collaboration framework and the quality of our dataset, we perform both an intrinsic human-based evaluation and an extrinsic evaluation using visual entailment as a downstream task.
Language in a Bottle: Language Model Guided Concept Bottlenecks for Interpretable Image Classification
Nov 21, 2022



Concept Bottleneck Models (CBM) are inherently interpretable models that factor model decisions into human-readable concepts. They allow people to easily understand why a model is failing, a critical feature for high-stakes applications. CBMs require manually specified concepts and often under-perform their black box counterparts, preventing their broad adoption. We address these shortcomings and are first to show how to construct high-performance CBMs without manual specification of similar accuracy to black box models. Our approach, Language Guided Bottlenecks (LaBo), leverages a language model, GPT-3, to define a large space of possible bottlenecks. Given a problem domain, LaBo uses GPT-3 to produce factual sentences about categories to form candidate concepts. LaBo efficiently searches possible bottlenecks through a novel submodular utility that promotes the selection of discriminative and diverse information. Ultimately, GPT-3's sentential concepts can be aligned to images using CLIP, to form a bottleneck layer. Experiments demonstrate that LaBo is a highly effective prior for concepts important to visual recognition. In the evaluation with 11 diverse datasets, LaBo bottlenecks excel at few-shot classification: they are 11.7% more accurate than black box linear probes at 1 shot and comparable with more data. Overall, LaBo demonstrates that inherently interpretable models can be widely applied at similar, or better, performance than black box approaches.
Visualizing the Obvious: A Concreteness-based Ensemble Model for Noun Property Prediction
Oct 24, 2022



Neural language models encode rich knowledge about entities and their relationships which can be extracted from their representations using probing. Common properties of nouns (e.g., red strawberries, small ant) are, however, more challenging to extract compared to other types of knowledge because they are rarely explicitly stated in texts. We hypothesize this to mainly be the case for perceptual properties which are obvious to the participants in the communication. We propose to extract these properties from images and use them in an ensemble model, in order to complement the information that is extracted from language models. We consider perceptual properties to be more concrete than abstract properties (e.g., interesting, flawless). We propose to use the adjectives' concreteness score as a lever to calibrate the contribution of each source (text vs. images). We evaluate our ensemble model in a ranking task where the actual properties of a noun need to be ranked higher than other non-relevant properties. Our results show that the proposed combination of text and images greatly improves noun property prediction compared to powerful text-based language models.
* Findings of EMNLP 2022; The first two authors contributed equally
Induce, Edit, Retrieve: Language Grounded Multimodal Schema for Instructional Video Retrieval
Nov 17, 2021

