 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Spy a Metaphor: Large Language Models and Diffusion Models Co-Create Visual Metaphors
May 24, 2023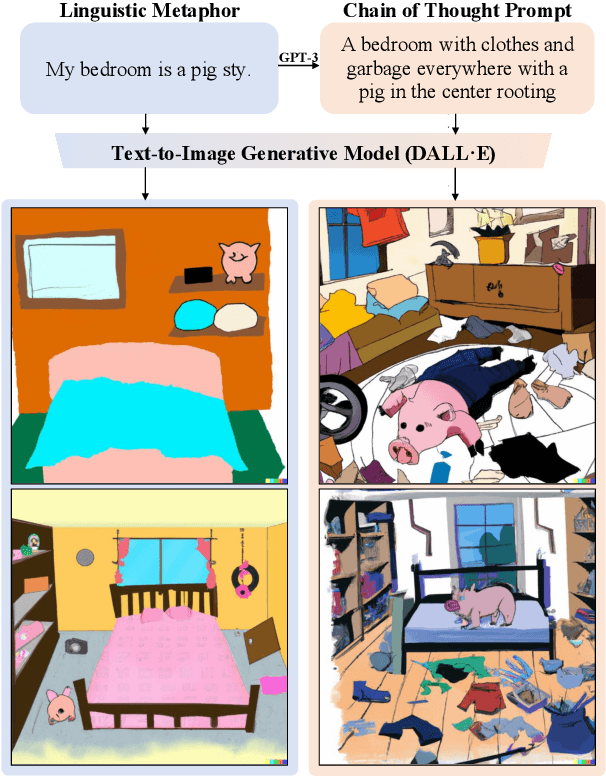

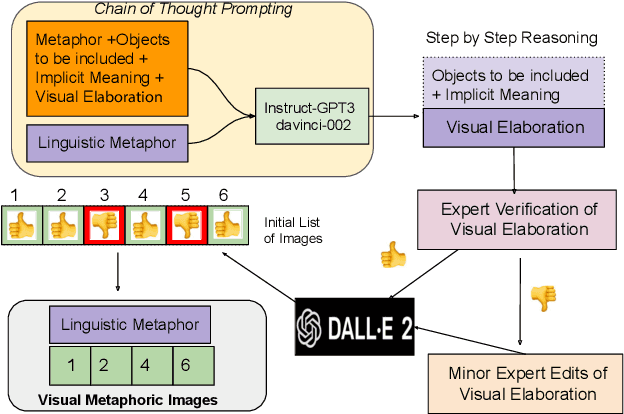

Visual metaphors are powerful rhetorical devices used to persuade or communicate creative ideas through images. Similar to linguistic metaphors, they convey meaning implicitly through symbolism and juxtaposition of the symbols. We propose a new task of generating visual metaphors from linguistic metaphors. This is a challenging task for diffusion-based text-to-image models, such as DALL$\cdot$E 2, since it requires the ability to model implicit meaning and compositionality. We propose to solve the task through the collaboration between Large Language Models (LLMs) and Diffusion Models: Instruct GPT-3 (davinci-002) with Chain-of-Thought prompting generates text that represents a visual elaboration of the linguistic metaphor containing the implicit meaning and relevant objects, which is then used as input to the diffusion-based text-to-image models.Using a human-AI collaboration framework, where humans interact both with the LLM and the top-performing diffusion model, we create a high-quality dataset containing 6,476 visual metaphors for 1,540 linguistic metaphors and their associated visual elaborations. Evaluation by professional illustrators shows the promise of LLM-Diffusion Model collaboration for this task.To evaluate the utility of our Human-AI collaboration framework and the quality of our dataset, we perform both an intrinsic human-based evaluation and an extrinsic evaluation using visual entailment as a downstream task.