 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInduce, Edit, Retrieve: Language Grounded Multimodal Schema for Instructional Video Retrieval
Paper and Code


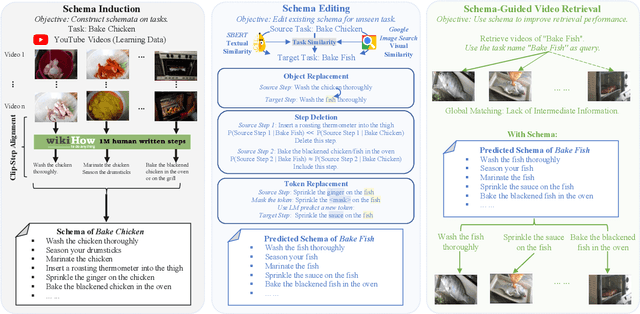
Schemata are structured representations of complex tasks that can aid artificial intelligence by allowing models to break down complex tasks into intermediate steps. We propose a novel system that induces schemata from web videos and generalizes them to capture unseen tasks with the goal of improving video retrieval performance. Our system proceeds in three major phases: (1) Given a task with related videos, we construct an initial schema for a task using a joint video-text model to match video segments with text representing steps from wikiHow; (2) We generalize schemata to unseen tasks by leveraging language models to edit the text within existing schemata. Through generalization, we can allow our schemata to cover a more extensive range of tasks with a small amount of learning data; (3) We conduct zero-shot instructional video retrieval with the unseen task names as the queries. Our schema-guided approach outperforms existing methods for video retrieval, and we demonstrate that the schemata induced by our system are better than those generated by other models.