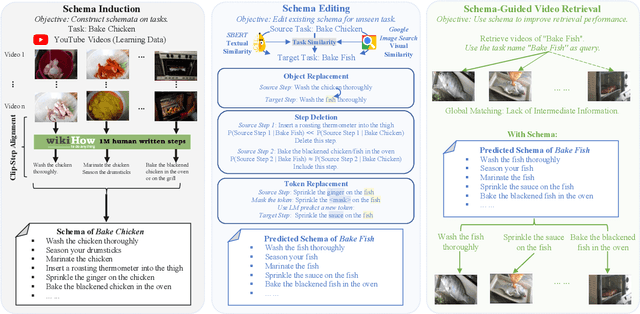
Schemata are structured representations of complex tasks that can aid artificial intelligence by allowing models to break down complex tasks into intermediate steps. We propose a novel system that induces schemata from web videos and generalizes them to capture unseen tasks with the goal of improving video retrieval performance. Our system proceeds in three major phases: (1) Given a task with related videos, we construct an initial schema for a task using a joint video-text model to match video segments with text representing steps from wikiHow; (2) We generalize schemata to unseen tasks by leveraging language models to edit the text within existing schemata. Through generalization, we can allow our schemata to cover a more extensive range of tasks with a small amount of learning data; (3) We conduct zero-shot instructional video retrieval with the unseen task names as the queries. Our schema-guided approach outperforms existing methods for video retrieval, and we demonstrate that the schemata induced by our system are better than those generated by other models.
Visual Goal-Step Inference using wikiHow
Apr 12, 2021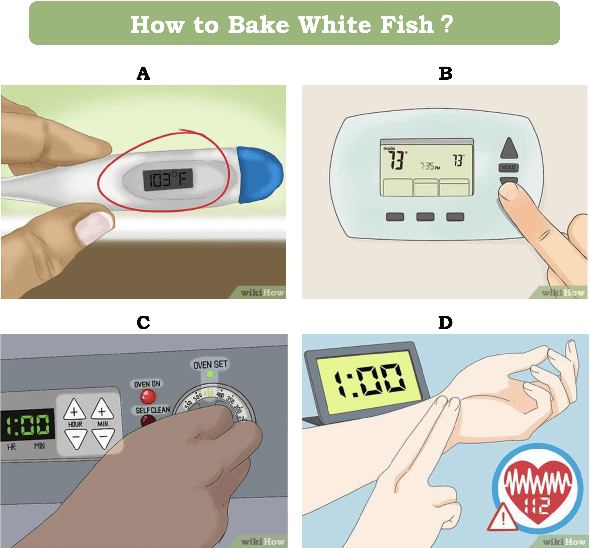
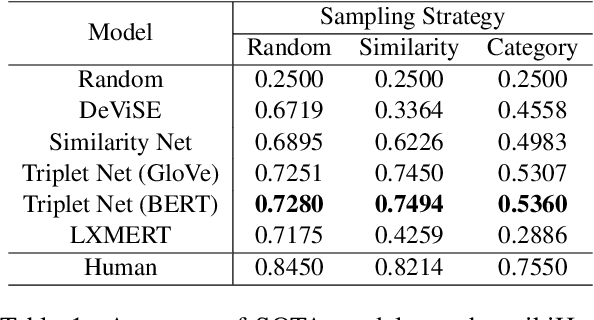
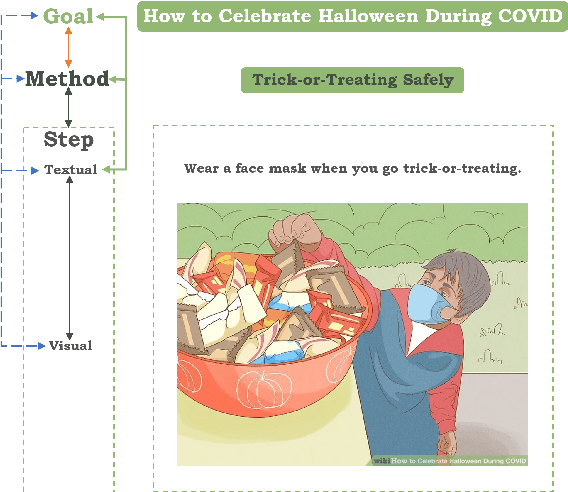
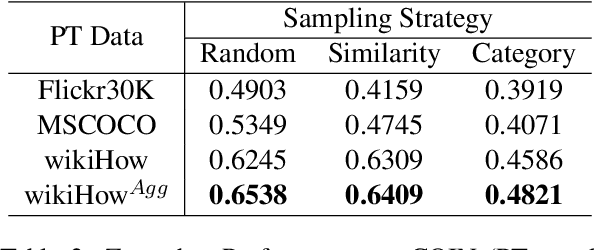
Procedural events can often be thought of as a high level goal composed of a sequence of steps. Inferring the sub-sequence of steps of a goal can help artificial intelligence systems reason about human activities. Past work in NLP has examined the task of goal-step inference for text. We introduce the visual analogue. We propose the Visual Goal-Step Inference (VGSI) task where a model is given a textual goal and must choose a plausible step towards that goal from among four candidate images. Our task is challenging for state-of-the-art muitimodal models. We introduce a novel dataset harvested from wikiHow that consists of 772,294 images representing human actions. We show that the knowledge learned from our data can effectively transfer to other datasets like HowTo100M, increasing the multiple-choice accuracy by 15% to 20%. Our task will facilitate multi-modal reasoning about procedural events.