 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-InstructBLIP: A Framework for aligning X-Modal instruction-aware representations to LLMs and Emergent Cross-modal Reasoning
Paper and Code
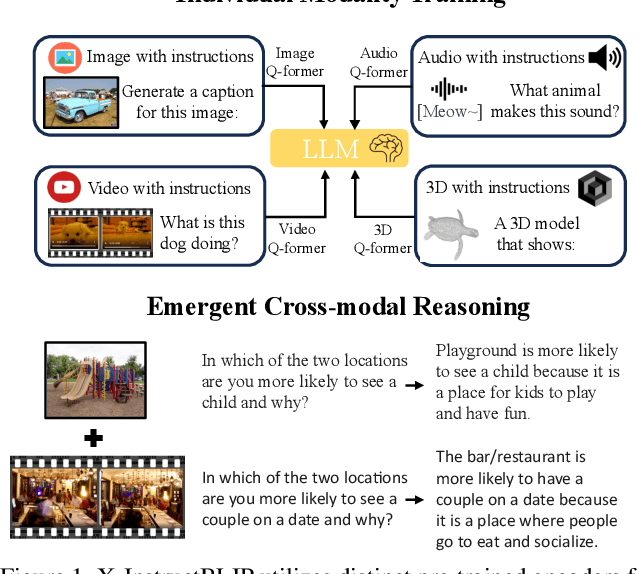


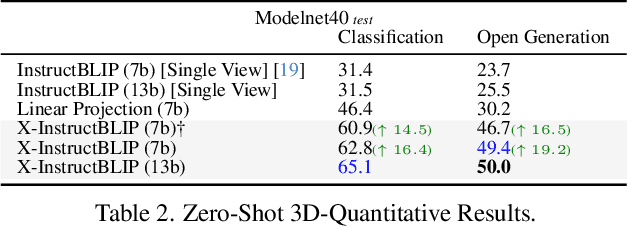
Vision-language pre-training and instruction tuning have demonstrated general-purpose capabilities in 2D visual reasoning tasks by aligning visual encoders with state-of-the-art large language models (LLMs). In this paper, we introduce a simple, yet effective, cross-modality framework built atop frozen LLMs that allows the integration of various modalities without extensive modality-specific customization. To facilitate instruction-modality fine-tuning, we collect high-quality instruction tuning data in an automatic and scalable manner, composed of 24K QA samples for audio and 250K QA samples for 3D. Leveraging instruction-aware representations, our model performs comparably with leading-edge counterparts without the need of extensive modality-specific pre-training or customization. Furthermore, our approach demonstrates cross-modal reasoning abilities across two or more input modalities, despite each modality projection being trained individually. To study the model's cross-modal abilities, we contribute a novel Discriminative Cross-modal Reasoning (DisCRn) evaluation task, comprising 9K audio-video QA samples and 28K image-3D QA samples that require the model to reason discriminatively across disparate input modalities.