 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Goal-Step Inference using wikiHow
Paper and Code
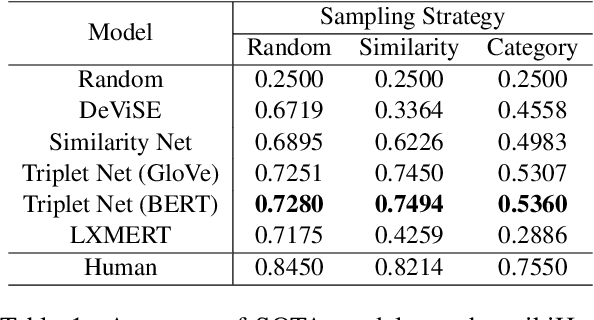
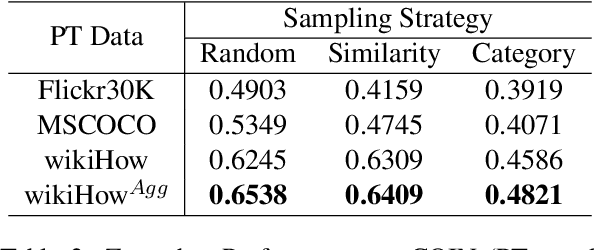
Procedural events can often be thought of as a high level goal composed of a sequence of steps. Inferring the sub-sequence of steps of a goal can help artificial intelligence systems reason about human activities. Past work in NLP has examined the task of goal-step inference for text. We introduce the visual analogue. We propose the Visual Goal-Step Inference (VGSI) task where a model is given a textual goal and must choose a plausible step towards that goal from among four candidate images. Our task is challenging for state-of-the-art muitimodal models. We introduce a novel dataset harvested from wikiHow that consists of 772,294 images representing human actions. We show that the knowledge learned from our data can effectively transfer to other datasets like HowTo100M, increasing the multiple-choice accuracy by 15% to 20%. Our task will facilitate multi-modal reasoning about procedural events.